本文经原作者授权转载,版权归原作者所有。原作者:AYi(@AYi_AInotes)。
有个细节我琢磨了好几天,OpenAI 给 GPT-5.3-Codex 下的官方定语很有意思,没有说是最强编程模型,而是一句有点耐人寻味的话——第一个对创造自身起到关键作用的模型。
我翻译一下:OpenAI 自己的工程师,已经在用 Codex 来造下一代 Codex 了。
我觉得这句话比任何 benchmark 都狠,它告诉我们,除了这个模型有多强,还有就是这个模型已经成了 OpenAI 自己的研发底盘。
也就是说2021 年那个被弃用的补全工具、去年那个帮你改 bug 的助手——跟现在这个比,根本不是一个物种。
我决定写一个系列,这是第一篇。
这篇不讲具体操作,先把全景图铺开:它的架构到底长什么样、核心能力在哪、跟 Claude Code / Cursor / Devin 比谁更能打、官方给的最佳实践有什么能直接抄。后面几篇再一个一个拆——AGENTS.md、Skills、MCP、多 Agent 编排的实操。
▸ 五个入口,一套配置——先搞懂这个,后面才不会晕
▸ 插件化 + MCP + Skills:这才是它跟别人拉开身位的地方
▸ 为什么我说它是目前最强执行引擎(附一张对比表,也说说它的软肋)
▸ 七条能直接抄的官方最佳实践
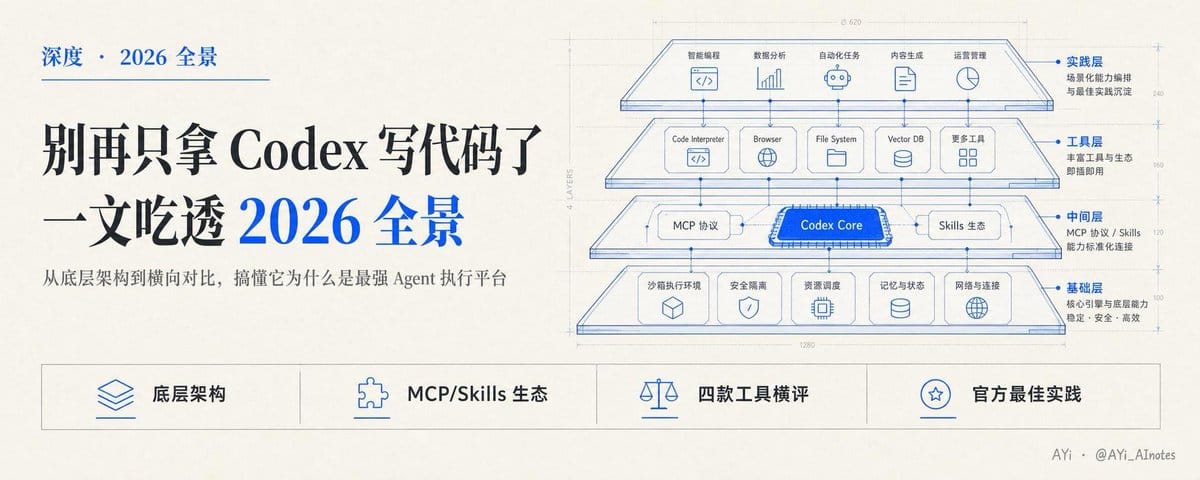
一、先搞懂架构——一套执行层,长了五张脸
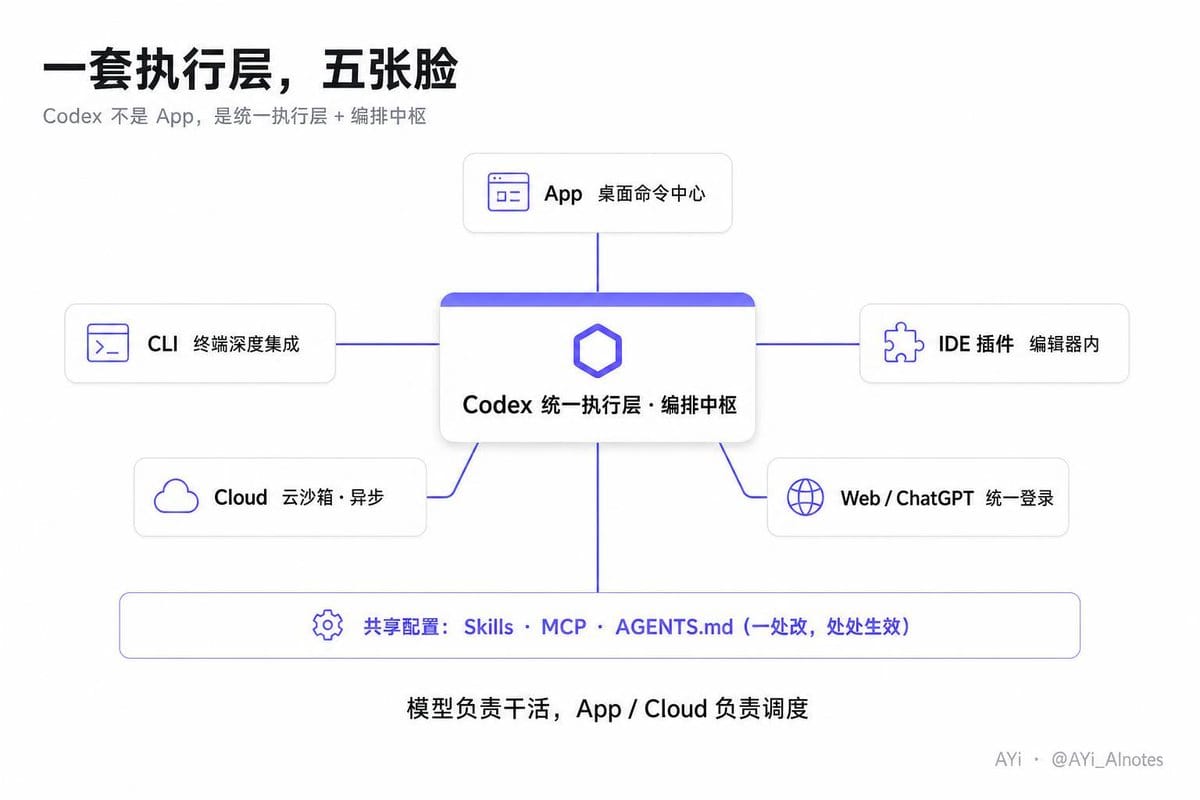
我第一次把 2026 版 Codex 的所有入口捋了一遍之后,才明白为什么很多人刚接触会懵,因为它同时出现在五个地方:App、CLI、IDE 插件、Cloud、Web。
所以这不只是五个产品那么简单,更像是是一套统一执行层 + 编排中枢,长了五张脸。
Codex App:桌面命令中心,macOS 版,今年最大的形态变化。
