本文经原作者授权转载,版权归原作者所有。原作者:Xudong Han(@Xudong07452910)。查看原文 →
你刚装好 Codex,打开终端输入 `codex`,看它读代码、改文件、跑命令,感觉已经挺厉害了。
但你很快会遇到几个小别扭。
它有时候想得不够深,复杂重构看一眼就开改;有时候又太谨慎,跑个普通命令也来问你;还有时候终端一清屏,前面输出全没了。更要命的是,新手最容易把权限开太大,让 AI 在你电脑上到处乱跑。
好消息是,Codex 的核心习惯可以用一个配置文件管住。
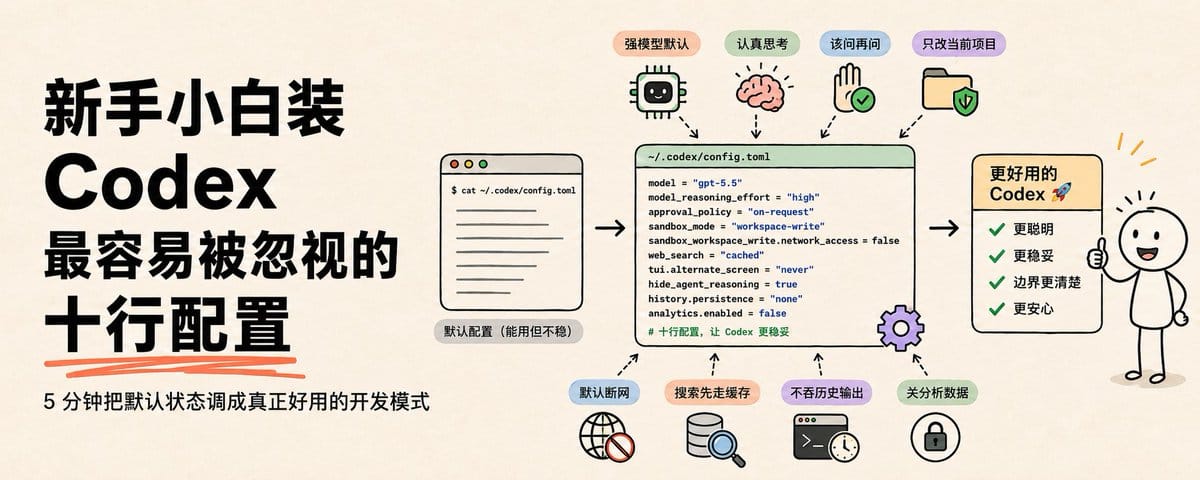
Claude Code 那套是往 `~/.zshrc` 里写 `export`,Codex 不一样。Codex 主要读的是这个文件。
~/.codex/config.toml你只要把下面 10 行写进去,就能让 Codex 变得更适合日常开发。
- 让它默认用强模型,不要每个新会话重新选
- 让它多想一步,别刚看两眼就动手
- 让它该问时问,不要每一步都卡你
- 让它只能改当前项目,不要摸你整个电脑
- 让命令默认断网,避免脚本偷偷联网
- 让搜索先走缓存,少被实时网页带偏
- 让终端别一进来就吃掉历史输出
- 让界面别被推理日志刷屏
- 让会话记录不要长期落盘
- 关掉本机分析数据,新手也能更安心
如果你完全没碰过 TOML 配置,别紧张。你可以把它理解成一个比 JSON 更好读的设置表:左边是开关名字,右边是你想要的值。
使用 Claude Code 的朋友可以搭配下面文章一起看
下面一条一条来。
1.默认用强模型
model = "gpt-5.5"痛点,你明明想让 Codex 改一个真实项目,它却像在做小练习,改得快,但不够稳。
原因,Codex 可以切不同模型。模型越强,越适合读大项目、追复杂 bug、做跨文件重构;模型越轻,越适合简单问答和小修小补。新手最大的问题不是不会切模型,而是根本不知道当前在用哪个。
解法,把默认模型写死。日常开发先用 `gpt-5.5`,遇到只是问概念、查命令、写小脚本,再临时切更轻的模型也不迟。
这不是说永远只能用一个模型。启动时可以用 `codex -m 模型名` 临时覆盖,配置文件只是给你一个稳定默认值。
2.让它认真思考
model_reasoning_effort = "high"痛点,让 Codex 重构一个模块,它立刻开始动手,结果越改越散,最后你还得自己收拾。
原因,Codex 的推理强度可以调。默认值通常照顾速度和成本,但复杂工程问题最怕“反应快”:没看清依赖关系、没跑完搜索、没想清楚边界,改得越快越容易埋坑。
解法,把 reasoning effort 拉到 `high`。它会更愿意先理解项目,再下手改代码。
可选值通常包括 `low`、`medium`、`high`、`xhigh`。日常 `high` 比较均衡;特别硬的架构问题再临时切 `xhigh`。
3.该问时问,别一直问
approval_policy = "on-request"痛点,你让 Codex 跑测试,它问;让它装依赖,它问;让它看个文件,它还问。用久了,人比 AI 还累。
原因,Codex 有审批策略,决定它什么时候必须停下来等你点头。太严格会拖慢工作,太宽松又容易让新手把危险命令放过去。
解法,用 `on-request`。普通读文件、跑安全命令不反复打扰你;涉及联网、越权、可能破坏文件的动作,再让它来问。
不建议新手把它改成 `never`。那是自动化脚本场景用的,不是日常边看边改项目用的。
4.只允许改当前项目
sandbox_mode = "workspace-write"痛点,你只是想让 Codex 改当前仓库,心里却总担心它会不会碰到桌面、下载目录、SSH key 或其他项目。
原因,AI 写代码时会跑 shell 命令。没有边界的 shell,就等于让它在你电脑上自由行动。新手最应该先学的不是“怎么放权”,而是“怎么设边界”。
解法,使用 `workspace-write`。Codex 可以读文件,可以在当前工作区里写文件,但不能随便改整个电脑。
千万别把 `danger-full-access` 当性能优化。那是解除沙盒,不是让 Codex 变聪明。
