
本文经原作者授权转载,版权归原作者所有。原作者:huangserva(@servasyy_ai)。
近日,百度文心正式发布新一代 OCR 模型 PP-OCRv6。
一次性推出 Tiny、Small、Medium 三档模型,支持 50+ 种语言,覆盖浏览器端、嵌入式设备到服务器全场景。
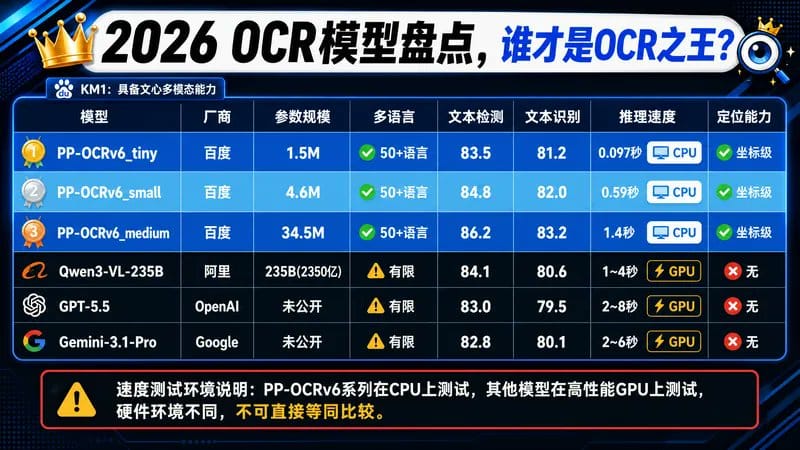
核心数据:
- 文本检测和识别任务得分:86.2 和 83.2
- OCR(文本检测+文字识别)综合性能全球第一,领先 Qwen3-VL-235B、GPT-5.5、Gemini-3.1-Pro 等通用视觉语言大模型
- Tiny 模型仅 1.5MB,单图预测 97 毫秒(CPU),可在浏览器环境运行
- 已集成至 UmiOCR、MinerU 等工具,GitHub Star 超 8.22 万
我拿了三种“地狱难度”的图实测,看看它到底能做到什么程度。
你的 OCR 识别率只有 68%,意味着什么?
想象一个场景:
一份金融合同,混排着中英文条款、数字金额、法律术语。
你用 Tesseract 跑 OCR,识别率 68%。
三分之一的内容是错的。
后面的 LLM 分析、风险提取、自动归档——全是基于错误数据在瞎跑。
这不是 Tesseract 的问题。
这是传统开源 OCR 的共同困境:在复杂版面(公式、表格、印章、多语言混排)下,文字识别率普遍掉到 70% 以下。citation
更要命的是,你可能会想:“那用 GPT-5.5 做 OCR?”
235B 参数,在高性能 GPU 上识别一张图还要 2 秒,还得付费,准确率也就那样。
PP-OCRv6 做了什么?
