
本文经原作者授权转载,版权归原作者所有。原作者:Xudong Han(@Xudong07452910)。
前不久,Anthropic 公开呼吁全球暂停 AI 开发。理由是:AI 正在以惊人速度加速 AI 自身的开发进程。这句话不是警告,是对一条已经在发生的技术路径的描述——递归自我改进(Recursive Self-Improvement),AI 系统无需人类干预、自主设计并改进自身的能力。
这个方向,正是田渊栋离开 Meta 之后押注的赛道。2025 年秋天,他从 Meta FAIR 研究总监的位置上被裁,手机在接下来一个月被打爆,来自 Anthropic、xAI、Amazon、Apple、Microsoft 和一批初创团队的邀约同时涌来。他选了其中一个:Recursive Superintelligence,简称 RSI,8 人联合创始团队,融资 6.5 亿美元,估值 46.5 亿美元,目标是让 AI 自主做科学研究——用 AI 来研究 AI,左脚踩右脚,踩上去。
Anthropic 的那句暂停呼吁,恰恰定义了田渊栋他们正在做的事情的性质。这场对话的重量就在这里:一个亲身经历了 Meta FAIR 十一年、目睹了大公司组织架构如何在 AI 面前慢慢失效的人,在 2026 年初,坐在旧金山城里的 RSI 办公室,讲他对这条路的判断。
嘉宾田渊栋是 Meta FAIR 前研究总监,在 Meta 待了近 11 年,主导过 Coconut 潜在推理、顿悟(Grokking)理论、OpenGo 等前沿研究。RSI 的 8 位联合创始人还包括:Richard Socher(MetaMind 创始人、Salesforce 前首席科学家、You.com 创始人,任 CEO);熊蔡明(MetaMind 联合创始人、Salesforce Research 前 SVP);Tim Rocktäschel(Meta FAIR 伦敦强化学习研究员、Google DeepMind Project Genie 1/2/3 负责人);Jeff Clune(agent Open-Endedness 方向,The AI Scientist-v2 论文被 Nature 收录);Josh Tobin(OpenAI 早期员工、agent Science Lead);Alexey Dosovitskiy(Vision Transformer 一作);Tim Shi(施天麟,Cresta CTO)。团队现有约 25 人,2/3 在旧金山,1/3 在伦敦。
下面是这场约 90 分钟对话的整理,按主题重新组织,保留了原话引用。
要点速览
1. "最顶级的资本还是看人",8 位联合创始人撑起 46.5 亿估值,没有任何产品。 田渊栋解释这件事的方式不是讲技术路线,而是讲团队。AI 领域变化太快,"你今天说我们要做这个,过了两个月发现谁谁谁又出了点新东西",这时候投资人真正下注的是:这个团队能不能快速执行。8 个人每一个都有独立的顶级背书——Tim Rocktäschel 在 Google 的内部背调拿到极高分数,Josh Tobin 做过 OpenAI agent Science Lead,Alexey Dosovitskiy 是 Vision Transformer 一作——这个阵容本身就是估值。
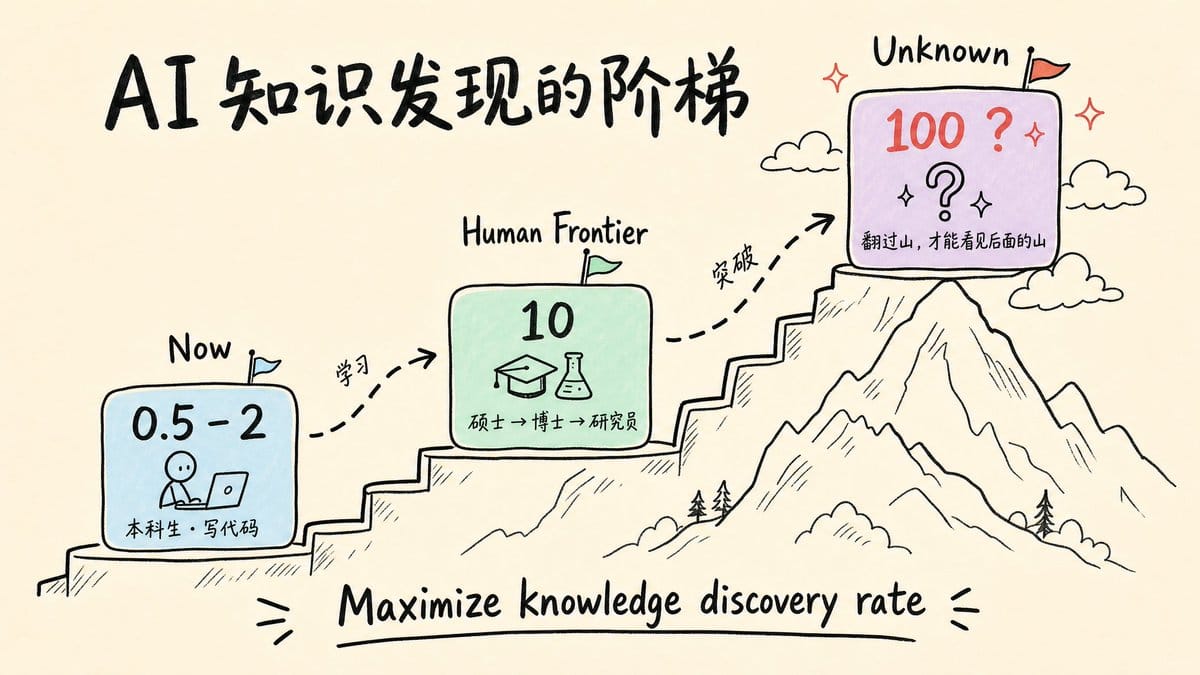
2. 递归自我改进的核心押注:AI 做科研,不是 AI 辅助科研。 RSI 的目标是"maximizing knowledge discovery rate",即最大化知识发现速率。田渊栋把现在 AI 的位置定在 1-2 分(满分 10),但他提醒:翻过人类边界的 10 分之后,后面可能还有 100 分,"你要翻过那座山,才能看见后面的山有多高"。每一个阶梯都有应用价值,这不是 all-or-nothing 的赌注。
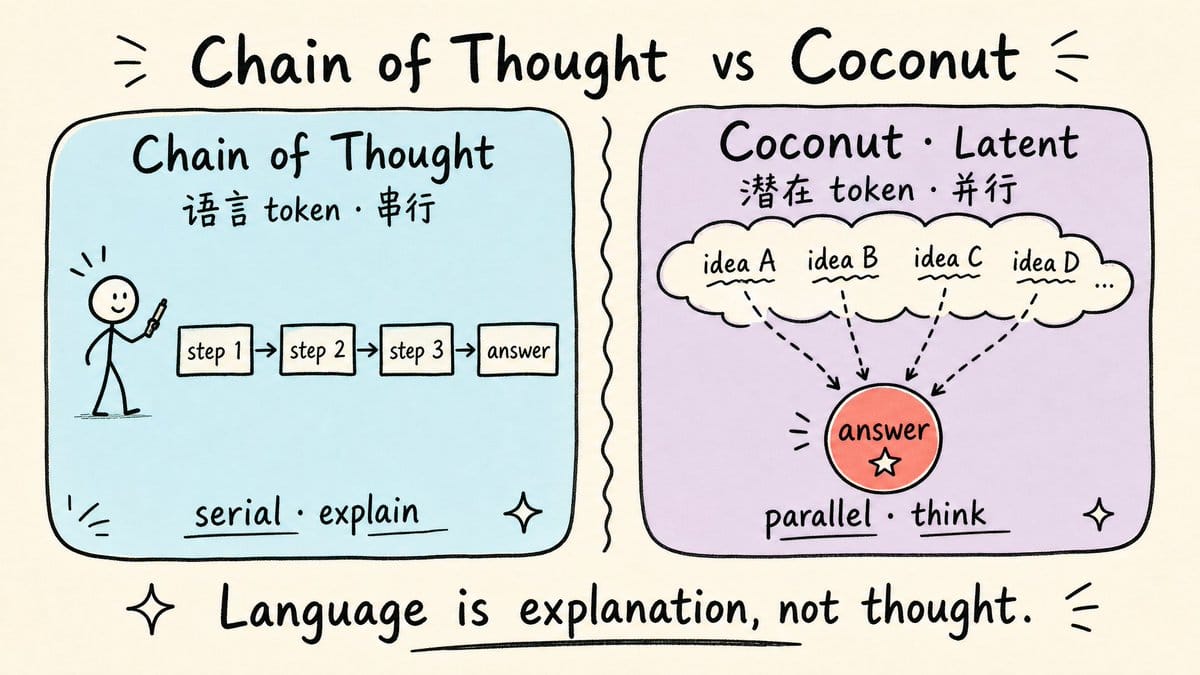
3. "语言不是思考本体",Coconut 路线挑战 Chain of Thought 的根基。田渊栋的论点不绕弯子:他自己思考时用的不是语言,"很多时候是有图像的成分,有一些说不清道不明的思路",语言是解释,不是思考过程本身。Latent token 能同时存多个思路,语言 token 只能一个个串行写出来,效率天然不同。这篇 Coconut 论文已有大量引用,Anthropic 的 Mythos 模型被圈内人猜测用了 Looped Transformer,这是同一方向的产业验证。
