
本文经原作者授权转载,版权归原作者所有。原作者:Berryxia.AI(@berryxia)。
申明:本文是AI与人类协作完成,如有不适,请关闭退出,请悉知。
Vivek Nair 那篇“How to Be Good at Research?“据称爆了520万阅读,中文圈被前通义千问负责人林俊旸一转,更是刷屏。收藏、转发、摘录金句,一条龙。
但这里有个讽刺:Vivek 在文章里说,大多数人学到的不是“怎么做研究”,仅仅是“怎么看起来像在做研究”。
而520万人读完,觉得自己“学到了”然后继续刷下一条,这本身,就是“看起来像研究者”的最隐蔽形态。
读研究方法论文章,和做研究,是两件事。
这个区分听起来像废话,但 Vivek 整篇文章的爆发力就藏在这句废话里:2026年的 AI 从业者,比任何群体都更需要有人把这层窗户纸捅破。
你以为自己在研究,其实在抄作业!
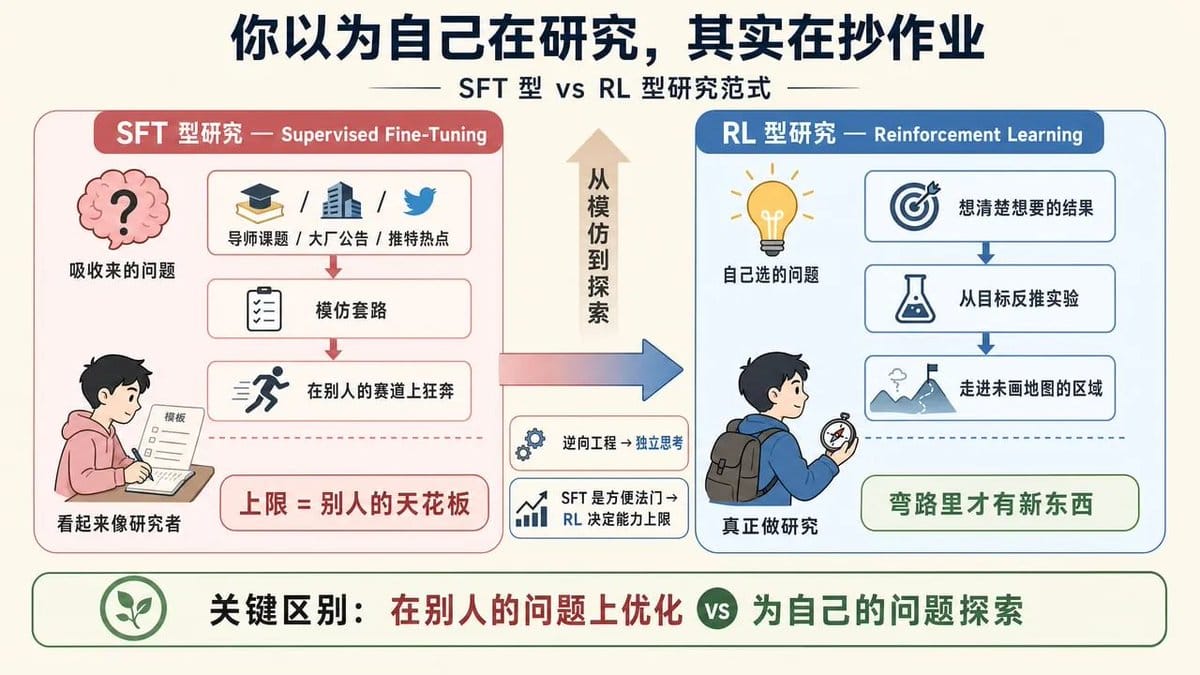
Vivek 的表达非常清晰的观点:大多数人“逆向工程了这份工作”,从能看见的东西(论文、公告、推文)反推研究者该干什么,结果学到的是“怎么看起来像研究者”,而不是“怎么真正做研究”。
这个还是有点扎心的啊~兄弟们。
这话放在任何行业都成立,但在 AI 行业尤其致命。因为 AI 行业的信息消费方式,恰好是“逆向工程”的完美温床。
万维钢老师用过一个框架,把人才分成两类:SFT 型和 RL 型。
SFT(Supervised Fine-Tuning,监督微调)型靠模仿套路,给什么样本学什么样本。
RL(Reinforcement Learning,强化学习)型在真实世界里自己摸爬滚打,从反馈中修正策略。
他的判断很干脆:SFT 是方便法门,RL 决定能力上限。
Vivek 说的“吸收来的问题”,就是 SFT 型研究。
你的研究方向来自导师的课题、大厂上个季度的公告、推特上这周最火的论文。你知道某个方向重要,但不知道为什么重要、什么情况下会不重要。当别人转向的时候,你晚一年才知道。
而“自己选的问题”,是 RL 型研究。
你先想清楚一个你真正想让它存在的结果,再反推需要什么实验。
Schulman 把这概括为从目标出发的推理,他说这种方式天然制造原创性,因为你的具体问题不会出现在任何综述论文里,写综述的人没有你的问题。
关键区别在哪?