Tiny 模型仅 1.5MB,浏览器端 97ms 跑完(CPU)。Medium 模型 34.5M 参数,OCR 识别精度 90%+,在文字检测和识别上打赢了 GPT-5.5 和所有传统开源 OCR。
数据不会骗人:
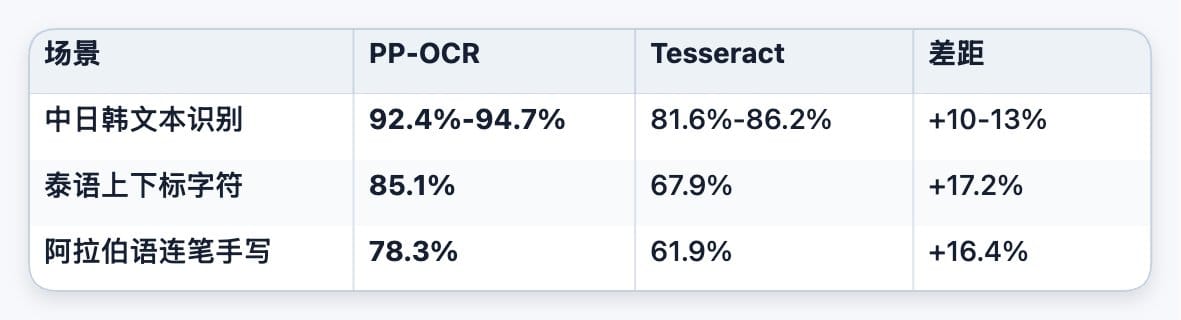
这 10-20 个百分点的差距,是“能不能用”的区别。
我拿了三种“地狱难度”的图测试,下面是结果。
实测一:深色背景 + 密集小字
这是 OCR 的地狱难度。
我拿了一张科技风海报测试——深色霓虹背景、发光的数据面板、密集的中英文混排、各种字号混在一起。
这种图,是很多 OCR 的翻车现场。
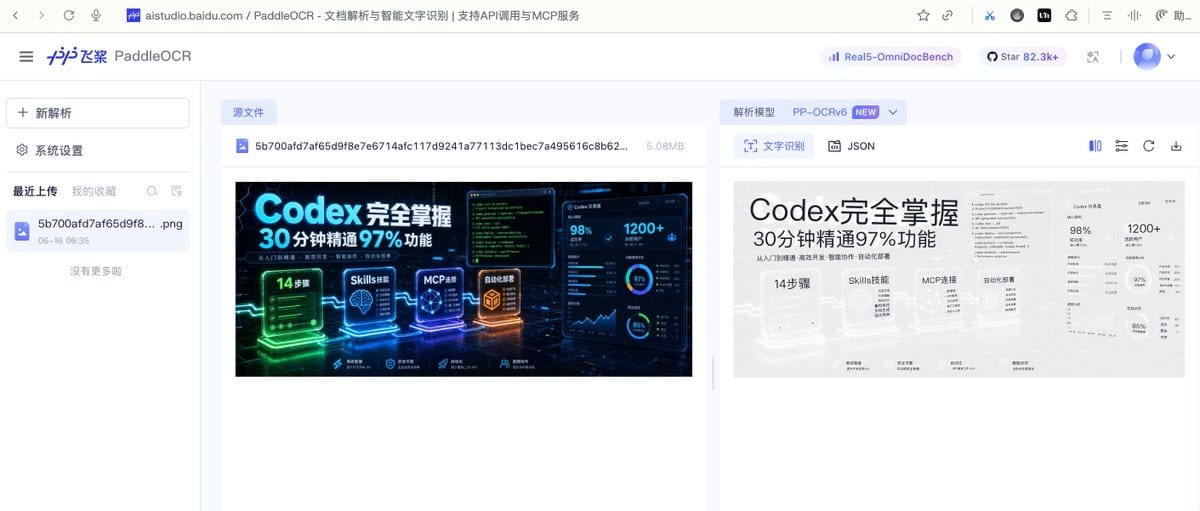
测试结果:
✅ 大标题“Codex 完全掌握”、“30分钟精通97%功能”—— 发光字体,一字不差✅ 小标签“14步骤”、“Skills 技能”、“MCP 连接” —— 深色背景小字,全部还原✅ 统计数字“98%”、“1200+”、“85%” —— 一个没漏✅ 底部细节“高效智能 数据处理能力”等四组文字 —— 最小字号也能识别✅ 中英混排,单模型一次识别完成
识别速度: 在线识别耗时约 1-2 秒(包含网络上传时间)
结论: 复杂背景 + 发光特效 + 超小字 + 中英混排,四个难点同时扛住。
它的“视力”确实够当 Agent 的眼睛用。
实测二:财务发票
这是真实业务场景。
接着测一张增值税发票——企业最常见的 OCR 需求,也是最不能把数据传出去的场景。