4. 预训练的上限决定强化学习的上限——这是田渊栋自己的观点,他也注明"可能是错的"。 逻辑很清楚:RL 做的是把第 200 个答案提到第 1 个,但这个"种子"必须预训练时已经存在。"如果种子都没有的话,那强化学习再做还是没有用的。"这个判断直接挑战了"只押注 RL 就够了"的思路,也是他对 David Silver 的 Ineffable Intelligence 路线保持保留意见的原因。
5. Frontier Lab 的竞争最终变成了组织架构之争。 xAI 和 Llama 4 的失误有同一个根因:老板压力大,团队没有能力 push back,顺从堆积,最终 delivery 与 promise 脱节,"那就会有一个 shock,一个很大的地震"。田渊栋在 Meta 待了 11 年,看过大团队因为对齐速度跟不上 AI 发展速度而频繁 reorg、裁员。他的结论是:大公司趋同化是结构性问题,不是个人能力问题。
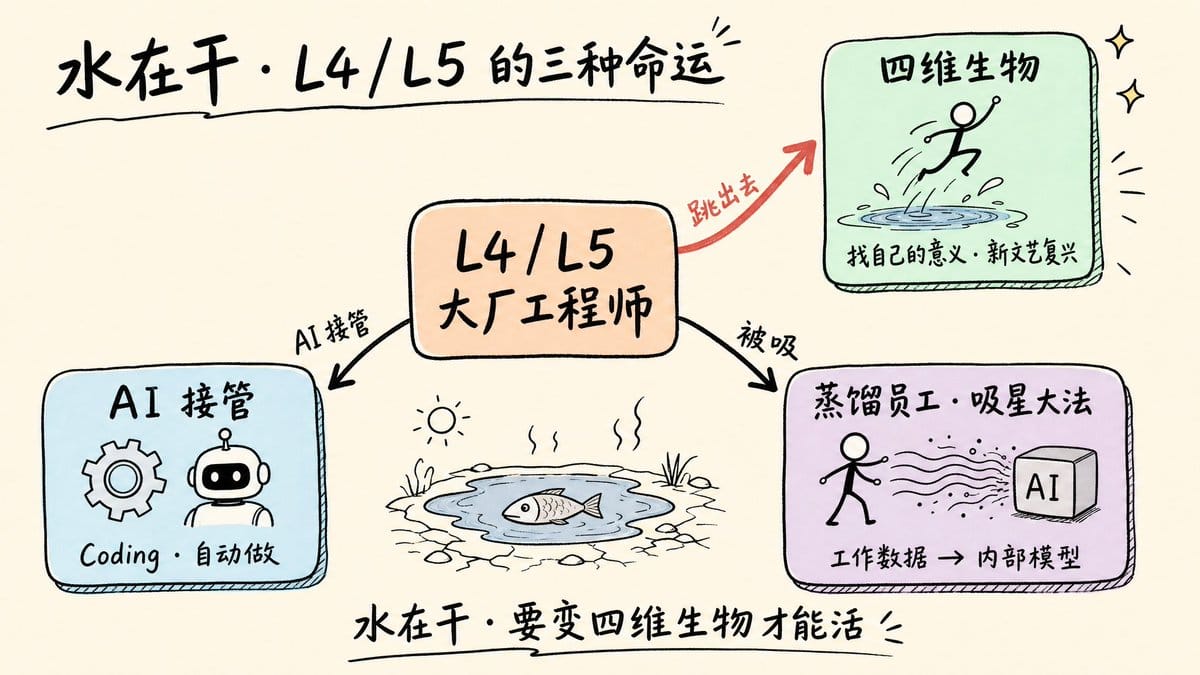
6. "蒸馏员工"是一面镜子:鱼在水坑里跳,水越来越少,要么变成四维生物,要么消失。*Meta 强制蒸馏员工(用员工工作数据训练内部 AI)这件事田渊栋认为"说得比较赤裸裸",但他更关心的是另一层:这个趋势"有一个人开始做,大家都会做",并且最终效果存疑,被蒸馏的员工可能故意不把最重要的东西拿出来,甚至"埋雷"。就业冲击的比喻来自《三体》:AI 把水坑里的水弄干了,"你最终一定要变成一个四维生物,你才能活下来"。
7. coding 之后的 next big thing 是 AI research。逻辑是:AI 研究员的时薪比软件工程师更贵,自动化 AI 研究的 ROI 更高。发现新药、新材料、新训练方法——每一个都是"天文数字"的回报。这也解释了为什么 Anthropic 请 Andrej Karpathy 去做预训练和 auto research,在田渊栋看来这是一个"大家去承认这件事情是对的"的信号。
1.从 Meta 出走:8 人组队,速度是决定性因素
在 Meta 待了将近 11 年,田渊栋对大公司有话直说:
大公司的那些人,他们没有这个能力,不是没有这个能力,是有能力,但是没有这个时间,也没有这个精力去做一些跟大方向不一致的东西。这非常难了。
被裁之后的一个月,他的手机"基本上是被打爆的状态"。Anthropic、xAI、Amazon、Apple、Microsoft 都有联系,还有不少初创团队。最终他选了 RSI,理由不复杂:团队刚刚组建,机会大;里面有两三个以前就认识的人,包括以前在 Meta 伦敦做强化学习的 Tim Rocktäschel;而且这是 co-founder 的机会,不是 head of AI 或 head of research 的雇佣。
有趣的是,他说当时找他的很多人,"大概两三个月之后……都走了"。大团队因为组织架构臃肿,"对齐速度远远慢于小团队",频繁 reorg 和裁员是必然结果。
RSI 的 8 位联合创始人阵容可以说是这条路上能想象到的最强配置。
- Richard Socher 主导过 MetaMind(后被 Salesforce 收购),出来开 You.com 已经盈利,现在担任 CEO。
- 熊蔡明是 Salesforce Research 前 SVP,在 Salesforce 待了十年多。
- Tim Rocktäschel 离开 Meta 去了 Google DeepMind,是 Project Genie 1、2、3 的负责人,也领导了 agent Open-Endedness 团队,这个方向"跟我们现在做的方向非常接近",他在 Google 的内部背调拿到极高评分,直接带来了 Google Ventures 的投资。
- Jeff Clune 做 agent Open-Endedness 已经超过 10 年,最近一篇 The AI Scientist-v2 被 Nature 收录。
- Josh Tobin 是 OpenAI 早期员工,公司被 OpenAI 收购后做了 agent Science Lead。
