本文经原作者授权转载,版权归原作者所有。原作者:dontbesilent(@dontbesilent)。
dbskill 更新 | 为什么把内容讲得越透彻,流量反而越少
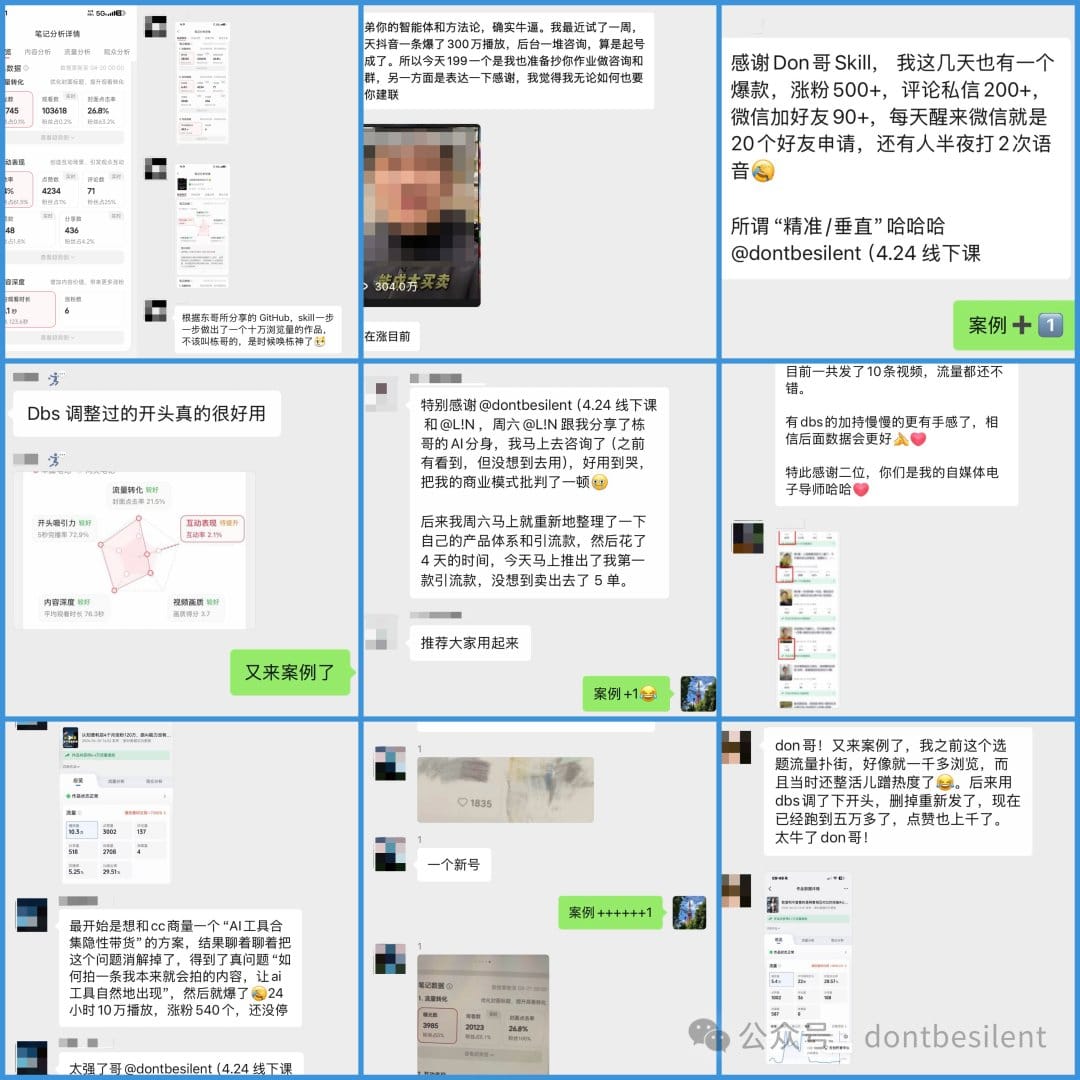
dbskill 在 GitHub 已经有 7000 个 star,这套工具帮很多人解决了内容有深度但没流量的问题
这次新增了两个工具,处理这件事的两个阶段
我一直有个习惯:搞清楚一件事,再把它讲清楚
这在大多数时候是对的,但有一个问题——搞清楚之后,你很容易讲得太清楚。知识的密度上去了,大家的耐心跟不上了。在传播上,完整不等于专业,有时候反而是相反的
我用 /dbs-chatroom 聊天室工具一段时间之后,发现这个问题会被它放大。聊天室从多个角度让不同专家交锋,把一个问题说得很细。说完,你去写文稿,写出来的东西信息量很足,但没有流量
为了修正这件事,我做了两个独立的工具,给聊天室做前后挂载
dbskill 新增两个 skill:
/dbs-spread /dbs-resonate
/dbs-spread:传播心理解码。给定一段内容,用 5 个传播学理论分析它为什么能打动人,找出有效立场和情绪来源,给出聊天室的讨论方向
/dbs-resonate:文稿共鸣诊断。你写完了一段内容但心里没底,把文稿交给它,它找出最大的问题,给出具体的删改建议
为什么做这两个工具
先说 /dbs-spread 的来源
我经常看到别人的内容火了,但讲得不好——信息量不足,观点也没什么深度,就是能引起反应。同类型的内容里,深度更高的那条反而没什么流量
这里有一个可以分析的机制:内容能不能传播,和它的知识深度关系不大,和它有没有说出大家憋着没说的那句话关系更大。「沉默的螺旋」、「使用与满足理论」这些经典传播学理论,讲的就是这件事
这些理论提出的时候,抖音还没有出现,做内容的我们大多数还没有出生。拉扎斯菲尔德的两级传播理论是 1944 年,卡茨的使用与满足理论是 1959 年,诺依曼的沉默的螺旋是 1974 年。这几位作者已经去世了。他们研究的不是平台,是人在接收和传递信息时的心理机制——这个机制和抖音算法无关
