
本文经原作者授权转载,版权归原作者所有。原作者:Xudong Han(@Xudong07452910)。查看原文 →
上个月,我把自己的个人 agent 底层框架整个换了一遍。
从之前框架底层使用的 CrewAI 迁移到 Claude Agent SDK,再到后来支持多家模型厂商,500 多个单元测试重写,十几个 Skill 脚本逐个适配,记忆系统推倒重来。整个过程断断续续搞了一个多月,中间有好几个凌晨是对着报错信息发呆的。
你可能会问,为什么不直接用 OpenClaw 或者 Hermes Agent?
说真的,我也问过自己这个问题。不止一次。
每次刷推特看到有人晒自己用 OpenClaw 三分钟搭好一个全能助手,或者 Hermes Agent 的闭环学习又进化出了什么神奇技能,我都会停下来想,我是不是在造一个没必要的轮子。
但我还是选择了自己搭。
今天想聊聊为什么。
---
先说背景。我做的这个 agent 叫 EvoPaw (https://github.com/hxdflying/EvoPaw),小爪子,是一个飞书上的工作助手。它能帮我处理文档、搜索信息、管理日程、真值做学术相关工作,基本上能覆盖我日常工作里七八成的重复劳动。
它不是从零开始写的。最早的版本其实是跟着一个 简单的 agent 课程项目,用的是 CrewAI 框架加上阿里云的沙盒环境。那个版本能跑,但很粗糙,像一个毛坯房,能住但谈不上舒适。
后来我一点一点地加东西。加了记忆系统,让它能记住我们之前聊过什么。加了定时任务,让它每天早上自动给我推送信息。加了语音消息支持,加了多模态图片理解,加了十几个专用技能。
到后来,底层框架已经完全跟最初的课程版本不一样了。
这个过程,其实就是我想说的第一个点。
你不需要一开始就搭一个完美的 agent。你只需要搭一个能跑的,然后让它跟着你的需求一起长大。
---
推特上有个观点我特别认同,是 @Pluvio9yte 说的。他从 OpenClaw 切换到 Hermes Agent,详细记录了那个过程里的「注意力税」,每次新框架出现,你都要花大量时间重新配置 prompt、记忆系统、工作流。永远卡在配置层,没有人真正跑到应用层。
这种感觉我太熟悉了。