- Alexey Dosovitskiy 是 Vision Transformer 的一作。Tim Shi(施天麟)是 Cresta 的 CTO,为了这个愿景把 CTO 都辞了。
最顶级的资本还是看人。因为投资、融资也好,最终的商业愿景也好,最终的产品也好,在 AI 这个变化非常大的领域里面,其实很难在一开始就讲得非常的清楚。很多时候是这样了,就是你今天说我们要做这个,然后过了两个月发现谁谁谁又出了点新东西,那么这个时候团队要怎么应对,他是不是能很快的执行力做一件事情出来,这个其实是最重要的。
田渊栋把这句话说得像是在解释一个规律,不是在解释自己的案例。
注:Meta FAIR(Fundamental AI Research)是 Meta 的基础研究部门,由 Yann LeCun 建立,长期在学术圈和工业界之间保持开放发表的传统。田渊栋在 FAIR 任研究总监多年,主导了多项前沿研究,包括 Coconut(连续潜在推理)、Grokking(顿悟理论)等。2024 年底 Meta 的裁员影响了 FAIR 的多个团队,直接触发了本文涉及的这波 neolab 创业浪潮。
2. 递归自我改进:让 AI 来做 AI 做不到的事
RSI 的字面意思是"递归超级智能",但田渊栋更愿意从方法论切入:
递归自我改进的意思就是说,我能不能用 AI 来优化很多 AI 自己的一些东西,让 AI 变得更强。通过这方式再左脚踩右脚,再踩上去,大概是这样的一个逻辑。
具体到第一步,是让 AI 自动化做科研。这个逻辑有一个看起来像悖论的地方:正因为 AI 现在做不到自主提出假设、自主验证,RSI 才要做这件事。
正因为现在 AI 做不了,所以我们希望 AI 能做,是这样的一个逻辑。
这不是 all-or-nothing 的赌注。和无人驾驶不同——车要么在路上 100% 安全,要么撞人。AI 科研自动化有很多层次:今天能写代码,明天能读论文,后天能理解问题本质,再往后能做出非平凡发现。每一个层次都有应用价值,都可以商业化。这个"阶梯"结构是田渊栋对这条路有信心的核心原因之一。
如果最终目标是 10,现在在哪里?
也许我们现在在 1 和 2 的这个位置上。甚至我可以说,我们现在可能就是 0 点几,也可能是 0.5 吧。非常早期。……假设我们说人类的那个边界是 10,也许我们现在在 1 和 2 的这个位置上,但是过了那个边界之后,也许还有 100。那部分我们是不知道的。就是你要翻过那座山,才能看见后面的山有多高。
RSI 的网站上写的是"maximizing knowledge discovery rate"(最大化知识发现速率)。这不是一个模糊的愿景,而是一个可以被分解成 benchmark 的目标:先让 AI 从做本科生能做的事,进化到硕士、博士、研究员能做的事,每一步都是一段阶梯。
可解释性在这条路上比通常想象的更重要。理由有两层:第一,Recursive Self-Improvement 过程中需要花大量算力,如果能在训练完成前就通过可解释性工具判断模型方向对不对,运算效率会大幅提高;第二,当 AI 能自主修改自身代码或权重时,"我们不能代替模型去发现新东西,那我们就得知道模型是怎么想的",否则安全边界就没有办法设定。
注:The AI Scientist-v2 是 Jeff Clune 团队的工作,展示了 AI 系统自主设计实验、撰写论文的早期能力,被 Nature 收录是这个方向获得主流科学界认可的标志性事件。OpenAI 最近发现 AI 能够证明"完全非平凡的定理",田渊栋认为这类事件的频次正在加快,是支持 RSI 路线的直接证据。
3. "语言不是思考本体":Coconut 路线挑战 Chain of Thought
这是整场对话里技术深度最高的一段,也是最值得单独拎出来的一个判断。
Chain of Thought(思维链)是当前推理模型的主流路线:让模型把推理步骤用语言写出来,然后再给出答案。田渊栋不认为这条路是错的——"一个是非常实用,大家都在用,所以肯定不是错的"——但他认为它不是推理的本质:
人类在思考问题的时候,最终还是需要一个非语言的媒介来做这个事情。其实至少对我来说,我在思考问题的时候,其实我并不是需要用语言来做的。很多时候是有图像的成分,有一些是一些比较说不清道不明的一个思路,在这个思路里面发现了一个问题,然后我把它写下来,变成语言。所以语言更多情况下是一种解释,而不是说是思考的过程。