定位很明确——AI 编程的指挥中心,你可以在里面并行跑活、管长时任务、加 skills 和 automations、审查 diff,全程沙箱保安全。
为什么今年才出桌面端?OpenAI 自己的解释我挺认同的——2025 年 4 月 Codex 刚出的时候,问题还是“agent 能干什么”;
到了今年,模型能端到端处理复杂长时任务了,问题变成了“怎么同时管好一堆 agent”。
那问题变了,界面就得跟着变。
CLI + IDE 插件:
终端和编辑器里的深度集成,这里有一个细节我踩过一次坑才注意到——它们共用同一份配置,在一个表面改了 config,另一个表面立刻生效,不用各配一遍 MCP,很细节的一件事,但挺省心的。
Cloud Sandbox:异步执行的核心。长时任务、并行工作全挂云上,不占你本地资源,跑完进审查队列。
Web / ChatGPT 集成: 统一登录,所有表面共享 Skills、MCP 配置、AGENTS.md 记忆。
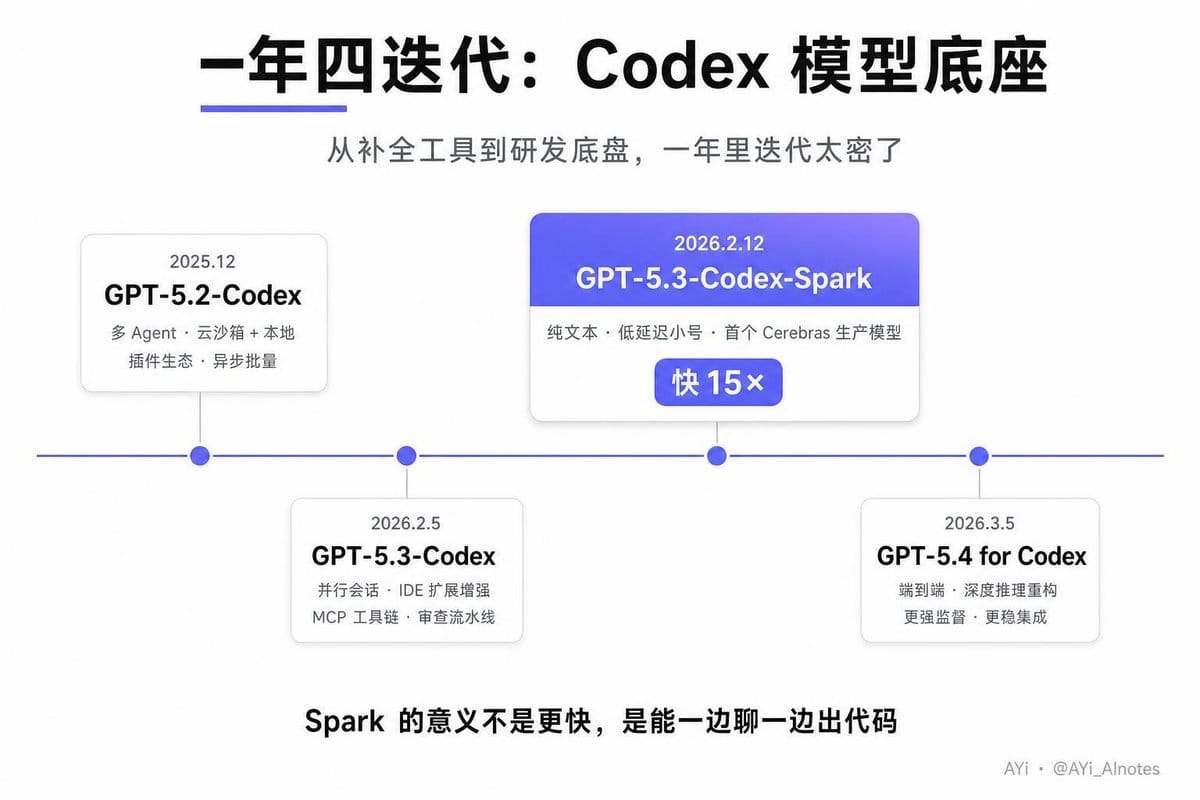
模型底座 :这条时间线值得看一眼,因为一年里迭代太密了:
2025 年 12 月 GPT-5.2-Codex → 2026 年 2 月 5 日 GPT-5.3-Codex → 2 月 12 日 GPT-5.3-Codex-Spark(纯文本、低延迟小号版) → 3 月 5 日 GPT-5.4 for Codex。其中 Spark 那步我特别想提一嘴——它是 OpenAI 第一个跑在 Cerebras 硬件上的生产模型,比早期 Codex 快 15 倍,专门为实时交互编码做的。这步棋的意义不是“更快了”,是“可以一边聊一边出代码了”。
把这五张脸看完,我的理解就一句话:Codex 把“模型”和“编排”分开了。
模型负责干活,App/Cloud 负责调度,
学 Codex,我理解本质上是在学怎么当一个管着好几个 agent 的项目经理。
二、插件化 + MCP + Skills——这三层才是真正的分水岭