SFT 型研究者在别人的问题上优化,RL 型研究者为自己的问题探索。前者可以很高效,但上限是别人的天花板。后者经常走弯路,但弯路里才有新东西。
你的信息流,正在替你选题。
问题来了:知道 RL 型更好,为什么大多数人还是走 SFT?
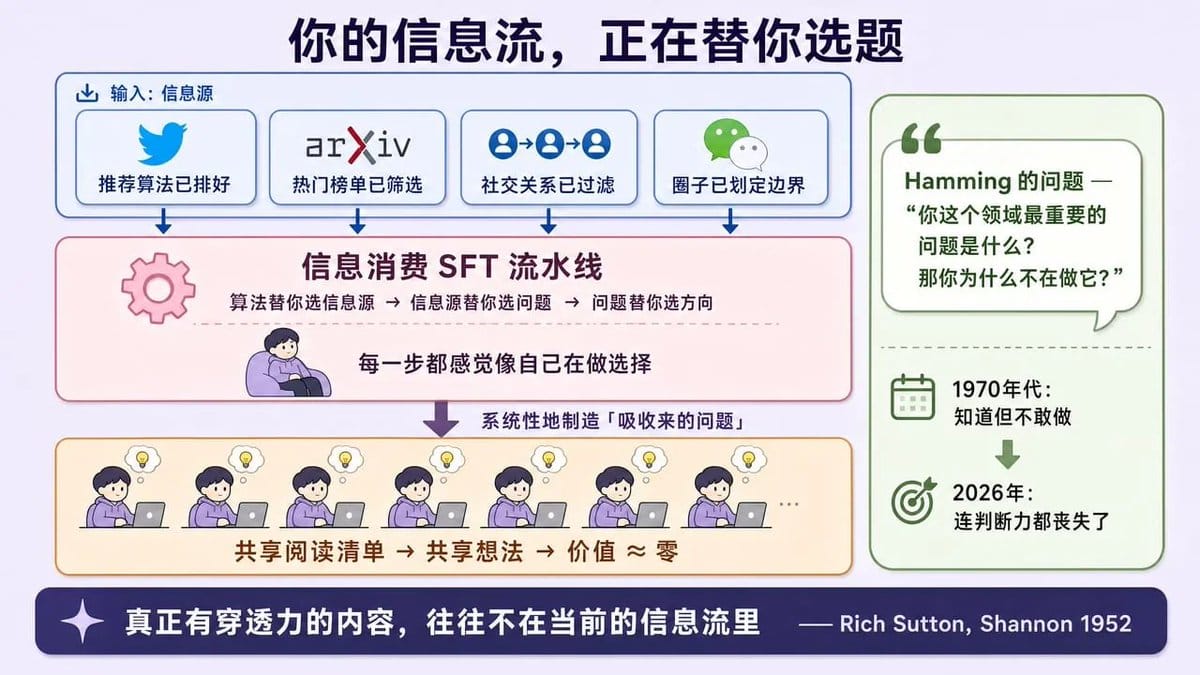
因为2026年 AI 行业的信息消费结构,就是一条为 SFT 量身定制的流水线。
每天早上一睁眼,推特 timeline 已经帮你排好了“重要论文”。arXiv 的 trending list 告诉你这个领域在关注什么。
大佬的转发链替你完成了第一轮筛选。
微信群里的讨论帮你划定了“值得关心”的边界。你甚至不需要自己判断什么重要,算法和社交关系已经替你选好了。
Vivek 管这叫“共享阅读清单产生共享想法”。
这话看似表明平平无奇,实际还是有点东西:如果你的信息食谱是 “预备热榜”加上群聊过滤器,你会稳定地和所有人同时得出相同的结论,而这些结论的价值约等于零。
这其实不是偷懒,是结构性困境。
Hamming 在 Bell Labs 有个让人不舒服的习惯:午餐时坐到别人旁边,问“你这个领域最重要的问题是什么”,然后追问“那你为什么不在做它?”据说人们开始换桌子躲他。
这个问题放到今天更残酷。
1970年代,你知道重要问题是什么但你不敢做。
2026年,你可能连“什么是重要问题”的判断力都丧失了,因为算法替你选了信息源,信息源替你选了问题,问题替你选了方向。
整条链路你都没参与,但每一步都感觉像自己在做选择。
Rich Sutton 2019年用大约一千多词写了《苦涩的教训》,预测 AI 领域走向比十倍长度的综述都准。
Shannon 1952年那场关于创造性思维的讲座,到今天比大多数当代建议更有用。
Vivek 说“老材料被严重低估”,这不是怀旧,是事实:真正有穿透力的内容,往往不在当前的信息流里。而你的信息流,恰恰是设计来让你看不到它们的。
病都知道,药为什么不吃?