他在 Meta 做的 Coconut(Continuous Thought,连续思维链)研究就是在潜在空间(latent space)里做推理,而不是把每一步思路写成语言 token。这里有一个技术优势:
Latent token 你可以存很多信息,比如说你可以同时存几个不同的思路,同时存在一起,最终这里面有一个思路是对的,那么你这个路径就出来了。但如果你要用语言去想的话,你就得人工地去写下来每个思路是什么,得一个一个出来。所以这个效率就是不一样的。
Coconut 论文发出后已经有大量引用,田渊栋认为这个方向"将来应该是有很大的东西可以挖的,而且也许以后可能是一个有意思的突破点"。圈内最有意思的侧面证据是:有人猜测 Anthropic 的 Mythos 模型用了 Looped Transformer 结构,原因是 Mythos 在图上搜索类问题的表现远超以往模型,结构性优势指向了某种非标准架构。田渊栋不做评论,但他说"这是一个可能的路径"。
RSI 会继续做这个方向,但具体细节保密,"我们毕竟是公司,所以很多事情我不能讲太细。"
注:Coconut(Continuous Chain of Thought)是 2024 年末 Meta FAIR 发表的研究,作者包括田渊栋团队。核心思想是让语言模型的推理在连续向量空间中发生,而不是强制生成离散的文字 token。Looped Transformer 是一种权重共享的架构,通过多次循环同一层来实现深度推理,性质上接近 Coconut 的思路。两者都在挑战同一个隐含假设:推理的本质是语言序列。
4. 预训练的天花板决定 RL 的天花板
这是田渊栋在对话里罕见地加了一句"这也是我的观点,所以有可能是错的"的一个判断——这个谦辞本身就说明它分量不轻。
强化学习后训练,它的目的,它的很大的功用,就是说你把原来你排在比如说第 200 个的答案,把它放到第一个去了,从这个方式,可以让模型做一些问题做得比较好。这个条件是:这个问题一开始的答案,至少有一个是对的。
RL 在做的是"选种子",不是"创造种子"。如果预训练过程中这个问题的答案从未出现过,你让模型 try 一千次一万次,种子还是不存在,RL 就无从施力:
最终如果种子都没有的话,那强化学习再做还是没有用的。所以它光是来押注强化学习这一件事情,还是上限是在那。
这个判断的实践含义很明显:RSI 的路线必须把预训练做好,而不是绕开预训练只做后训练。田渊栋说他们现在在预训练方面"也在尝试",因为预训练的 loss curve 相对稳定,是一个"比较好的方向"。
他同时提出了一个更深的观察:最近大模型的一波进展,很大程度上来自把推理模型(reasoning model)的输出数据放回预训练或中训练——这是最初步形式的自我进化,"通过这个方式,这个模型变得更强,然后就达到了一个自我进化的初步的目的"。这正是 RSI 想要往更深处推的方向。
未来一种可能的路径是连续学习(continuous learning):新数据放进来,模型快速吸收,不用从头重训。但田渊栋认为更根本的问题还是算法和范式:如果不改变现在的训练范式,仅仅堆数据,最终会撞墙。
你这样纯拼 scaling law 的话,横轴它是一个指数的,指数到一定程度之后大家都受不了,你要再 10 倍的电力,再 10 倍的资源,不可能。所以最终一定会撞到一个地方。
这就是为什么小公司有机会的结构性原因:不是因为他们算力更多,而是因为他们有理由去探索大公司没时间探索的范式。
注:Grokking(顿悟)是田渊栋团队在 Meta 时期的一篇理论研究,从数学上描述了神经网络从"记忆"突然跳跃到"泛化"的相变过程,核心是一个能量函数在数据量达到阈值后结构性改变。这个理论与预训练的天花板问题高度相关:它告诉我们模型要泛化需要多少数据,以及什么条件下 RL 才有"种子"可以利用。
5. 商业化的起点:为什么是"自动化科研"而不是更容易的方向
田渊栋被问到一个绕不开的问题:为什么不做一个更容易商业化的方向?
他的回答是一个反向推理。做某个垂直领域的特定应用,"之前其实应该说在过去的三年里面,已经有很多的样例证明:为了某件事情做一个比较特殊化的一个模型,也许有一天会被一个大的、更加一般化的模型给取代或者给盖掉"。这是创始人层面的恐惧:今天能赚钱的技术路线,明天可能就被通用模型碾压了。
我们应该把目标放得更长远一点。我们希望就是在这个范式上,花时间花精力——这个范式说我自我来自我进化这个范式。这范式只要不变,那我们的公司立场是不变的。在这范式之下,我们再看有没有什么好的应用,有没有什么好的可以商业化的机会。