光看模型能力,Codex 跟别家在一个量级。
真正让它跟传统工具拉开差距的,是它长成了一个可扩展、可复用、可编排的平台层,三层东西撑起来的。
MCP:把外部世界接进来
配置不复杂。每个 MCP 服务器在配置文件里一张 [mcp_servers.<server-name>] 表,支持两种传输——本地 STDIO 进程,或者远程 Streamable HTTP(走 HTTP 连远程,可选 OAuth 和 bearer token 认证)。
CLI 一行加一个。比如接 Context7(免费开发者文档 MCP),跑这个就行:codex mcp add context7 -- npx -y @upstash/context7-mcp。配置文件默认 ~/.codex/config.toml,想限定到某个项目用项目级的 .codex/config.toml——但只限受信任项目。
热门的有 GitHub、Figma、Playwright、Context7、Sentry 这些。
有一点我想强调,官方隐含了一个最佳实践:高频痛点优先接,别把线全布上。 MCP 接得越多,上下文消耗越大,风险面也越宽。够用就行,别贪。
Skills:把重复劳动变成能复用的东西
一个 skill 就是把指令、资源和可选脚本打个包,让 Codex 可靠地跑一个工作流。Skills 基于开放的 agent skills 标准。
本质就是一个目录,核心文件是 SKILL.md。可以加 agents/openai.yaml 配 UI 元数据、调用策略、工具依赖。
Skill 和 AGENTS.md 的分工,官方说得很清楚,这条特别值得记:每次对话都要发给模型的指令,放 AGENTS.md;只在特定操作时才需要的指令,放 SKILL.md。这个分离能让上下文更聚焦。
Plugins:把上面这些打成一个能分发的包
今年新出的一层,Codex plugins 是可复用的包,把 skills、app 连接器和 MCP 服务器捆成一个可安装单元。