5.命令默认不要联网
sandbox_workspace_write.network_access = false痛点,某个测试脚本、安装脚本、构建脚本偷偷访问外网,你不知道它传了什么,也不知道为什么环境突然变了。
原因,真实项目里的命令不一定都干净。`npm install`、`curl`、`pip`、`postinstall`、Docker 构建,都可能触发网络行为。对新手来说,默认断网比默认放开更稳。
解法,在 workspace-write 沙盒里显式关闭网络。Codex 真需要联网装依赖或查资源时,再让它单独请求权限。
这不会关闭 Codex 自己和模型的通信。它限制的是 Codex 代你运行的本地命令。
6.搜索先用缓存,不要默认冲进实时网页
web_search = "cached"痛点,你问一个技术问题,Codex 引了一个刚刷到的网页,结果网页内容过期、带广告、甚至夹着诱导 AI 的奇怪文字。
原因,实时网页搜索虽然新,但也更脏。网页不是文档,里面可能有无关内容、营销内容、SEO 内容,甚至 prompt injection。
解法,默认用 `cached`。这是 OpenAI 维护的搜索缓存,适合大多数日常问题。只有你明确需要“今天刚发生什么”“最新价格”“刚发布的版本”,再用 `--search` 或把它临时改成 `live`。
三档可选:`cached`、`live`、`disabled`。公司内网或敏感项目里,可以直接设成 `disabled`。
7.终端别再吞历史记录
tui.alternate_screen = "never"痛点,Codex 一打开就是全屏界面,退出以后前面的终端输出没了;你想往上翻一下刚才的命令记录,发现什么都没有。
原因,很多 TUI 工具会使用 alternate screen,也就是终端的“临时全屏缓冲区”。它看起来干净,但不适合新手排查问题,因为你很难回头复制前面的输出。
解法,设成 `never`。Codex 会更像普通命令行程序一样,把内容留在终端滚动历史里。
如果你喜欢全屏沉浸界面,把这一行删掉就行。
8.界面别被推理日志刷屏
hide_agent_reasoning = true痛点,你只是想看 Codex 最后改了什么、下一步要做什么,结果界面里夹着一堆 reasoning event,看起来很专业,但新手越看越乱。
原因,Codex 会把部分推理摘要或推理事件展示在 TUI 和 `codex exec` 输出里。对老手来说,这些信息有时能帮助判断它在想什么;对新手来说,它更多时候只是噪音。
解法,把 reasoning event 隐藏掉。Codex 还是会正常思考、正常调用工具,只是界面更干净,你更容易盯住真正重要的东西:它准备做什么、它改了什么、它有没有报错。
这不是让 Codex “少思考”,只是少显示过程信息。真正控制思考强度的是第 2 条 `model_reasoning_effort`。
9.会话记录不要长期落盘
history.persistence = "none"痛点,你在公司项目里问 Codex 问题,里面可能有文件路径、报错日志、客户字段名、内部接口名。即使这些只是存在你本机,也不一定想长期留在历史记录里。
原因,Codex 可以把会话转录保存到本地 `history.jsonl`,方便之后回看或恢复会话。但隐私敏感场景里,“方便”有时候就是“多留了一份东西”。
解法,关闭会话历史持久化。这样 Codex 不会把会话转录长期写进本地历史文件,更适合公司代码、客户项目和不想留痕的临时排查。
副作用也很直接:历史回看和部分恢复体验会变弱。如果你更看重续接旧会话,把这一行删掉即可。
10.关掉本机分析数据
analytics.enabled = false痛点,你在公司项目里用 Codex,不想额外发送任何分析数据;哪怕只是使用统计,也希望先关掉再说。
原因,Codex 支持本机 analytics 开关。对个人玩具项目无所谓,但对商业代码、客户项目、论文数据,新手最稳的策略是先少传一点。
解法,把 analytics 关掉。模型请求本身还是会正常工作,但本机分析数据不会按默认策略开启。