他们内部已经有一些商业化思路:训练一个模型让大模型推理变得更快,或者让推理效率提高;找到新的训练 recipe 然后商业化;对人类做研究的思维方式建模之后,帮研究机构自动化部分科研流程。
时机上,"去年年底,基本上跨过了这个突变点",AI coding agent 从辅助写代码变成了真正能接受命令、执行任务。这个突变点让"小公司弯道超车"成为可能,因为大公司需要一到两年去慢慢适应新生产力工具,而一个 25 人的团队可以在几周内就重新组织工作方式。
如果再过一年的话,可能就已经晚了。因为大家都已适应了之后,你再去出来创业,这可能也是一个很大的问题。
RSI 计划先用一到一年半把系统做深、做好,然后再找到更好的落地应用场景,当前融资的 runway 大约两到三年。
注:RSI 网站上列出的方向"maximizing knowledge discovery rate",指向的是一个比 AI for science 更宽泛的框架:不仅仅是用 AI 做药物发现或材料科学,而是对"知识被发现"这个过程本身做自动化。Socher 在公开采访中提到的物理学、化学、临床、生物学等都是候选落地场景,但 RSI 内部给自己定义的第一步是"能在今年年中推出 Level 1 自主训练系统"。
6. Neolab 生态横扫:SSI、AMI Labs、Ineffable、RSI 各自在赌什么
这部分是田渊栋最谨慎的一段,因为他直接点评的都是同行,而且 Yann LeCun 还是他前老板。
SSI(Ilya Sutskever 的 Safe Superintelligence):田渊栋坦承"我们现在都不知道他内部在做什么,所以也很难评价"。他的猜测是 Ilya 可能在研究一个新的训练范式,让训练效率大幅提高,"因为我一直觉得现在 AI 的训练过程,应该说还是不是很有效率的,如果能发现的,那就有很大的 upside"。他补充说 Ilya 去年播客里提到的方向——"research of taste"、泛化 vs. 记忆——"跟我们之前《硅谷101》我们一起做的那个访谈,有很多东西是很接近的"。
AMI Labs(Yann LeCun 的 AMI Labs):视觉世界模型路线。田渊栋的观点是:
语言跟视觉相比,语言还是一个更加有信号的东西。……语言可以无限嵌套,它可以自指,它可以有很多新的信息和新的深的这种理解在里面。所以我觉得语言应该说,它的上限可能会比图像更高一点,这是我的一个观点。
JEPA 这些视觉模型"太早了,可能还要再找到一些新的关键突破才可以",他承认这不是一个完全公正的 opinion,但他站在语言这边。
Ineffable Intelligence(David Silver):AlphaGo 和 AlphaZero 的主要发明人,"希望完全不用大模型",纯粹用强化学习从零开始。田渊栋的看法:围棋和国际象棋的评估函数定义得非常清楚,AlphaZero 的左脚踩右脚能跑通,但在开放式的、模糊的问题上"其实很难做到这一点,所以可能需要大量的算力,这个算力现在可能很难满足"。而 RSI 的立场是"比较实在的":
如果大模型很厉害,我肯定用大模型,然后找到更好的方法来训练大模型。
各家 neolab 面临的共同挑战是:以前在大厂,"我们做个实验吧,我们就花很多钱把实验做了,可能这个实验花了几百个 million,甚至一个 billion",现在的钱是有限的,"怎么能让这个学习过程变得更有效率"是一个生存问题,不仅仅是研究问题。
如果一个人只有 scaling law 这个思想的话,可能不太容易成功。你还是需要在 scaling law 之外,还有什么其他的一些新的、对问题更深的理解,那么就能成功。
这句话是整场对话里对小公司 vs 大公司竞争格局的最锐利的一句。小公司没有大公司的算力,但他们有 research taste,而 research taste 是不能靠资源堆出来的。