官方的思路是这样:Skills 是创作格式,Plugins 是安装分发单元。你先用 skill 设计工作流,稳定了,再打包成 plugin 给别人装。
Codex CLI v0.117.0(2026 年 3 月 26 日)把 plugins 提成了一等工作流原语,首发了 20 多个一方集成:Slack、Figma、Notion、Gmail、Google Drive、Cloudflare 等。注意是 20+,不是网上传的 90+——别被夸大的数字带偏了。
这三层叠起来,才是 Codex 区别于“一个聊天框”的本质:你能把团队的最佳实践固化成标准,一键分给所有人。
三、为什么我说它是目前最强执行引擎——但也别神化
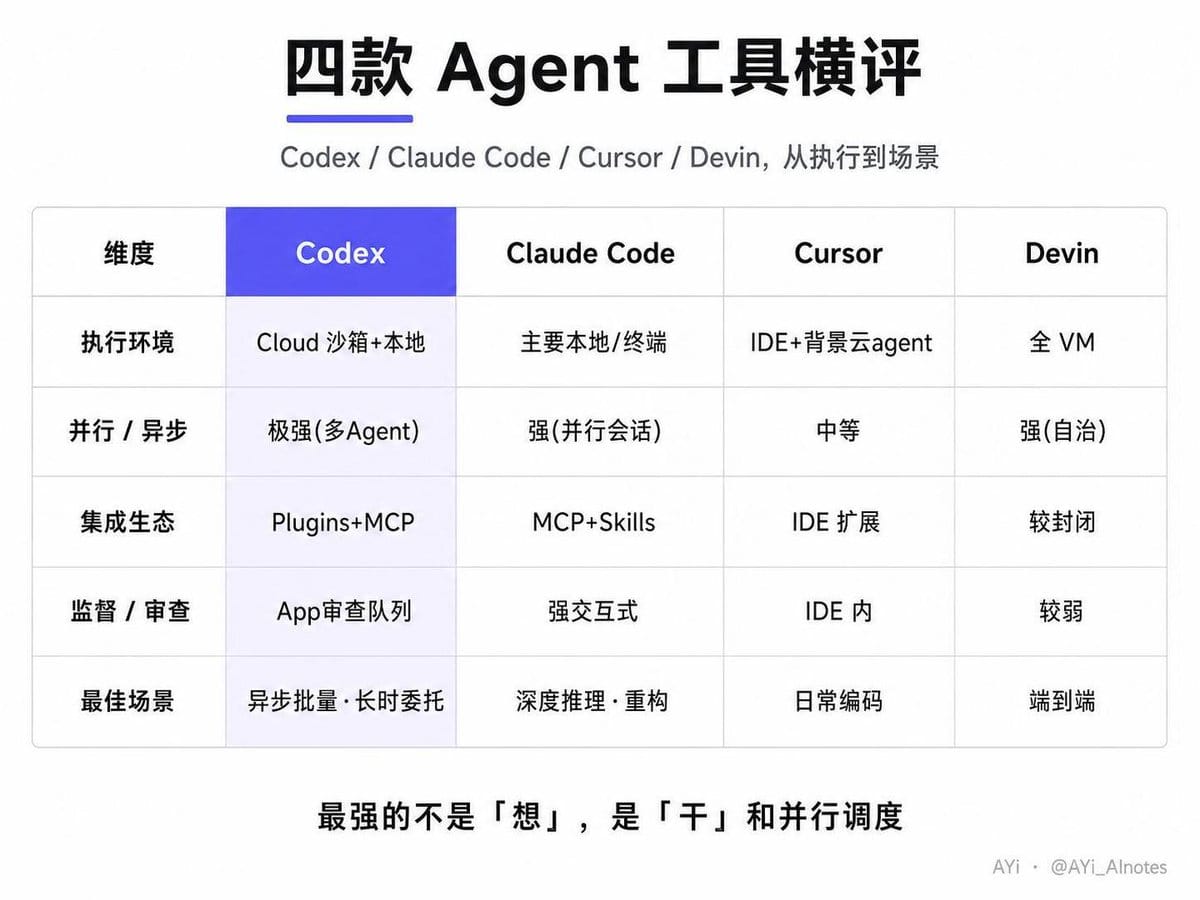
把 Codex 放到 Claude Code / Cursor / Devin 里横着看,它的优势我概括成五个词:云沙箱、异步委托、并行速度、生产力工具集成、审查执行分离。
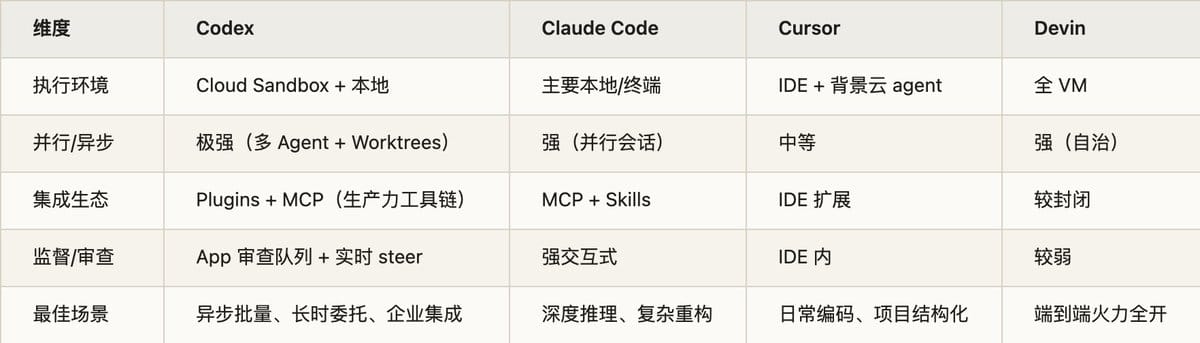
到这里你可能觉得我要开始吹 Codex 全面碾压了。
其实并不会,我得先泼点冷水,因为这篇不是软文,是干货。
Codex 还不是全面碾压,几件事得说清楚:
第一,SWE-Bench Pro 上它只是微弱领先
GPT-5.3-Codex 在 SWE-Bench Pro Public 上 56.8%,对比 5.2 的 56.4%——是守住了顶尖梯队,不是阶跃。真正大涨的是终端任务和电脑操作:新模型在 OSWorld-Verified 上几乎翻倍,SWE-Bench Pro 和 Terminal-Bench 都刷了新高。OSWorld 上人类水平大约 72%,它跑到 64.7%,已经很接近人了。
第二,对手没闲着