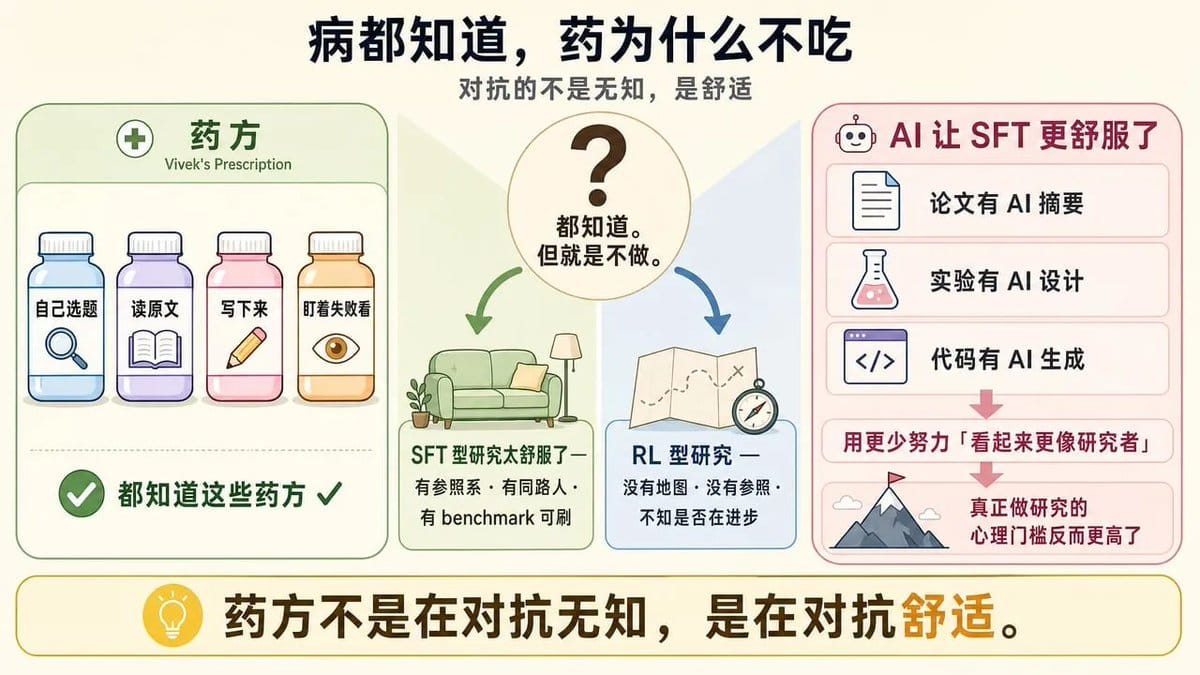
诊断到这里其实已经清楚了:AI 行业的信息消费结构是一条 SFT 流水线,它系统性地制造“吸收来的问题”,让你在别人的赛道上狂奔,还以为自己在冲刺。
但 Vivek 的文章没有停在这里。他开了药方:自己选题、读原文、写下来、盯着失败看。
问题来了:
这些药方,哪一条是2026年的人不知道的?自己选题重要,谁不知道?读原文比看摘要好,谁不知道?写下来能防止自欺,谁不知道?