我观察了这一两个月的个人 agent 生态,OpenClaw、Nanobot、Hermes Agent,基本上每隔一个月就有一个「更好的」出现。然后你就陷入一个循环,花两天配置好环境,花三天调好 prompt,刚觉得顺手了,又有人告诉你,「嘿,那边出了个新的,比你现在用的强太多了」。
然后你又开始迁移。
然后你又花了两天配置环境。
然后你又花了三天调 prompt。
循环往复。
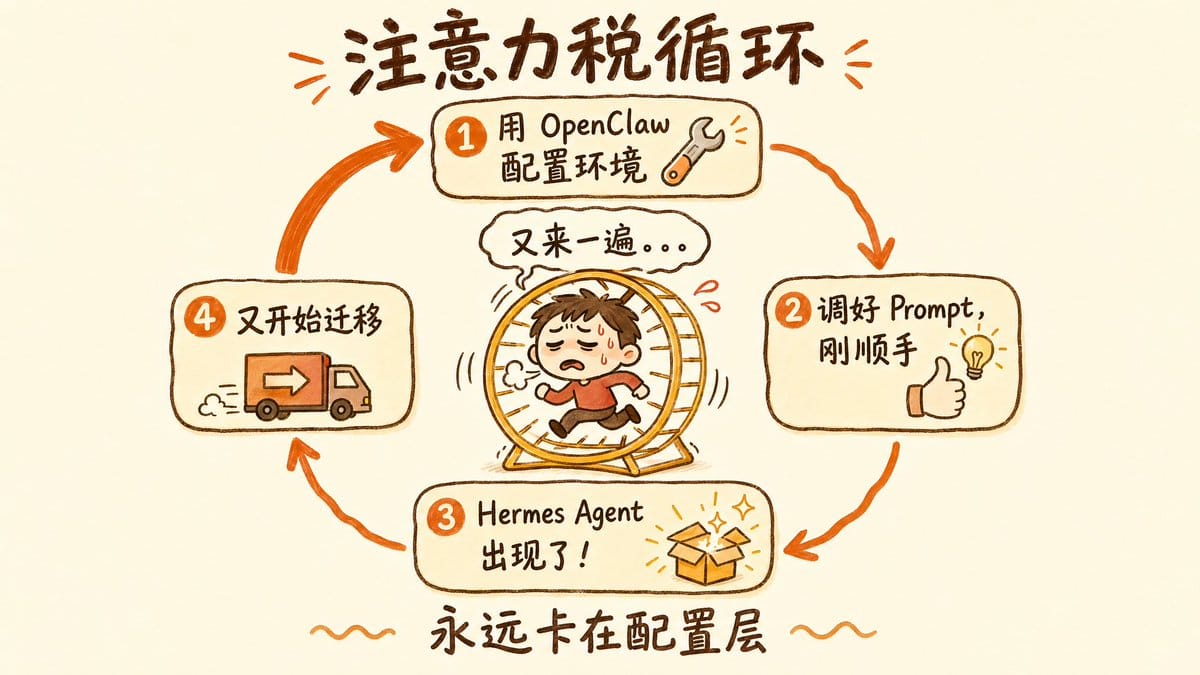
我觉得这里面有一个根本性的问题,就是当你的 agent 搭在别人的框架上,你就把「进化的主动权」交出去了。框架升级你得跟着升级,框架换了你得跟着换,框架不维护了你得重新选型。你以为你在用工具,其实你在被工具用。
而当你自己搭的时候,情况完全不一样。
我的 EvoPaw 刚开始从 CrewAI 迁移到 Claude Agent SDK,听起来是一次大动干戈的重写。但实际上,因为我自己设计了模块边界,飞书接入层完全没动,技能系统的接口没变,记忆层的数据格式向后兼容。变的只是中间的 agent 编排层。后来我又把底层拆成了多 provider 架构,想用 Claude 就用 Claude,想换 Kimi 或者别的模型也随时能切,编排层以上的代码一行没动。
这种「想换哪层就换哪层」的自由度,是你用别人的框架很难拥有的。
---
第二个我想说的点,是关于「偷」。
坦率的讲,我写 EvoPaw 的过程里,研究别人的开源项目花的时间可能比写代码还多。
我认真读过 Hermes Agent 的源码。它教会我一件事,怎么让技能脚本不关心自己被装在哪个目录里。听起来是小事对吧?但当你的 agent 有十几个技能的时候,这个「小事」会变成噩梦。Hermes Agent 用了一套很聪明的占位符机制来解决这个问题,我直接偷过来了。
我读过 Nanobot 的代码,学了它的「依赖预检」思路。就是在一个技能真正执行之前,先检查它需要的东西全不全,缺了就跳过,而不是跑到一半报个错把你吓一跳。这个设计太优雅了,也偷过来了。
我读过 Pi-mono,一个 TypeScript 写的 agent 框架,它的多 provider 抽象做得特别干净。我没有直接用它的代码,但我学了它的分层思路,把「provider 选择」和「请求构造」拆开,这样以后想换模型厂商不用动整个 agent 逻辑。
