
本文经原作者授权转载,版权归原作者所有。原作者:小互(@xiaohu)。
阿里通义实验室 Wan 团队放出 Wan Streamer 模型,一个能跟你实时视频通话的真人 AI。
我们已经习惯了跟 AI 打字、语音聊天。Wan Streamer 往前走了一步,它能跟你视频通话:你这边有摄像头和麦克风,它那边实时生成一张会说话的脸,看着你、回应你。
效果展示:
📹 视频① · 中文日常通话 —— 在此插入视频。中文 · 暖色室内视频通话:聊刮胡子、在家办公、想看一部特效不错的新动作片。清晰自然男声。
1 · 这是什么:一个模型跑通实时音视频对话
Wan Streamer v0.1 是一个实时音视频交互模型。能实时对话的 AI 现在不少,但能一边看你的脸、一边听你说话、一边开口回应、自己还自带一张会动的脸的,几乎没有。Wan Streamer 把这件事压进了一个模型里。
它在同一个 Transformer 里同时处理语言、音频、视频的输入和输出,做到亚秒级的全双工音视频对话:模型自己算出一段回应大约只要 200 毫秒,加上网络往返后总延迟约 550 毫秒。
为什么值得看:现在能实时对话的系统分两类,一类响应快但只出声音、没有可见的脸(GPT-4o Realtime、豆包、Gemini Live),另一类有脸但靠外部 ASR、语言模型、TTS、动画一串模块拼出来。官方称 Wan Streamer 是唯一用单个端到端 Transformer 同时吐出同步音视频、且总延迟压在 1 秒内的模型。
几个关键数字:
- ~200 ms — 模型侧响应延迟
- ~550 ms — 总交互延迟(200ms 模型侧 + 350ms 网络往返)
- 160 ms — 25fps 下最短的流式处理单元