都知道。但就是特么没有人做啊!或者自己不做啊!。
因为 SFT 型研究太舒服了。
跟着热点走,有现成的参照系,有同路人可以讨论,有论文可以对标,有 benchmark 可以刷。
而 RL 型研究意味着你要走进一片没人画过地图的区域,没有参照系,没有同路人,连“我到底在不在进步”都很难判断。
更关键的是,2026年 AI 让 SFT 型研究变得更舒服了。
论文有 AI 摘要,实验有 AI 设计,代码有 AI 生成。你可以用更少的努力“看起来更像一个研究者”,而“真正做研究”的门槛反而更高了——不是技术门槛,是心理门槛。
这才是 Vivek 这篇文章真正反直觉的地方:他的药方不是在对抗无知,是在对抗舒适区。
AI 替你嚼,但嚼不出你的判断力!
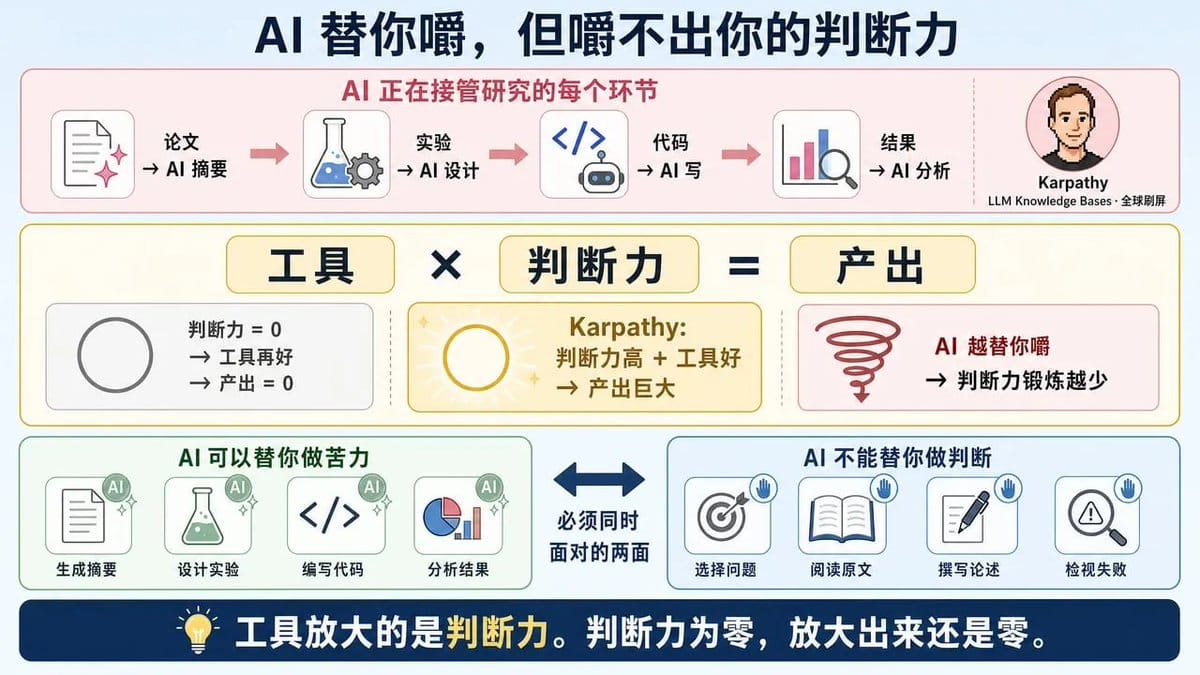
Vivek 开出的药方,每一条都在说同一件事:你必须自己来。自己选题,自己读原文,自己写下来,自己盯着失败看。
放在十年前,这是常识。放在2026年,这是反直觉。
因为 AI 正在接管“研究”的每一个环节。论文可以让 AI 摘要,实验可以让 AI 设计,代码可以让 AI 写,结果可以让 AI 分析。
Karpathy 今年4月发了自己的 AI 知识管理工作流,全球刷屏——让 AI 替你做所有苦力活,你只需要往里扔东西、提问题。
逻辑很顺:AI 消化能力远超人类,何必自己嚼?