Anthropic 今年 3 月 24 日上了 macOS 桌面控制,OpenAI 三周后的 4 月 16 日才跟进。更值得注意的——4 月 14 日,OpenAI 发布前两天,Anthropic 抢先发了重新设计的 Claude Code 桌面 app,带并行会话和能通过 API 或 GitHub 事件触发的自动化 Routines。Claude Code 在 Opus 4.6 beta 上那 100 万 token 上下文窗口,在大型代码库推理和多文件重构上是实打实的优势。
所以我自己琢磨下来的判断是:Codex 最强的不是“想”,是“干”和“并行调度”。 它是目前最强的执行与异步编排引擎,但深度推理和超大上下文重构,Claude Code 仍有一手,最佳实践其实是混着用的,这点我会放到系列后面专门写一篇。
四、能直接抄的七条官方最佳实践
这部分含金量最高,全部来自 OpenAI 官方 best practices,我挑出七条能立刻上手的。

官方对 Codex 的定位有一句话,先记住:把 Codex 当成一个需要长期配置和打磨的队友,不是一个一次性助手。
1. Prompt 结构盯住四个东西:
Goal(目标)+ Context(上下文)+ Constraints(约束)+ Done-when(完成标准)。复杂任务先开 plan mode。
2. 用 AGENTS.md 固化“持久指令”
官方的思路很清楚:从正确的任务上下文开始,用 AGENTS.md 做持久指引,配 Codex 匹配你的工作流,MCP 连外部系统,重复工作变 skills,稳定工作流自动化。支持层级覆盖——全局放 ~/.codex/AGENTS.md,项目从根目录开始,越靠近当前目录优先级越高。
3. AGENTS.md 保持精简
这是新手最容易踩的坑。Codex 会把整个 AGENTS.md 加载进会话上下文,多余信息既浪费 token,又干扰结果。还有个反直觉的点:运行中改了 AGENTS.md,要重启或开新会话才会生效。
4. 别迷信自然语言约束