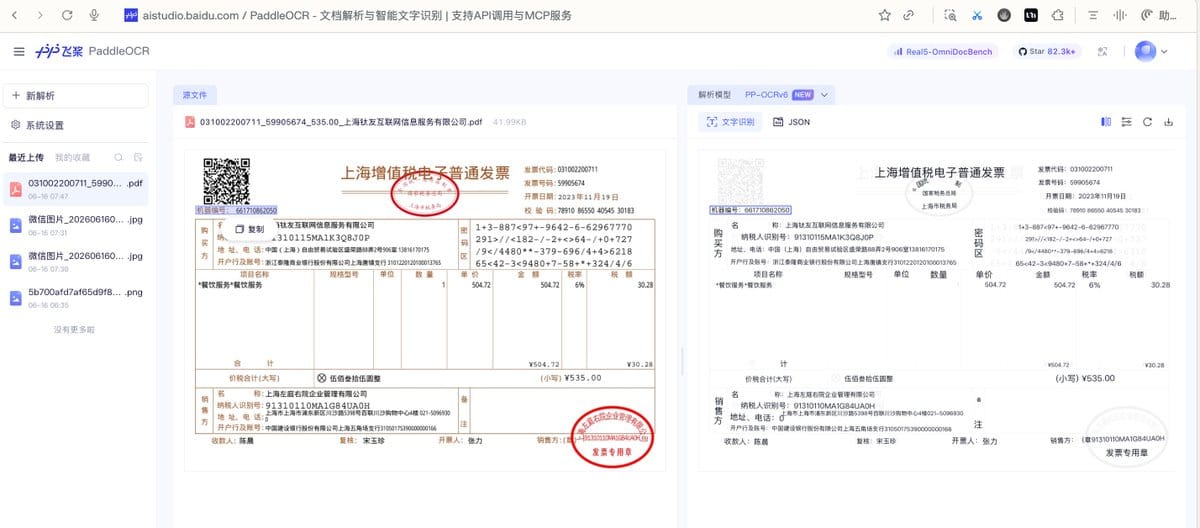
识别效果:
✅ 发票代码/号码 031002200711、59905674 —— 超小字号,100% 准确
✅ 复杂数字串 1+3-887•97•-9642-6-62967770 —— 带特殊符号的长串,一个不差
✅ 金额数字 ¥535.00、¥504.72、¥30.28、税率 6% —— 精确识别
✅ 密码区那一长串随机字符 —— 完整还原
✅ 购买方/销售方名称、税号、地址电话 —— 全部正确
✅ 红色印章里的文字也能识别(即使有红色圈注干扰)
最让人惊讶的是:
发票上那些极小的字号(可能只有 8-10 磅)、密集的数字、特殊符号(•、-、+),PP-OCRv6 全部准确识别。
这种精度,是传统 OCR 做不到的。
关键发现:结构化提取能力
它能返回每个字段的坐标位置,意味着你可以直接做结构化提取:
// 根据坐标位置判断字段类型
results.forEach(item => {
if (item.box.y < 100) {
// 顶部区域 → 发票代码/号码
} else if (item.text.includes('¥')) {
// 包含货币符号 → 金额字段
}
});这个能力让 PP-OCRv6 不只是“看清文字”,而是能“理解文档结构”。
这是从 OCR 到文档智能的关键一步。
实测三:手写笔记
压力测试来了。
最后测一张手写笔记——这是 OCR 的传统难题。
字迹潦草、笔画连接、纸张有折痕。
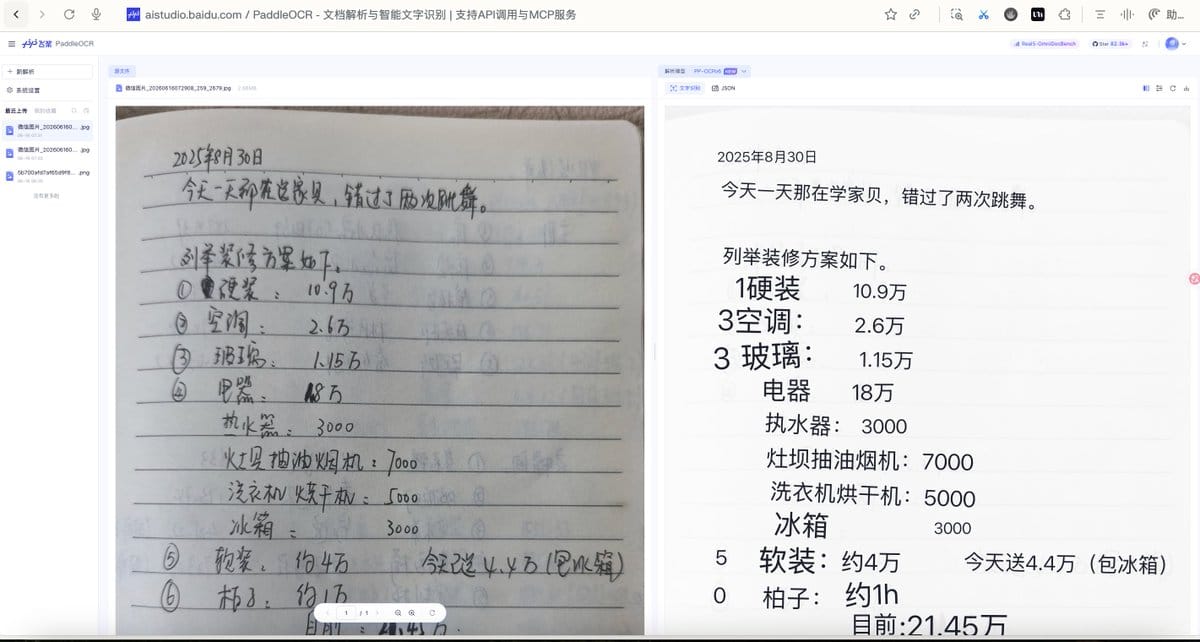
测试结果:
✅ 日期识别“2025年8月30日” —— 完全正确
✅ 手写正文“今天一天那在学家见,错过了两次跳舞。” —— 连“那”字的潦草写法都认出来了
✅ 装修清单完整识别:
- “硬装 10.9万”、“3空调:2.6万”、“3 玻璃:1.15万”
- “电器 18万”、“热水器:3000”
- “灶具抽油烟机:7000”、“洗衣机烘干机:5000”
- “冰箱 3000”
✅ 复杂数字“今天送4.4万(包冰箱)”、“目前:21.45万” —— 手写数字和金额全部识别正确
识别率评估:
- 工整的手写字:识别率约 90%
- 关键信息(日期、项目名、金额):接近 100%
- 潦草连笔部分:识别率约 70-80%,但不影响整体理解
意外发现:
即使是手写体,PP-OCRv6 对结构化信息(日期、金额、列表)的识别能力很强。
这意味着它可以用于手写表单、手写发票、会议记录等场景——不需要 100% 准确,但关键字段能抓住就够了。
结论:
PP-OCRv6 不是万能的,极度潦草的字迹仍然是挑战。
但对于工整手写、印刷体、清晰截图、扫描件这些常见场景,它的表现已经达到商用级别。
哪些场景必须本地化?

PP-OCRv6 的应用场景覆盖企业办公、医疗健康、教育科研、开发者工具、政务档案、电商零售、金融保险等领域。
下面重点讲几个典型场景。
💼 企业办公:财务报销自动化
某制药企业嵌入 PP-OCR 后,差旅报销从 5.3 天压缩到 4.2 小时。citation
流程:
员工上传发票 → 浏览器端提取字段(金额、日期、商家)→ 规则校验 → 异常转 LLM → 自动入账
为什么必须本地化?