我甚至读过 yoyo-evolve,一个用 Rust 写的会自我进化的 coding agent。它让我意识到一件事,EvoPaw 当时最大的问题不是「只支持 Claude 模型」,而是「整个运行时都绑死在 Claude Agent SDK 上」。这两个问题看起来像一回事,其实完全不同。前者是 API 层的问题,后者是架构层的问题。想通这一点之后我就动手拆了,把 provider 层独立出来,现在 EvoPaw 不绑死任何一家,Claude、Qwen、其他 OpenAI 兼容的模型都能接。
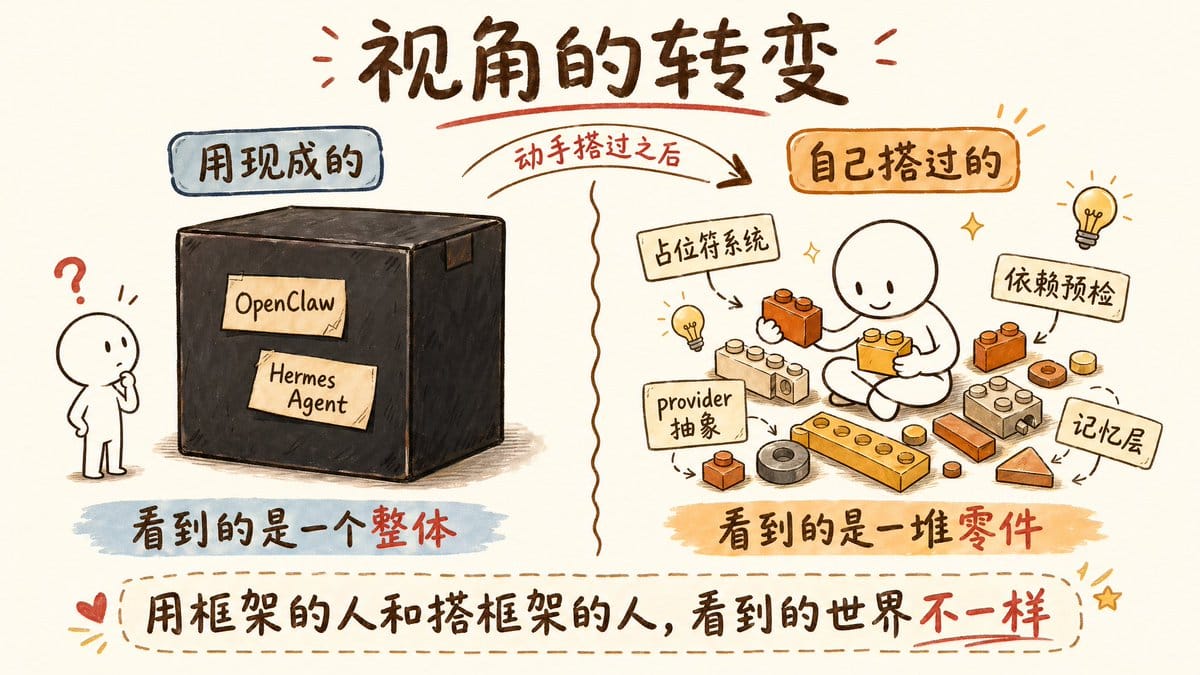
你看,这就是自己搭 agent 的一个隐藏好处。当你亲手搭过一遍之后,你再去看别人的方案,你能看到的东西完全不一样。你不会再问「这个框架好不好用」,你会问「这个框架在这一层的设计比我的好在哪里,我能不能只偷这一层」。
这种拆解和重组的能力,只有动手搭过的人才有。
用现成框架的人看到的是一个整体,自己搭过的人看到的是一堆可以拼装的零件。
第三个点,也是很多人最关心的,成本。
我知道很多人不自己搭的原因就一个,觉得太难了。要懂 LLM 编排,要懂工具集成,要懂记忆系统,要懂异步编程,要懂 Docker 隔离... 光是列出来就让人头大。
但我想说一个可能有点反直觉的事实,在 2026 年,搭一个个人 agent 的门槛已经低到离谱了。
你想想看,你用 Hermes Agent 跑了两个礼拜,挺顺手的。但有一天你发现它每次回复都巨长,你明明只想要一句话的结论,它非得给你写三段分析。你烦了。然后你打开它的 system prompt 文件,把「请详细解释你的推理过程」改成「用一句话回答,除非我追问」。保存,重启。
就这么一句话的事。
你刚刚「改」了你的 agent。不需要写代码,不需要懂编程。就是打开一个文件,改了一行字。
然后过几天你又发现,它不认识你公司内部用的缩写,每次都得给它解释一遍。你索性新建一个文件,把常用缩写和含义写进去,告诉 agent「回答前先看看这个」。又搞定了,你刚刚给你的 agent 加了一块「记忆」。
到这一步,你做的所有事情都跟「写代码」没有任何关系。