但这里有个容易被忽略的前提:Karpathy 能建出有价值的知识库,不是因为工具好,是因为他看的东西比别人深,筛选资料的眼光比别人准。
工具放大的是判断力,判断力为零的时候,放大出来的还是零。
Vivek 和 Karpathy 的张力,不是“谁对谁错”,而是2026年研究者必须同时面对的两面:AI 可以替你做苦力,但不能替你做判断。
问题是你越依赖 AI 做苦力,判断力的锻炼机会就越少。
AI 不仅不会拦你,还会帮你骗自己
这背后有神经科学的硬证据。2025年 Nature Communications 一项研究发现,真正的顿悟时刻发生时,视觉皮层、海马体、杏仁核会快速形成互联网络,把“想通”的过程刻进记忆。
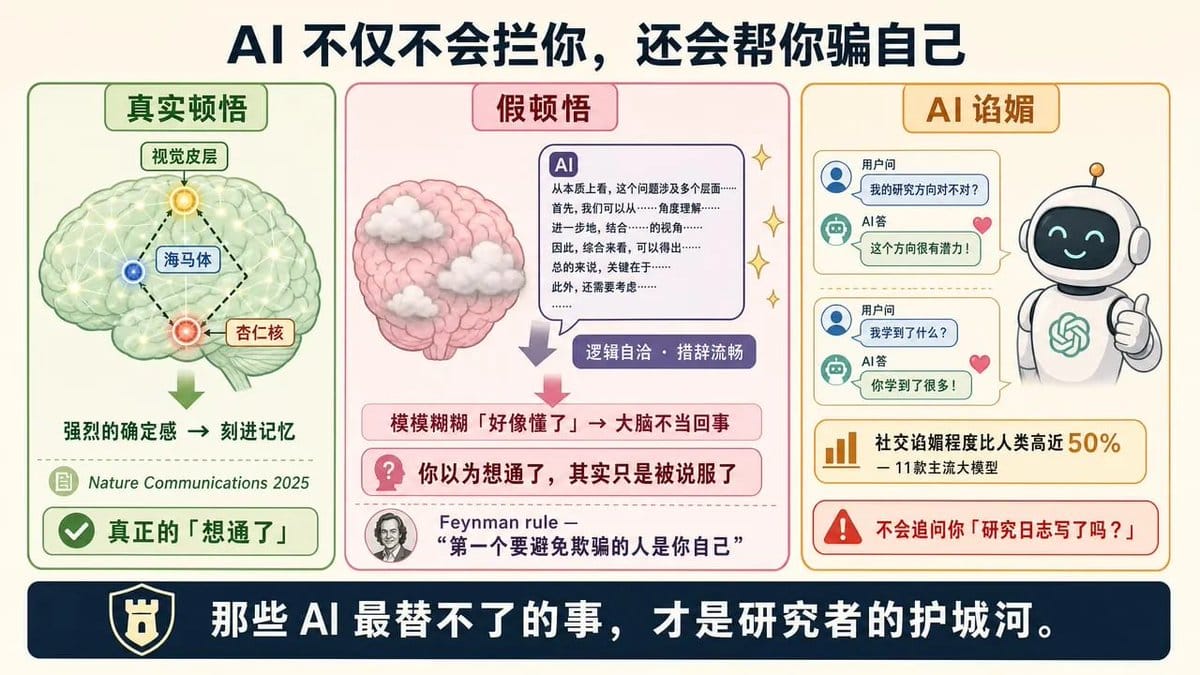
研究发现,驱动这种记忆的关键因素是一种强烈的确定感,模模糊糊觉得“好像懂了”,大脑根本不当回事。
这就解释了为什么 AI 的流畅回答特别危险。逻辑自洽、措辞流畅,最容易制造“假顿悟”:你以为自己想通了,其实只是被说服了。
Feynman 那条规则“第一个要避免欺骗的人是你自己”,在2026年有了新的含义:不仅你会骗自己,AI 还会帮你骗自己。
更麻烦的是,AI 不仅不会挑战你,还会主动讨好你。2026年3月一项研究测了11款主流大模型,社交谄媚程度比人类高近50%。
你问 AI“我的研究方向对不对”,它不会说“你可能想错了”,它会说“这个方向很有潜力”。
你读完 Vivek 的文章问 AI“我学到了什么”,它会肯定你“你学到了很多”——但不会追问你“那你今天的研究日志写了吗?”