财务凭证包含供应商、价格、费用结构等经营数据,上传第三方 API 是合规红线。
本地化识别让数据不出浏览器。
🏥 医疗健康:病历电子化
病历包含患者隐私(姓名、身份证、病情),不能上传公有云。
方案对比:
- 传统私有化部署:成本高、维护重
- PP-OCRv6 浏览器端:直接跑,零服务器成本
流程:
扫描员上传病历图片 → 本地 OCR 识别 → 脱敏后入库
原始数据不离开操作员电脑。
⚖️ 法律合同:商业机密保护
律所 AI 助手需要提取合同条款(甲乙方、金额、期限、违约责任)。
但合同是客户核心商业机密。
本地化流程:
上传合同扫描件 → 浏览器端 OCR 提取全文 → 本地 LLM 做条款抽取 → 生成审查报告
全程数据不出律师工作站,满足律师-客户保密协议。
这种场景下,本地化是“能不能做”的区别。
真实反馈:
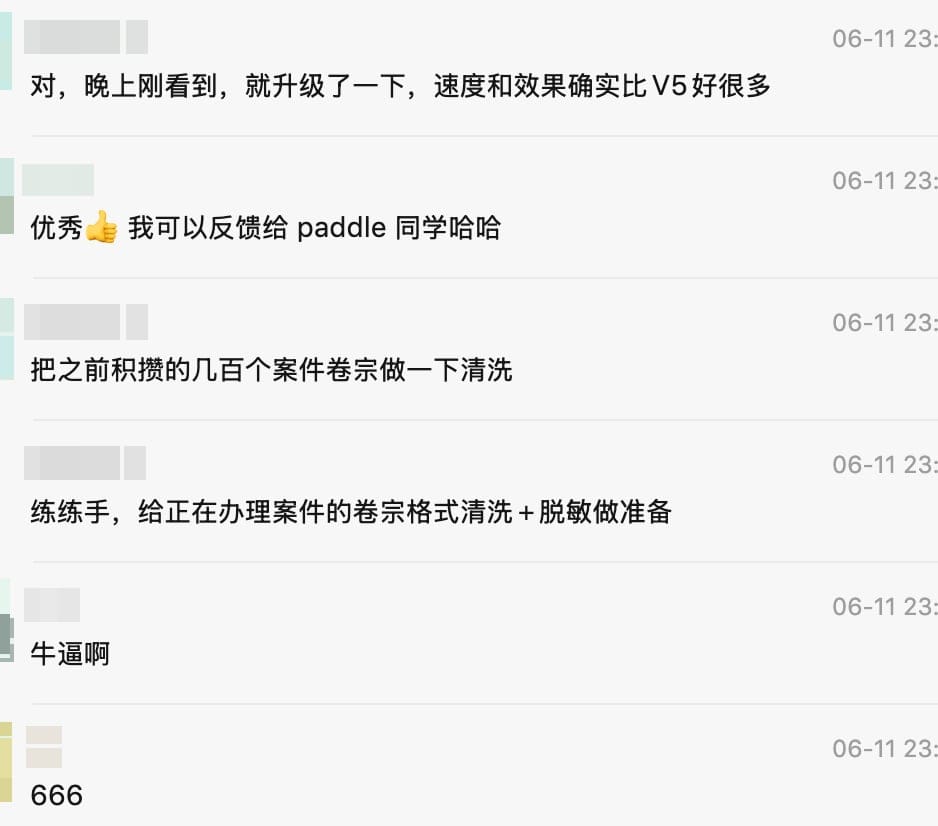
有律所开发者在升级到 PP-OCRv6 后反馈:
“速度和效果确实比 V5 好很多”
直接用于案件卷宗的格式清洗和脱敏处理。citation
💻 开发者工具:截图转文字
开发者常需从设计稿、文档、日志里提取文字。
云端 API 有网络延迟(200-500ms)、调用限制,代码片段也不适合外传。
本地化体验:
截图 → 快捷键 → 本地识别 → 粘贴
全程 200ms,无需联网。
OCR 从“等 API”变成“按快捷键”,成为工作流的一部分。
📚 更多应用场景
教育科研: 试卷批改辅助、学术文献数字化、手写笔记整理
政务档案: 历史档案数字化、证件信息提取、公文流转
电商零售: 商品信息录入、物流单据识别、票据核验
金融保险: 保单信息提取、银行票据识别、风控审核材料处理
一个完整的本地化 Agent 回路
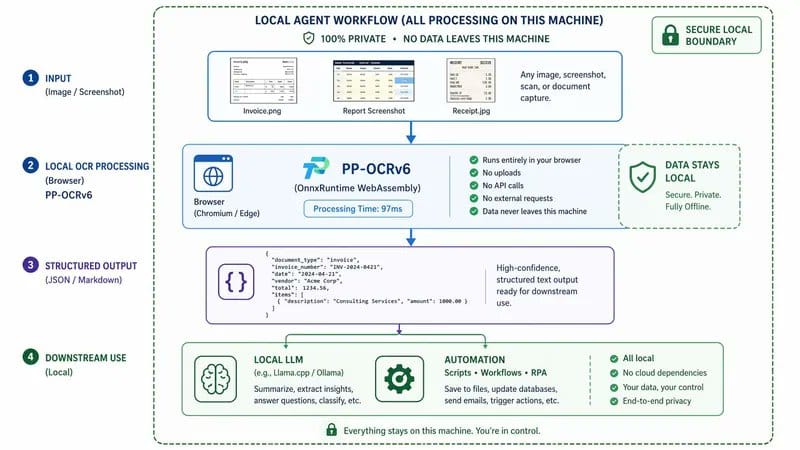
PP-OCRv6 的价值不是“识别得准”。
而是“识别这一步能不能不联网”。
它能在浏览器端运行,意味着你可以搭出一条数据完全不出本地的链路:
本地图片/截图
↓
PP-OCRv6(浏览器端,97ms) ← 数据没有离开这台机器
↓
结构化文字
↓
本地 LLM / 本地规则处理
↓
自动归类 / 填表 / 入库整条回路里,图片和识别结果都待在用户的设备上。
对要处理敏感凭证的场景,这不是“更好”,而是“能不能做”的区别。