再往后,你可能想搞点更骚的操作了。比如让它每天早上 9 点自动给你推送今日待办。这一步确实得碰代码了,但问题是,2026 年了,你不需要自己写啊。你打开 Claude Code,跟它说「帮我写一个脚本,每天早上 9 点从我的日历里拉取今天的待办事项,发给我」。它帮你写好了,你粘贴过去,跑起来了。
这玩意就叫 vibe coding。你负责想,AI 负责写。
我自己的 EvoPaw 有一大堆功能就是这么来的。我跟 Claude Code 说「我想让它能读 PDF」,它帮我写了个 PDF 解析的 Skill。我说「我想让它记住我们聊过的东西」,它帮我搭了记忆系统的框架。后来越搞越上头,Word、Excel、PPT 的处理也加上了,再后来连飞书的云文档、日历、群消息都能直接操作了。我现在在飞书上甩给它一份文档,它能帮我读完、提炼要点、顺手存进记忆里,下次再聊相关的东西它自己就能想起来。
我有时候自己都觉得有点离谱,这些功能我都没有正儿八经坐下来「写」过,就是一轮一轮跟 Claude Code 聊出来的,我负责说「我要什么效果」,它负责实现,我再调细节、测试、修 bug、迭代。
说实话这个过程也不是完全无痛的,我也有好几个凌晨在 debug,也有过「这破玩意怎么又挂了」的崩溃时刻。但重点是,每一步的跨度都不大。你不是从「什么都不会」一步跳到「搭出一个完整 agent」,你是从改一行 prompt 开始,一点一点地,把越来越多的东西变成自己的。
改着改着,你就有了自己的 agent。你甚至说不清是哪一刻从「用别人的」变成了「用自己的」。就是鬼使神差的,它就变成你的了。
我的小爪子就是这么长出来的。最初是课程项目,后来是自用工具,再后来是一个我每天都在用、每周都在改的系统。
而且说到钱的话,真的没你想的那么贵。如果只是日常办公,用国产的API 费用每天也就十几块钱人民币,部署就一台能跑 Docker 的机器,我直接跑在自己工作站上,连服务器都不用租。
---
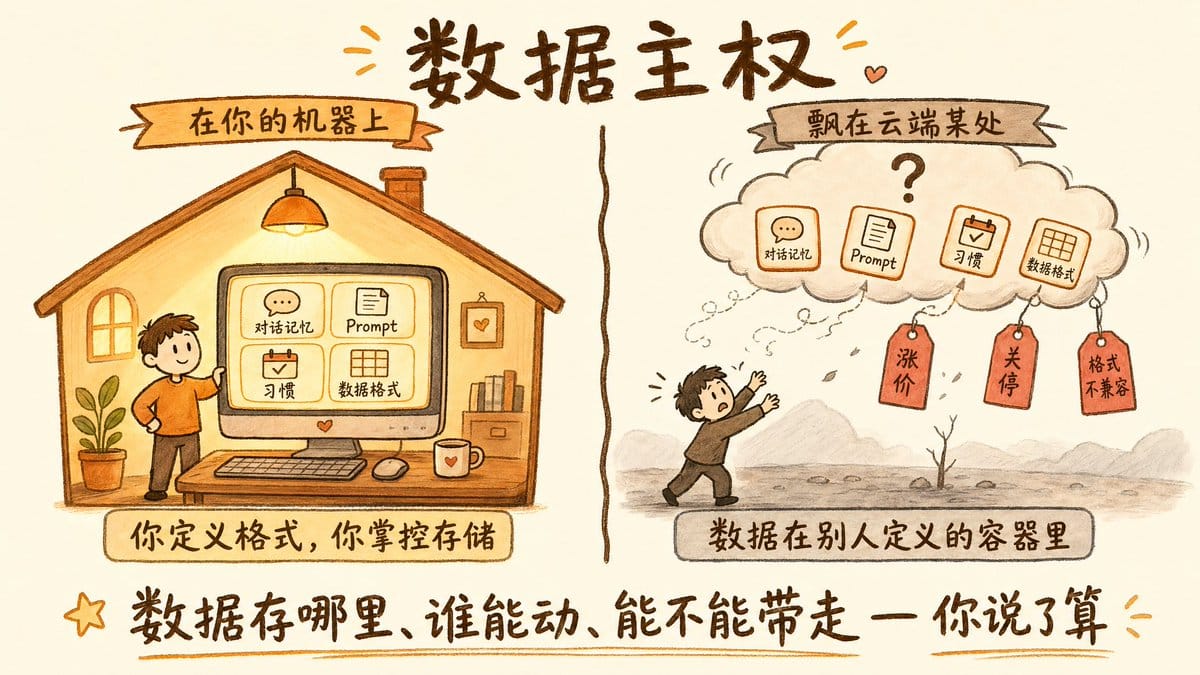
有个说法我很喜欢,「If it doesn't run on your machine, you don't own it」。如果它不在你机器上跑,你就不拥有它。
这句话放在个人 agent 这件事上特别准确。