做 /dbs-spread 的目的不是去学那条火的内容怎么写,而是在用聊天室深挖之前,先搞清楚这个话题触动了什么情绪,然后把聊天室的讨论方向对准那里。知识还是我的知识,但走的是顺着大家已有情绪的路
/dbs-resonate 解决的是另一个问题:聊天室出来的内容往往很发散,你再把它整理成文稿,很容易写成同时在讲五件事。每件事都讲到了,但没有一件事说清楚。看的人记不住你在说什么
/dbs-resonate 的诊断从提取文稿里所有主张开始——找出哪一个才是真正的核心,其他的是不是在稀释它。然后用同样 5 个传播学维度逐一过一遍,给出具体要删什么、保留什么、强化什么
它们怎么和聊天室配合
一个典型的使用顺序:
- 看到一条爆火内容,觉得可以做类似的话题
- 用 /dbs-spread 分析那条内容的传播心理,拿到情绪来源和讨论方向
- 带着这个方向,开 /dbs-chatroom 深挖,把内容的知识结构聊清楚
- 写文稿
- 用 /dbs-resonate 看文稿能不能打动人,哪里需要收缩
但这两个工具并不捆绑聊天室,也可以单独使用
/dbs-spread 可以单独用于分析任何已发布的内容,不管你接下来是不是要开聊天室
/dbs-resonate 可以接任何来源的文稿——无论是你自己写的、录音整理的,还是聊天室出来的
它们分别能做什么
/dbs-spread 输出五个维度的分析,每个维度一句判断加一句依据,然后推导出情绪来源、有效立场、还可以往哪里讲,以及给聊天室的讨论方向
有两件事它不做:不预测内容会不会火,不评价内容好不好。预测算法表现取决于开头质量、封面、内容时长,这些是 /dbs-hook 和 /全平台标题 的范围,不是传播心理的范围
/dbs-resonate 先列出文稿里所有主张,再确认哪个是核心、哪些在稀释它,然后逐维度诊断,最后给改法,并写出「改完之后的骨架应该是什么」
它也不做的事情:不预测完播率,不检查结构是否完整,不分析已验证的内容(那是 /dbs-spread 的工作)
如何更新
npx -y skills add dontbesilent2025/dbskill -g --all
GitHub:
https://github.com/dontbesilent2025/dbskill