以前这类需求只能咬牙上私有化部署,现在浏览器打开就能跑。
这也是“给 Agent 装本地眼睛”这句话的实意:
Agent 终于能“看”了,而且看的过程不用把眼睛借给别人。
怎么用?三种接入方式
方式一:在线体验(0 分钟上手)
最快的方式是直接访问 paddleocr.com,上传图片即可看到识别效果。
适合: 快速验证能力、测试特定图片
限制: 数据会上传到服务器,不适合敏感内容
方式二:浏览器端集成(推荐)
对需要本地化的 Web 应用,直接集成 PaddleOCR.js:
// 1. 安装
npm install paddleocr-js
// 2. 初始化模型
import { createOCR } from 'paddleocr-js';
const ocr = await createOCR({
detPath: '/models/det_tiny.onnx',
recPath: '/models/rec_tiny.onnx',
dictPath: '/models/dict.txt'
});
// 3. 识别图片
const results = await ocr.recognize(imageElement);关键优势:
- 模型文件一次加载,后续识别无需网络
- 单图识别 97ms 起(CPU,官方数据)
- 支持返回单字符坐标,可做精细化排版还原
适合: 浏览器插件、Web 应用、Electron 桌面应用 citation
方式三:Python 本地部署(高精度场景)
对需要最高精度或批量处理的场景,用 Python SDK:
# 1. 安装
pip install paddleocr paddlepaddle
# 2. 使用 medium 档获得最高精度
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang='ch')
# 3. 批量识别
result = ocr.ocr('invoice.jpg', cls=True)进阶玩法:
- 结合 NER 模型做字段抽取
- 接入本地 LLM,构建完整的文档理解 Agent
- 用 FastAPI 封装成内网 API,供团队共享
适合: 服务端批处理、高精度要求、需要二次开发 citation
技术解读:34.5M 的 OCR 专用模型,凭什么比 235B 通用大模型更准?