你想想看,一个用了两三个月的 agent,它知道什么?它知道你每天几点开始工作,知道你习惯先看什么后看什么,知道你跟哪些同事聊得最多,知道你最近在焦虑什么项目。如果你用它管日程,它知道你每一天的行踪。如果你用它读文档,它知道你公司内部在讨论什么。
这些数据加在一起,比你的浏览器历史还私密。
我不是说 OpenClaw 或 Hermes Agent 不安全,它们都是很优秀的开源项目,社区也很活跃。但这块需要注意一下,「开源」和「你能控制数据」是两回事。代码开源不代表你的对话记录、记忆快照、个人偏好存在你自己的机器上。有些框架的记忆系统会把数据同步到云端,有些会在你不知情的情况下把上下文发给第三方 API 做处理。你以为数据在本地,其实早就飘到你不知道的地方去了。
还有一个更深层的问题。
说实话,OpenClaw 和 Hermes Agent 之间的数据迁移做得还不错,对话记忆、prompt 这些基本能带走。但你有没有想过一个事,你的数据能在它们之间迁移,是因为它们之间恰好兼容。如果有一天你想换到一个不在这个生态圈里的框架呢?或者更极端一点,如果这两个项目有一天不维护了呢?
你积累了半年的记忆、习惯、工作流,全都存在别人定义的数据格式里。能不能迁移,不取决于你,取决于下一个框架的作者愿不愿意做兼容。
这个感觉有点像你所有的照片都存在某个云相册里,它免费的时候挺好用,有一天它涨价了或者关停了,你才发现导出功能藏在一个犄角旮旯的地方,导出来的格式还不一定能被别的工具识别。
但如果你自己搭的呢?数据格式你定的,存储位置你定的,想迁移的时候你只需要换中间的 agent 编排层,记忆数据原封不动地带着走。我的 EvoPaw 从 CrewAI 换到 Claude Agent SDK 再到多 provider,换了两次底层,记忆层的数据格式一直向后兼容,一条对话记录都没丢。因为这个格式是我自己设计的,我想怎么存就怎么存,不用看任何人的脸色。
数据存在哪里,你决定。用什么模型,你决定。哪些信息进入 LLM 的上下文,哪些不进入,你决定。什么时候升级什么时候不动,你决定。
这种掌控感,不是技术问题,是主权问题。
---
回到最开始的问题。OpenClaw 和 Hermes Agent 已经够好了,为什么还要自己搭?