注:Ilya Sutskever 的 SSI 成立于 2024 年,融资约 10 亿美元,策略上极度保密。Jeff Clune 长期在 Ilya 研究轨道附近工作(agent Open-Endedness),他加入 RSI 并非巧合,这个方向在 SSI 和 RSI 都有布局。David Silver 的 Ineffable Intelligence 主打纯 RL 路线,与 AlphaZero 的设计哲学一脉相承。AMI Labs(Advanced Machine Intelligence,Yann LeCun 创立)押注视觉世界模型,JEPA(Joint Embedding Predictive Architecture)是核心技术路线。
7. Frontier Lab 大乱斗:组织架构才是真正的赛场
田渊栋对各家 Frontier Lab 的评论,最敢说的部分不是技术,是组织。
Anthropic:今年叙事"非常猛",一部分原因是准备上市,一部分是商业化增长极快。Andrej Karpathy 加入去做预训练和 auto research,在田渊栋看来是一个信号:
说明 self improvements、auto research 非常重要……就让大家觉得,确实 self improvements 或者说 self learning,这个方向应该说是主流了,或者说大家去承认这个事情是对的。
他对 Mythos 模型"太强了所以不敢发布"这个说法不做评论——"这个就等它发布之后再讲"。他猜测 Anthropic 的优势可能来自模型架构或训练方案的创新(而不仅仅是把推理数据放回预训练)。Codex 和 Claude Code 他都在用,"各有各的问题,比如说 Claude Code 有些时候会给你 hallucinate"——他的结论是两者差距没有那么大,"只要 OpenAI 想追,是能够追上去的"。
OpenAI:"之前有些问题,是有很多的方向它都在做,不太 focus,现在开始很 focus 了"。他把 OpenAI 关掉 Sora 解读为上市压力下的商业叙事转向:一旦进入 IPO 逻辑,就要给资本市场讲清楚 revenue 和 cost,"这个逻辑就跟以前那个 research lab 逻辑不一样了"。
谷歌:问得比较委婉(因为 Google Ventures 是 RSI 的投资人),但他给了一个数据支撑的事实:Gemini 2 的时候"大家一直在说它不行了",Gemini 3 就变得很厉害。"只要领导层有这个重视的话,一定还是不错的。"Sergey 亲自挂帅成立 Strike Team 追 coding,这个动作本身说明这家公司还有反应速度。
Meta / Muse Spark:田渊栋先披露了利益相关("我还是有很多它的股票"),然后说 Muse Spark"还是不错的",多模态理解"还有一些回答也比较好",但总的来说"可能比 Gemini 3 还是要差一点"。他不认为 Meta 已经放弃通用前沿模型路线,"训练一个更 general 的模型,然后再 fine-tune for the specific use case,这个是更好的,就是说他们其实还是没有放弃说我要去争夺最强模型的这件事情"。
他对整个竞争格局的最终判断只有一句:
大模型里面没有永远的赢家,应该这么说。
注:Google Ventures(GV)是 Google 旗下独立风险投资基金,是 RSI 本轮融资的参与方之一,背调由 Tim Rocktäschel 在 Google 的口碑直接促成。Anthropic 的 Mythos(内部代号)被部分研究者猜测用了 Looped Transformer 结构,依据是其在图搜索类任务上的异常强表现,但 Anthropic 从未公开确认。
8. xAI 与 Meta 的组织病:CEO 压力、push back 缺失、"吸星大法"
这是田渊栋说得最直接的一段。
关于 xAI 和 Llama 4 的失误,他提出了一个可以重复观察的模式:
一个组织,如果这个组织里面的人,他没有这个能力去 push back,或者说去反驳上面对他的要求,那么这个组织的人就只能通过某种方式来顺从上面的压力。但是一开始这个顺从是可以的,但是时间长了之后,总有一天上面的人会发现,这个组织的 delivery 跟 promise 是不一样的。那么就会产生问题。产生问题之后,你就会有一个 shock,就是很大的一个地震。
xAI 和 Llama 4 的结果"很像"——"老板会觉得你们这些人,我不相信你们了,我们得外面再拉一个人过来"。原来的组织成员"可能就境遇比较惨"。
更大的结论:
前沿大模型之争,其实最后变成了一个组织架构之争了。应该说本质上来说是先进生产力和落后生产关系之间的一个矛盾。