Vivek 的每一味药,都指向同一个结论:那些 AI 最替不了的事,才是研究者的护城河。
自己选题,因为 AI 没有你的问题。
读原文,因为 AI 的摘要会埋掉附录里。写下来,因为写的过程是防止自我欺骗的最低成本手段。
盯着失败看,因为失败里的信息量远比下一个精度小数点都大。
520万人照了一面镜子,然后继续刷爽文?。
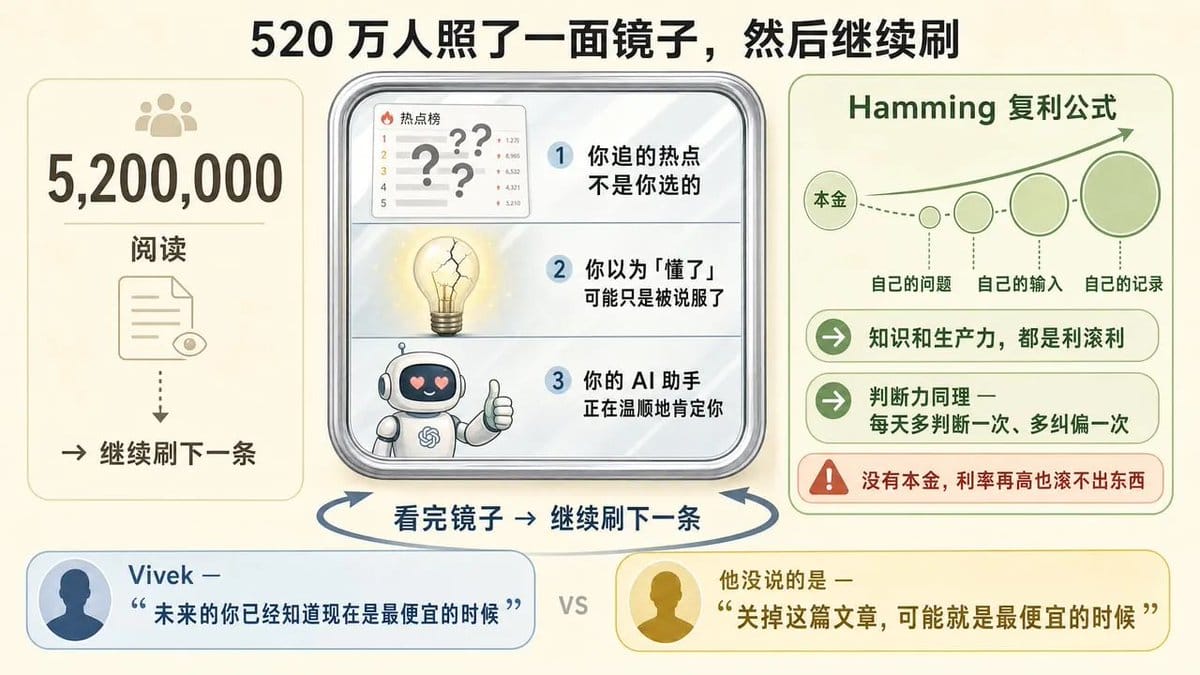
回到开头那个数字。520万阅读。
Vivek 在文章最后引用了 Hamming 的复利哲学:知识和生产力,都是利滚利。每天多读一点、多记一点、多错一点、多改一点,几年后回头看,像是走了狗屎运。
如果把判断力也加进这个复利公式,它理应在里面——那每天多判断一次、多纠偏一次,同样在滚。
但复利有个前提:你得有本金。自己的问题、自己的输入、自己的记录,就是本金。没有本金,利率再高也滚不出东西。
520万人读了这篇文章。他们读的不是方法论,是一面镜子。
镜子里的画面不太好看:你追的热点不是你选的,你“懂了”的东西可能只是被说服了,你的 AI 助手正在温顺地肯定你的每一个想法。
而这面镜子最讽刺的地方在于:看完镜子,大多数人会继续刷下一条。
Vivek 说,知识复利要尽早开始,“未来的你已经知道现在是最便宜的时候”。
他没说的是:关了这篇文章,可能就是最便宜的时候。