我的回答是,你不是在搭一个工具,你是在搭一个理解你的系统。
工具可以买,可以下载,可以切换。但一个真正理解你工作方式的系统,只有你自己能搭出来。因为这个世界上没有第二个人跟你有完全一样的需求,完全一样的工作流,完全一样的偏好。
OpenClaw 和 Hermes Agent 提供的是一个很好的起点。但起点不是终点。
我自己的建议是这样的,不一定对,但可以参考。
如果你是第一次接触个人 agent,先用 OpenClaw 或者 Hermes Agent 跑起来就行。别想太多,先感受一下「有个 AI 助手 24 小时在线」是什么体验。这一步花不了一个小时。
然后认认真真用它两周。别光觉得酷,要带着挑剔去用。它哪次回答让你觉得「对对对就是这个」,哪次让你觉得「你能不能别废话」,哪个需求你试了半天它就是搞不定。把这些感受记下来。
记下来之后,你就知道从哪开始动手了。
话太多?改一行 prompt,前面说过了,就是改一句话的事。不了解你的工作?给它加个文件。想让它主动找你?打开 Claude Code 跟它说你想要啥效果,让它帮你写。
你不需要一次到位。今天改个 prompt,下周加个功能,下个月可能觉得底层不够用了,那就换一层。或者不换也行,就在现有框架上接着折腾。
反正核心就一件事,让这个系统一点一点变成你自己的。
不需要你是程序员。2026 年了,你有 Claude Code、Codex。你负责想,它们负责写。
顺着上面的再聊聊,如果你本身就有一些编程基础,其实还有一条更直接的路。去看看 Pi 或者 Nanobot 这类相对轻量的 agent 框架,代码量不大,结构也干净,很适合拆开来学。你不需要全盘照搬,就是读一读它们的分层设计,provider 怎么抽象的,工具怎么注册的,记忆怎么持久化的。看明白了之后,挑你觉得有用的部分偷过来,嫁接到你自己的项目上。我前面说的「偷」,其实就是这个意思。这条路走起来会更快,但也更自由,因为你从一开始就知道每一层在干什么,想换哪层随时换。
---
我跟我的小爪子已经一起走过了一个多月。从最初那个只会转发消息的毛坯 bot,到现在能帮我读研报和论文、管日程、搜论文、自动推送每日科技,AI摘要等等的全能助手。
这中间重写过一次底层框架,研究过四五个开源项目的源码,写了十几份分析文档,踩了无数的坑。
但每一步都是我自己选的方向,每一个改动都是因为我真的需要。
不是框架告诉我应该怎么用,是我告诉这个系统它应该怎么为我工作。
这个差别,只有自己搭过的人才能体会。
大时代啊,朋友们。我们正站在一个每个人都能拥有自己的 AI 助手的时刻。不是用别人做好的,而是自己搭的,按自己的意思来的,跟自己一起进化的。
这个机会,我觉得值得每个人认真想想。
可能有些想法还不成熟,但我已经毫无保留地分享了。希望对你有一点点启发。
对了,说了这么多「为什么要自己搭」,肯定有人想问,那到底怎么搭?
别急,下一篇我会把我搭 EvoPaw 的完整过程拆开来写,从你刚拿到一个相对简易的 agent 到现在这个能帮我干很多活的助手,中间每一步怎么做的,踩了哪些坑,用了哪些工具,全部掰开揉碎讲一遍。不管你是零基础还是老手,保证你看完之后能动手。
谢谢你看我的文章,我们下次再见。