- 192p — v0.1 分辨率,端到端设计的概念验证
把总延迟 550ms 拆开看:模型本身只占 200ms,剩下 350ms 是网络往返。也就是说,纯模型的反应速度,比你读到的总延迟更快。
2 · 旧办法为什么慢:一道道接力,每步都在等
旧办法慢,是因为它们是一串独立模型拼起来的流水线:语音先转成文字(ASR),文字喂给语言模型想答案(LLM),答案再合成语音(TTS),最后驱动一张脸动起来(动画渲染)。
音视频输入 → ⏳ASR 识别 → ⏳LLM 想答案 → ⏳TTS 合成语音 → ⏳动画渲染 → 输出
每过一道工序都要等上一道交货,等待时间一段段累加,识别和口型对不齐的误差也一路累积。每个箭头都是一次等待 + 一次误差累积;模块之间靠文字当中转桥;多数系统只出语音,或者把一张脸勉强拼出来,且不报告端到端时延。
Wan Streamer 是端到端单模型:音视频输入 →「一个 Transformer」(感知 · 推理 · 规划 · 生成 一起做)→ 同步音视频输出。没有接缝,等待时间坍缩;轮次管理、被打断、长程一致性,作为一个连贯行为一起学出来。
打个比方:端到端像一个人自己听完直接开口;级联像传话游戏,每过一手都慢一拍,还可能把话传错。中间那层把语音/视频先转成文字、再用文字驱动下游——文字就是各模块之间隐藏的中转桥,桥越多越慢、越容易错。Wan Streamer 不要这个中间桥,模态之间直接耦合。
原文给这件事下了一个判断:实时音视频交互不是「多模态理解」加「多模态生成」的简单相加,它本质上是全双工的,所以可流式性是一种建模约束,而不只是上线后的工程优化。建在离线编码器、双向解码器、回合制对话之上的系统,光靠工程调优也补不出真正的低延迟全双工。