Meta 强制蒸馏员工(用内部工作数据训练 AI 模型)这件事,田渊栋的评价分两层。第一层,这件事说得"比较赤裸裸",对员工感受"比较不太顾及",但从公司法律层面"愿者上钩,你来了之后,他们有这个条款,你就得遵守这个条款"。第二层,他更怀疑这件事的实际效用:
可能大部分人会因为有这个条件,导致这些人不愿意工作得特别好,不愿意把自己最重要的事情给做出来,或者故意在里面埋雷,或者说埋一些奇怪的东西,让你训练被搞坏掉。
"蒸馏员工这个事情感觉是个大趋势了,我觉得有一个人开始做,大家都会做。",这是他把个体事件解读为产业走向的方式:不是在评判 Meta 的对错,而是在观察一个趋势的开始。
对于愿意接受这种条款去大公司的人,他没有劝阻,只是提出了结构性描述:
你会发现你去跳到大厂,去一个大厂被裁了,你就跳到另外一个大厂,过两天又被裁了,再过两天又被裁了。它就相当于一条鱼在水坑里面跳,但是水就在干。……你最终一定要变成一个四维生物,你才能活下来。
这个比喻来自《三体》。原书里四维生物把水弄干,三维世界的鱼无路可逃。田渊栋用它来描述 AI 时代大公司岗位的处境,不是在恐吓,而是在描述一个他认为已经开始发生的结构性转变。
注:"蒸馏"在 Meta 的这个语境里指的是让 AI 观察员工完成工作的过程,从中提取知识用于训练内部 AI 模型,类似知识蒸馏(Knowledge Distillation)在 AI 训练中的技术含义——用一个"教师模型"(这里是人类员工)指导"学生模型"(内部 AI)学习。田渊栋调侃称之为"吸星大法",取金庸武侠里吸人内力的意象。xAI 这波被田渊栋观察到的组织问题,时间点对应 Grok-3 发布周期前后,Llama 4 的情况在 Meta 内部因为裁员和组织重组背景而更为复杂。
9. AI 时代的职业:L4/L5 工程师、"全民创业者"与四维生物
这个话题田渊栋没有绕。他半年前就说过"大家迟早全部都要失业",这次他认为更近了:
我觉得以现在的 AI 能力,比如说相当于以前的四级或者五级的工程师,大概是这样的一个感觉。因为一般是应届毕业生刚进大厂的时候,他们都叫 Level 4,这个可能是 Google 和 Meta 的 Level,比如说 senior 一点的话,变成 Level 5。那么 4 和 5 的这些工程师,他们的能力,就是 AI 很多事情其实可以做了。而且 4 和 5 应该说是在大厂里面比较多的。
这不是理论推断,而是他现在自己在用 AI 工具的直接感受。他写 blog 谈 vibe coding 的体会,结论是"确实用的人会越来越少"。
对应届毕业生他是实话实说:如果本身非常厉害,有工作业界知名,还是有希望;但 junior 的很多工作"你们都可以让 agent 去做了"。RSI 招人的标准是:经验丰富,且愿意自己 hands-on 把事情做成,这本身就已经在筛掉大量应届生。
他的 2021 年博客在 GPT-4 发布时写过:以后大家都是独一无二的,"只有你愿意去探索的东西,这个是最重要的"。这次他把这个判断升级了一格:
大厂不需要那么多人了,所以大家就得找到自己的意义。以前可能是你被教育出来,教育了四年本科、两年硕士、五年博士,最终你的目的是成为一个螺丝钉,或者成为某个大机器的一个零件。但是现在已经不一样了,大机器不需要你的零件了,你得自己去寻找自己的意义。
他把这个变化叫"新的文艺复兴",或者回到了"古希腊的状态",每个人都需要找到自己想要做的事情。这个过程"应该说是一个比较痛苦的过程,但是最终可能会不可避免地发生",他估计 3 到 5 年内会有大量人面临这个选择。
对于 RSI 自己要招什么样的人:AI coding 工具已经很强,"很多时候经验和品位和方向是更重要的"。大公司谈工资和总包,小公司谈愿景和工作内容,"Mindset 和思路是不同的"。RSI 现在 25 人,目标扩张到 40 人左右。
注:Google 和 Meta 的工程师层级体系里,L4 是 Software Engineer(应届直招起点),L5 是 Senior Software Engineer,这两个层级是大厂工程师人数最多的区间,也是现在 AI agent 影响最直接的区间。"四维生物"典故出自刘慈欣的《三体》三部曲,在原书语境里是维度打击的概念,田渊栋借用它描述"突破现有维度限制才能在新环境中存活"的比喻。
末尾 Q&A 速览
Q:8 位联合创始人加在一起会打架吗?