如果你还想连 `/feedback` 反馈入口也关掉,可以额外加一行:`feedback.enabled = false`。
一次粘贴版
前 6 行建议大多数新手直接使用;后 4 行偏体验和隐私,如果你想保留历史记录、喜欢看推理过程,可以删掉对应行。
打开或新建这个文件。
~/.codex/config.toml把下面 10 行放进去。
# Codex 新手稳妥配置(2026 年 5 月)
model = "gpt-5.5"
model_reasoning_effort = "high"
approval_policy = "on-request"
sandbox_mode = "workspace-write"
sandbox_workspace_write.network_access = false
web_search = "cached"
tui.alternate_screen = "never"
hide_agent_reasoning = true
history.persistence = "none"
analytics.enabled = false如果文件不存在,可以先创建目录和文件。
mkdir -p ~/.codex
nano ~/.codex/config.toml保存以后,重新打开一个 Codex 会话即可生效。
另一种临时用法
如果你只是想本次启动临时试一下,不想改配置文件,也可以这样写。
codex -m gpt-5.5 -c model_reasoning_effort=\"high\" -s workspace-write -a on-request优点,不污染长期配置。
缺点,每次都要敲一长串,新手很容易忘。
所以日常还是推荐写进 `~/.codex/config.toml`。
几个常见疑问
Q,我不是程序员,`~/.codex/config.toml` 怎么打开?
A,macOS 可以在终端输入 `open ~/.codex`,然后用文本编辑器打开 `config.toml`。Linux / WSL 可以输入 `nano ~/.codex/config.toml`。如果提示目录不存在,先跑 `mkdir -p ~/.codex`。
Q,Windows 用户怎么办?
A,如果你用 WSL,就跟 Linux 一样,文件在 WSL 里的 `~/.codex/config.toml`。如果你原生 Windows 跑 Codex,仍然找 Codex 的配置目录;另外可以在配置里加 Windows 专用沙盒设置:`windows.sandbox = "elevated"`。
Q,我已经有 `config.toml` 了,可以直接覆盖吗?
A,不建议。先看里面有没有 `model`、`sandbox_mode`、`approval_policy` 这些字段。已有同名字段就改值,没有再追加。整个文件覆盖掉,可能会把你的 MCP、插件、项目信任配置一起删掉。
Q,为什么不推荐 `danger-full-access`?
A,因为它跳过本地沙盒边界。新手一旦把它设成默认,就等于让 Codex 运行命令时拥有过大的文件系统权限。真需要全权限时,临时开一次就够了,不要写进长期配置。
Q,`web_search = "cached"` 会不会不够新?
A,会。它适合日常技术问题,但不适合查今天刚更新的版本、价格、新闻、政策。遇到这类问题,用 `codex --search` 开一次 live search 更合适。
Q,想恢复默认怎么办?
A,把你加的那几行删掉,重新开 Codex 就行。配置文件不会改坏项目代码。
官方配置文档看这里:[developers.openai.com/codex/config-basic](https://developers.openai.com/codex/config-basic) 和 [developers.openai.com/codex/config-reference](https://developers.openai.com/codex/config-reference)。
新手用 Codex,最重要的不是把权限开满,而是让它在一个清楚的边界里认真工作。模型、思考、审批、沙盒、隐私和界面噪音,先把这些基础项站稳,体验会立刻不一样。