【📹 视频② · 即兴模仿 —— 在此插入视频。中文 · 明亮白色室内。聊 CP、娱乐圈八卦、周星驰《功夫》,最后模仿经典笑容,轻松愉快女声】
3 · 核心创新:一个模型从听到说全包了
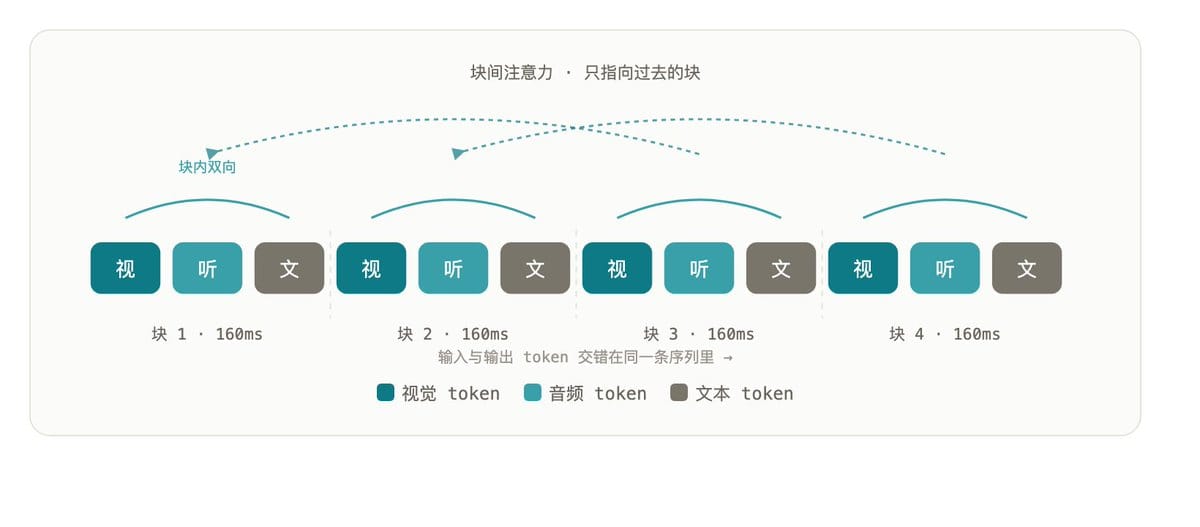
Wan Streamer 的内核只有一句话:把视觉、音频、文本的输入 token 和输出 token,交错排成同一条序列,交给一个 Transformer 处理;用 block-causal attention 协调,让它边来边算地往外吐。
单个端到端 Transformer 取消了外部的 VAD、ASR、语言模型、TTS、动画、视频生成等模块,把感知、推理、回应规划、语音与视觉生成、响应时机、轮次管理全放进同一个持久状态里联合优化。低延迟、全双工、同步音视频这三件事,根都在这里。
模型把交互看成一条连续的因果流:你的观测和它的回应,一起更新当前上下文。语言回应是一串离散 token,用 next-token 预测训练;音频和视频回应活在连续的 latent 空间里,用条件 flow matching 联合生成,让语音、动作、外观、场景演化作为一个耦合整体一起去噪,而不是各生成各的再拼。
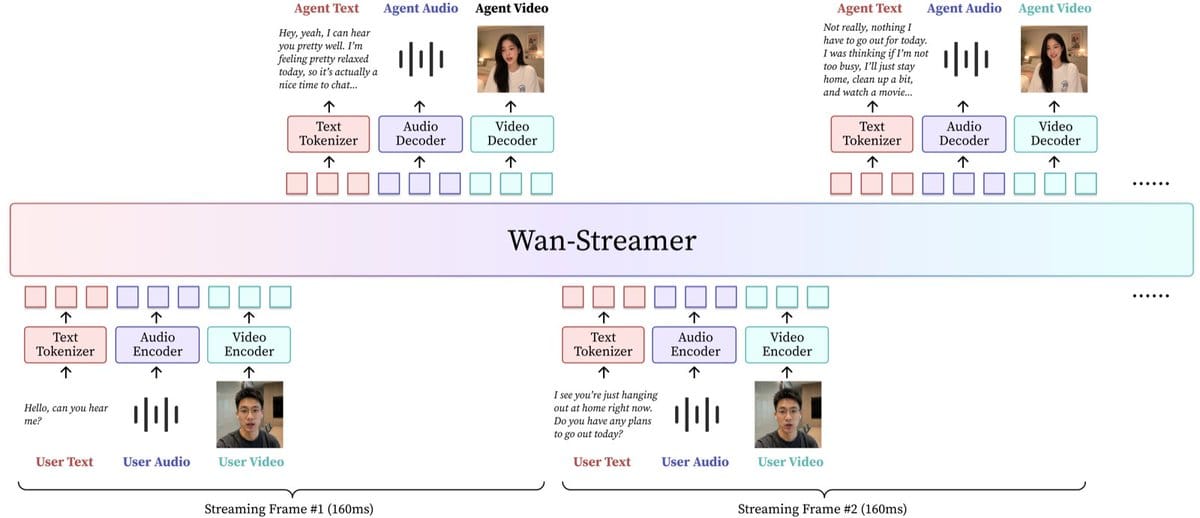
为了撑住这条流,整栈从设计之初就是因果的:严格因果音视频 VAE、因果音视频编码器、因果音视频解码器,以及由 block-causal attention 协调的时序因果 Transformer。被这套设计抹掉的外部模块是:外部 VAD、ASR 识别、外部语言模型、TTS 合成、动画模块、视频生成模块。
4 · 怎么做到边听边说、随时能打断