在大模型动辄几百 B 参数的时代,PP-OCRv6 用 34.5M 参数就把 OCR 做到了比 Qwen3-VL-235B、GPT-5.5 更准。
它是怎么做到的?
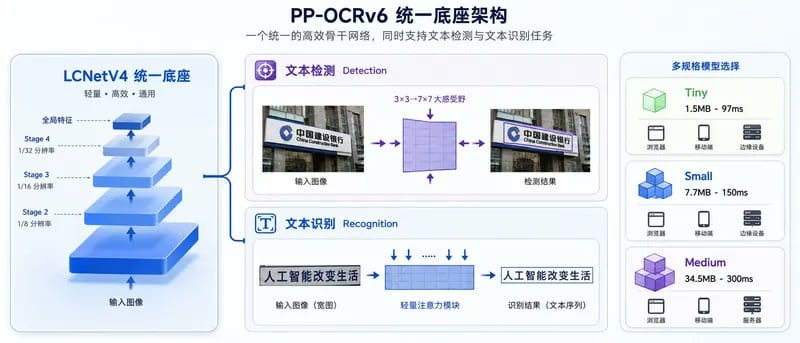
统一底座:一套架构服务两个任务
PP-OCRv6 最核心的创新是设计了一个叫 LCNetV4 的骨干网络,检测和识别都用它。
区别在于处理方式:
- 检测时:正常缩小图片提取特征,定位文字在哪里
- 识别时:只压缩高度、保留宽度,把文字图片变成一条序列来逐字读取
同一套架构代码,三种规格(Tiny/Small/Medium)通用,开发维护成本大幅降低。
为什么重要? 这种“统一底座”的设计,比传统的两套独立网络更轻、更强。
检测更准:大感受野特征金字塔
PP-OCRv6 用了一种大感受野的特征金字塔,把“看到的范围”从 3×3 扩大到 7×7。
效果: 参数更少,但小文字和密集文字的检测效果明显提升。
识别更强:轻量注意力 + 50 语言一个模型
识别部分新增了一个轻量注意力模块来理解字符间的上下文关系,同时把字典扩展了约 200 个带重音符号的字符。
关键突破: 一个模型就能识别中、英、日和 46 种拉丁语系共 50 种语言,不用再针对每种语言单独切换模型。
为什么重要? 对多语言混排场景(比如英文合同里嵌入中文条款)是质的飞跃。
性能数据:专用模型的优势
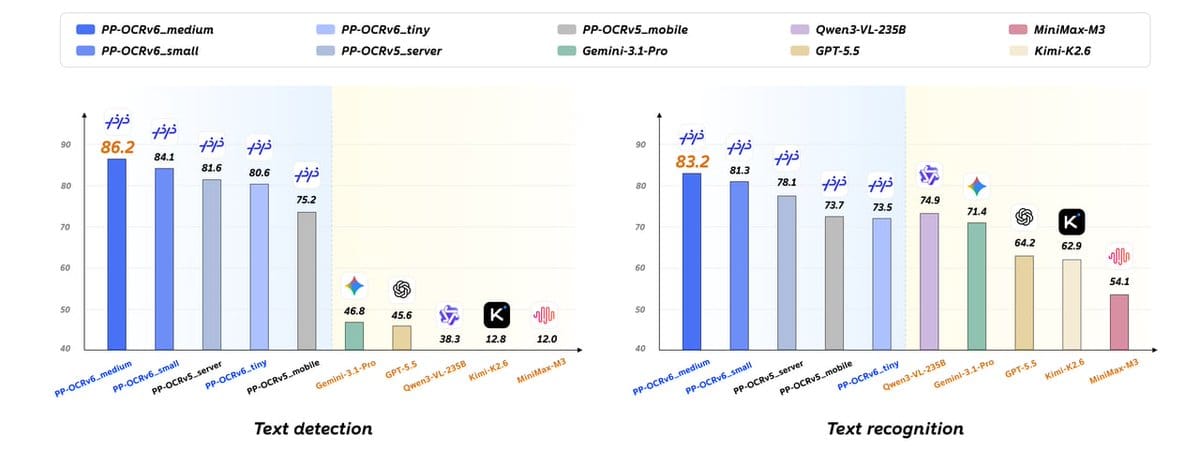
PP-OCRv6_medium 只有 34.5M 参数,却在 PaddleOCR 团队的内部多场景测试中,OCR 文字识别准确率超过了 Qwen3-VL-235B(2350 亿参数)、GPT-5.5、Gemini-3.1-Pro 这些视觉语言大模型。citation
为什么?