目前合作相当顺利。田渊栋的解释:都是聪明人,和聪明人合作"其实应该说是比较省心的",大家都希望花很多时间和精力把事情做好,"把盘做大"。决策机制是"比较民主",有很多思想上的碰撞,最终找到大家认同的逻辑一起推进。
Q:RSI 会做预训练吗,还是直接用已有模型?
田渊栋的答案是:两条路都在尝试。"目前我们还处于探索阶段,我们会有一些不同的方向都会去试。"预训练的好处是 loss curve 比较稳定,是一个值得探索的方向。
Q:Chain of Thought(思维链)的路线会被取代吗?
不会"被取代",但"语言更多情况下是一种解释,而不是思考的过程"。Latent reasoning(潜在推理)在原理上效率更高,因为 latent token 能同时存多条思路,而语言 token 只能串行输出。Coconut 的方向会继续做,具体细节不能披露。
Q:coding 之后,下一个 AI 接管的大方向是什么?
田渊栋的回答是 AI research(AI 研究)。逻辑:AI 研究员的薪资比软件工程师更高,自动化这件事的 ROI 更大。发现新药、新材料、新训练方法,"每一个都是天文数字的回报,当然是高风险高回报的事情"。
Q:OpenAI vs Anthropic,谁会赢?
"很难讲。"两边的技术差距没有看上去那么大,OpenAI 现在也变得更 focus 了。接下来的胜负手不在技术,在"谁能够让用户愿意去用"——是产品竞争,不是模型竞争。他预计两边都会遇到上市叙事的压力,从 research lab 逻辑切换到资产负债表逻辑。
Q:neolab 的护城河在哪里,大公司会不会把它们盖掉?
小公司如果真的做成了,"那么他已经获得了很多钱,收了很多的资金去投入",大公司来追的时候小公司已经有 leverage。更根本的护城河是:大公司有资源,但"他们没有这个时间,也没有这个精力去做一些跟大方向不一致的东西",neolab 做的恰恰是现在大公司没空做的方向。
Q:田渊栋自己的科幻小说还会写吗?
"我有点紧迫感,如果再不写的话,我的 idea 就没了,因为已经实现了。"他感觉写科幻写得慢的话,可能跟不上 AI 的实际进展。AI 可以帮他写,但"AI 有自己的 AI 味,有没有办法能够让 AI 味去掉,然后能找到自己想要做的、想要写的东西",这是他还在想的问题。
最后
这场对话最值得拎出来的,不是任何一个具体的技术判断。
是田渊栋把大公司的组织问题和 AI 能力的进步速度放在同一个框架里分析的那个视角。他说"前沿大模型之争最后变成了组织架构之争",这句话的重量不在它的结论,在它背后的因果链:AI 让技术进步的速度极大加快,而大公司的组织对齐速度没有跟上,这个差值就是 neolab 存在的理由。这不是一个悲观的判断,但也不是一个中立的观察——他从 Meta 出来,组了一个 8 人团队,本身就是在用行动对这个判断做下注。
第二个值得注意的反直觉判断是 Coconut / latent reasoning 路线。主流推理模型路线是 Chain of Thought,各家在争的是谁的思维链更长、更准、更快。田渊栋的论点是:语言不是思考的本体,思考发生在语言之前,语言是把思考写出来的过程。这个判断如果是对的,意味着现在所有在"更长的 CoT"这个方向上卷的能量,相当一部分是在优化一个次优的中间层,真正的效率提升在潜在空间的推理里。Anthropic 的 Mythos 用了什么架构没人知道,但圈内人的猜测本身说明了这条路线在实验室之外已经有了产业背书的氛围。
第三个看点是就业冲击的叙事粒度。他没有说"AI 会让很多人失业"这种大而化之的话,而是把失业者的具体身份说出来了:L4/L5 的软件工程师,大厂里人数最多的那一批。这不是在做预言,他在描述他现在自己用 AI 工具时感受到的能力水位。"以现在的 AI 能力,大概相当于以前的四级或者五级的工程师"——这句话如果成真,大厂的工程师人员结构要重新算一遍,而且不是几年之后,是在发生。
接下来 12-24 个月有几个可以具体观察的信号:第一,RSI 能否在年中前推出 Level 1 自主训练系统,以及这个系统在 AI 科研自动化上的实际能力水位;第二,Anthropic 的 Mythos 模型发布之后架构是否被确认,这会直接验证 Looped Transformer / latent reasoning 路线是否进入产业主流;第三,Meta 和其他大公司的"蒸馏员工"条款在行业的扩散速度,以及员工的实际反应是否影响 AI 训练质量,这是一个田渊栋明确标记为"效用存疑"的实验,观察窗口就是这一到两年内这批模型的实际表现。
---
原播客来源:硅谷101《再访田渊栋:46.5亿美金估值的RSI,与AI自进化|Neolabs特辑【101视频播客】》
原播客:[https://www.youtube.com/watch?v=F7oNfszczVc](https://www.youtube.com/watch?v=F7oNfszczVc
节目时长:约 90 分钟
本文为基于公开播客内容的整理与注解,保留了主要观点引用和关键背景注记。