人和世界的交互天生是流式、全双工的:我们不是先听完、再单独想、最后才答,而是一边看一边听一边说、随时停顿和打断,感知和表达在音视频的时间尺度上重叠发生。实时交互模型也得长成这样。
因果编码器 + 因果解码器 + 低延迟多模态 token 调度,让 25fps 下的流式单元短到 160ms:输入的语音视频立刻影响输出,生成的音频和视觉状态在解码之前就耦合好,而不是事后修补。于是它能边听边说,你说话时它仍在听、被打断还能调整。
这套机制靠的是 block-causal attention:它把一小块(比如 160ms 的音视频片段)当成一个处理单位,块内部的 token 可以互相看(双向),但一个块只能看见过去的块、看不到未来的块。块 3 一到就能开算,因为它只依赖块 1、块 2,不用等未来的块 4——这就是流式生成。
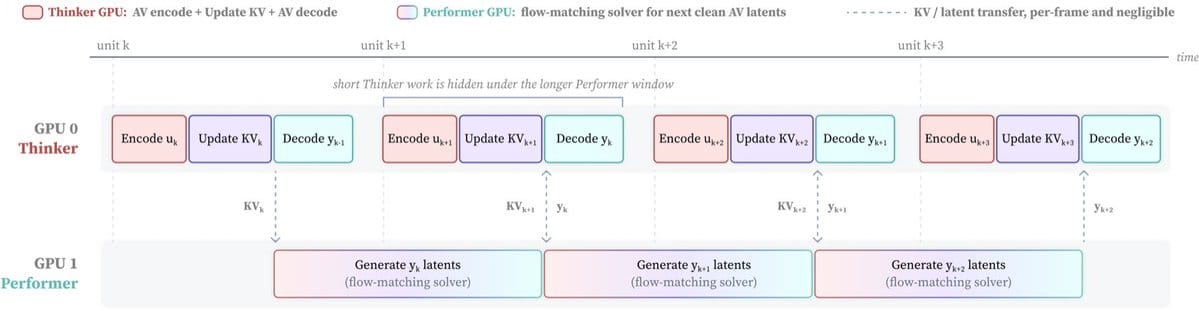
部署细节:thinker–performer 怎么把延迟压到 200ms。Wan Streamer 训练时是单个端到端模型;实时部署时,同一个模型拆成跨两张 GPU 的 thinker–performer 流水线,尽量让计算重叠。thinker 负责编码、语言预测与状态更新、KV-cache 构建,以及把上一单元解码成音视频并立即输出;performer 只负责为下一段跑 flow-matching 求解器。因为 performer 从不跑解码器、thinker 从不跑高成本求解器,解码和生成互不阻塞。只要 performer 耗时加通信耗时塞进一个 160ms 单元,就维持实时吞吐。
边听边说、随时能被打断,落到对话里就是这种自然感。这两段都是英文实时对话:
【📹 视频③ · 英文车内 —— 在此插入视频。英文 · 车内近景。女生说自己很累,感谢对方耐心陪伴,疲惫真诚女声。】