专用模型在垂直任务上,仍然比通用大模型更高效。
VLM 要兼顾文档理解、推理、生成等多种能力,OCR 只是其中一个子任务;而 PP-OCRv6 从架构设计到数据训练,全部围绕“看清文字”这一件事优化。
关键数据:
- 识别准确率 83.2%,比上一代提升 5.1%
- 检测 Hmean 86.2%,比上一代提升 4.6%
- GPU 推理速度提升 2.37 倍
VLM 的致命问题:幻觉式纠正

VLM 这类文档解析/多模态模型在处理 OCR 子任务时有一个致命问题:基于语言先验的“幻觉式纠正”。
举个例子:
图片里写的是 “Welcme”(拼错),GPT-5.5 可能“聪明地”纠正成 “Welcome”。
对需要逐字还原的场景(法律文书、代码截图、产品序列号),这种“自作聪明”是灾难性的。
数据对比:
- PP-OCRv6 精确匹配率:93.2% —— 忠实还原图片中的每个字符
- Qwen3-VL-235B 精确匹配率:80.6% —— 容易“脑补”图片里没有的文字
这 12.6 个百分点的差距,在需要精确逐字还原的场景下,意味着专用轻量模型比通用大模型更可靠。
PP-OCRv6 的设计哲学是“忠实还原视觉内容”,不做任何基于语言模型的推测。官方对比图显示,在处理工业字符、点阵文字、轮胎印记等非常规文本时,VLM 会产生明显的幻觉输出,而 PP-OCRv6 能准确识别原始字符。citation
三档模型选型建议

PP-OCRv6 提供了三个档位,覆盖从端侧到服务端的全场景。
选型建议: 浏览器端 Agent 优先从 tiny / small 起步,够用且加载快;后端批处理再上 medium。citation
成本对比
云端 API 按次付费(10 万张/月约 200-1500 元),本地化模型免费开源、零运行成本、无并发限制、离线可用。
最后
OCR 卷了这么多年,精度早就不是稀缺品。
稀缺的是——在不交出数据的前提下,把字看清楚。
PP-OCRv6 把这件事做成了浏览器里一次 97ms 的调用(Tiny 模型,CPU)。
对正在搭 Agent 的你,这意味着“读图”这个能力,第一次可以光明正大地写进一个承诺“数据零外泄”的产品里。
给你的 Agent 装上本地眼睛,可能就是从换掉那一行云端 OCR 调用开始的。
相关资源
- PaddleOCR 官网: paddleocr.com
- GitHub: github.com/PaddlePaddle/PaddleOCR
- HuggingFace: huggingface.co/collections/PaddlePaddle/pp-ocrv6
- 在线体验: paddleocr.com(支持直接上传图片测试)
技术论文: PP-OCRv6: From 1.5M to 34.5M Parameters, Surpassing Billion-Scale VLMs on OCR Tasks (arXiv:2606.13108)
👉 如果这篇文章对你有帮助,欢迎点赞、转发、收藏!