官方自己也很坦诚:这是自然语言,模型很擅长理解你的要求,但不保证一定遵守。要更硬的控制,用 config.toml、rules、sandboxing 和审批设置。社区实测也印证了——光靠 AGENTS.md 指令遵守率只有 25-40%,做成运行时 hook 强制执行能到 95%。真正危险的操作——生产部署、删库、改凭证——别指望 prompt,用 execpolicy 和沙箱权限从根上锁死。
5. 永远要求验证
让它写测试、跑 lint、用 /review。官方提了一个团队级的好模式:如果你和团队有 code_review.md 文件,在 AGENTS.md 里引用它,Codex 审查时也能照着那套指引走。
6. 推理档位别无脑拉满
官方推荐 medium 作为平衡智能和速度的全能档。Codex 能自主工作数小时搞最难的任务,最难的时候才用 high 或 xhigh。无脑拉满只会更慢更贵。
7. 形成闭环
把重复工作做成 Skill,稳定了打包成 Plugin 分发,事后复盘回写 AGENTS.md。这是一个 Kaizen 闭环——用得越久,你的 Codex 越懂你的项目。
写在最后
最近玩下来,我自己的感受是:2026 年的 Codex,最大的价值不是它又刷了几个 benchmark,是它真的把 agentic 编程从单点工具变成了可编排的平台层——云原生并行 + 插件化扩展 + 统一多表面 + 企业级集成。
我觉得它倒不是来取代 Claude Code 或 Cursor 的,
更准的说法是,它成了目前最强的执行与异步编排引擎。
Claude 的推理深度、Cursor 的 IDE 体验、Codex 的并行执行,三个其实是互补的。
但平台再强,也得你会用是吧,
所以这个系列接下来一篇一篇拆——下一篇从 AGENTS.md 开始,把“怎么写一个不浪费 token 又真能管住 agent 的指令文件”讲透。
这一篇先到这,有具体想先看哪块——MCP 实战配置、Skills 编写、多 Agent 编排、还是混合栈怎么搭——评论告诉我,我调后面顺序。