【📹 视频④ · 英文室内 —— 在此插入视频。英文 · 浅色室内近景。聊无意识刷手机、自动化习惯、关掉通知,自然女声。】
5 · 和别的系统比,快在哪、能做什么
下面两组延迟数字测的不是一回事,得分开看。上方一组是完整的端到端交互闭环(感知用户并产生回应),其中只有 Wan Streamer 同时输出视频;下方一组是数字人/音视频渲染器,只计到渲染阶段,不含它们依赖的外部语言模型、ASR、TTS,所以用户实际感受到的延迟比图里更高。
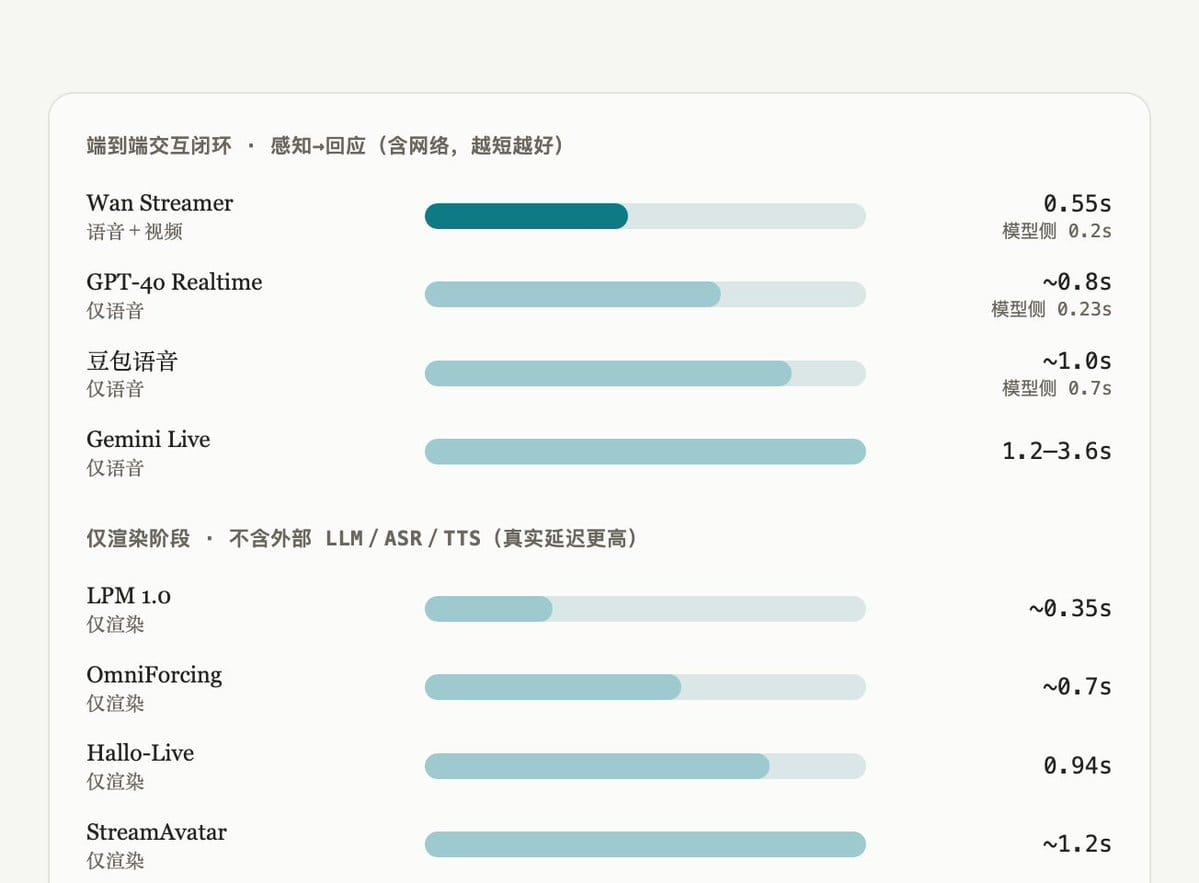
两组刻度各自独立,不能横跨两组直接比大小。数值取各系统公开报告中最接近的口径,混合了不同测量边界。
能力维度的覆盖如下,Wan Streamer 是唯一一行全部打勾的:
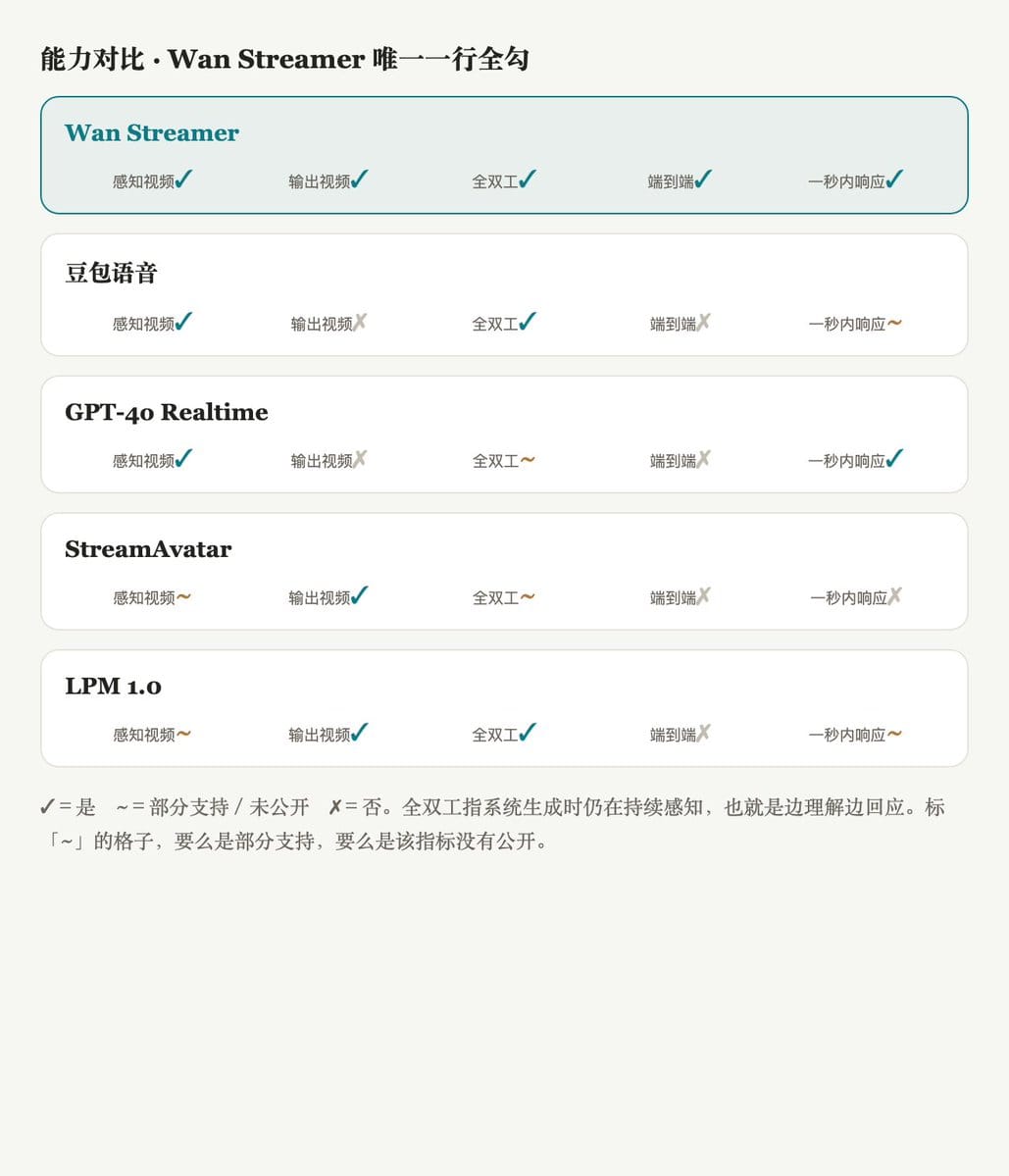
需要提一句:这五个维度是 Wan 按自己的能力边界定的;表里其他系统分属纯语音(GPT-4o、豆包、Gemini)和数字人渲染(StreamAvatar、LPM)两类,和 Wan 不是同一品类。这张表更适合看「各家覆盖了哪些点」,不是排名次——Wan 唯一全✓,更多是因为「维度由它来定」。
最后看一段完整的真实链路:一次真实联网对话的屏幕录制,能看到从感知到回应的全过程。
【📹 视频⑤ · 实时录屏 —— 在此插入视频。真实联网对话录屏:左边是本地用户画面,右边是 AI Agent 实时回应,下方同步滚动文本流】
注意:本项目还处于研究阶段,并没有上线,没有开放使用入口,只能当成「技术验证」看。
来源:
Wan Streamer v0.1 官方发布页(wan-streamer.com),
论文 arXiv:2606.25041