
本文经原作者授权转载,版权归原作者所有。原作者:Berryxia.AI(@berryxia)。
前段时间我写过一篇 OCR 选型实测,标题大概是:别瞎花钱了,我实测了 18 个文档、6 类场景,教你选对 OCR 模型。
可能有些朋友受限于自己的硬件设备,或者不太方便、没办法自己复现这一套工作流。
因此,我今天花上 10 分钟教大家如何将我开源好的这个 OCR 项目部署在本地。我也针对这个项目进行了一个实际的测试。
那篇文章里,我当时的判断很简单:OCR 不是一个模型打天下。
规整文本、手写、表格、双栏论文、公式文档,背后其实是几种完全不同的能力。
你要的是逐字还原,还是文档理解,你能不能联网,数据能不能出本地——这些问题比“哪个模型分数最高”更重要。
结果那篇刚写完没多久,PaddleOCR 又丢了一个新东西出来:PP-OCRv6。
我一开始其实没太在意。OCR 更新嘛,正常,每年都有。
直到我看到两行字:Tiny 版本只有 1.5MB,可以直接跑在浏览器里;Medium 档只有 34.5M 参数,OCR 专项任务上超过了 Qwen3-VL-235B。
兄弟们,这个真的这么吊?
一、蚂蚁打大象:34.5M 参数凭什么干翻 235B?

然后就是一个问题跟着另一个问题。
OCR 的未来,真的是越来越大的 VLM 吗?还是说这条轻量专用模型的路,反而有自己的护城河?
这篇文章是上一篇的续集,也算是我对这个问题的亲手验证。
我不是只跑了一个 Tiny demo,而是把 PP-OCRv6 Tiny、Small、Medium 三档都接进了本地 OCR Studio,沿用同一把 OmniDocBench 的尺子,加了四张真实世界难图,逐档切换模型实测了一遍。
说说我看到的结果,以及我自己对这件事的判断。
先说一下背景,免得有新朋友没接触过这个领域。
OCR 就是“把图片里的字变成可编辑文本”这件事。
PaddleOCR 是百度文心团队开源的 OCR 系统,在国内工程圈用得很广。作为文心多模态体系的重要组成部分,PaddleOCR 承担着端侧文字感知这一核心能力的输出。
PP-OCRv6 是这套系统的最新版,六月十一号刚发的。
现在主流的 OCR 有两条路。
一条是传统的检测+识别流水线,先框出文字区域,再逐框读出文字,轻量,可以在端侧跑。
另一条是用多模态大模型直接看图说字,像 GPT-4o、Qwen3-VL 那样,精度高但很重,必须调云端 API。
PP-OCRv6 走的是第一条路。
但这次我想亲手测测的是,它到底怎么用这么小的模型,去和一堆大模型抢 OCR 这个活。
并且很多人说我的笔记本没有那么高的配置,我又想本地自己用,是否可行呢?这篇文章就可以帮你解决和回答这个问题。
不过在说结果之前,先说说这次跑分是怎么做的。
四个选手,18 张文档图片,逐张手动对比不是人干的事。所以我先搭了个本地 OCR 工作台,FastAPI + ONNX Runtime 做后端,Apple Silicon 自动走 CoreML 加速。
Tiny、Small、Medium 三档模型都能在设置页里一键切换,然后用脚本把所有图片一次性打过去。
📸 PP-OCRv6 Studio 上传识别页 拖拽上传区,支持批量处理和剪贴板粘贴。

拖拽上传区,支持批量处理和剪贴板粘贴(⌘V 截图直接粘)。
📸 PP-OCRv6 Studio 历史记录 历史记录,39 条,每张带缩略图、框数和耗时
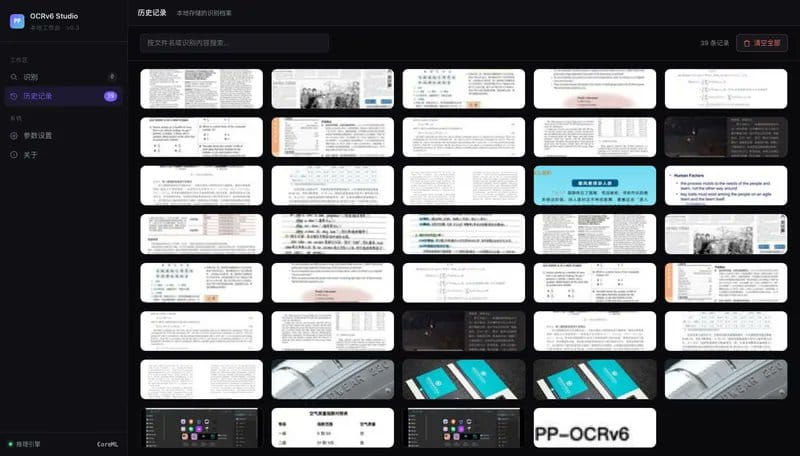
📸 PP-OCRv6 Studio 参数设置 三档模型一键切换,CoreML 开关,检测参数可调
识别完可以看框选可视化,导出 CSV/Excel,历史记录全留着。OmniDocBench 的 18 张图就是用这台工作台逐一跑完的,Apple Vision 那边用 ocrmac 调系统 API 跑同一套图做对照。
开源地址:github.com/andyhuo520/ppocrv6-studio 三步启动:git clone → pip install → python webapp/server.py,ONNX 模型从 Releases 页面一键下载,macOS Apple Silicon 开箱即用。实测从 clone 到跑通第一张图,不到 10 分钟。
这次跑了四个选手,全部本地: PP-OCRv6 Tiny,1.5MB, onnxruntime-web 跑在 Chrome 浏览器里,WebGPU 加速,图片全程不出本地。 PP-OCRv6 Small,7.7MB,本地 ONNX Runtime + CoreML, Apple Silicon 加速。 PP-OCRv6 Medium,34.5MB,本地 ONNX Runtime + CoreML,三档里精度最高。 Apple Vision, macOS 原生 OCR, accurate 档,完全离线,本地基线。
二、三档拆解:架构上动了什么手脚?
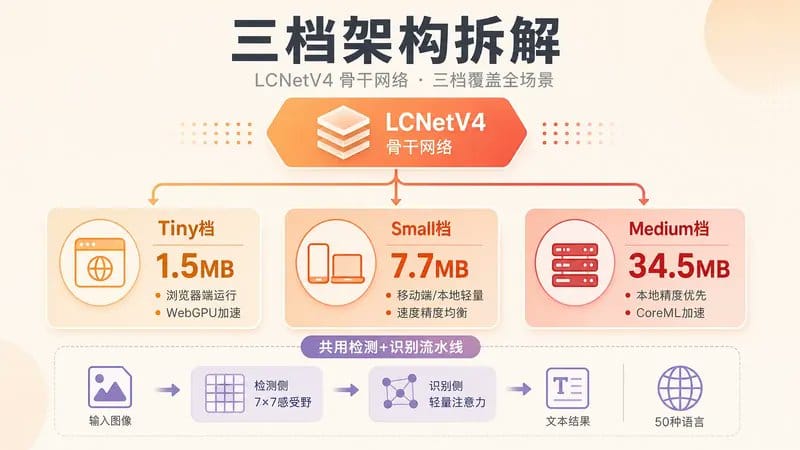
先说三档模型。
PP-OCRv6 的三档共用同一套 LCNetV4 骨干,检测和识别都复用这套结构,区别只在宽度和深度。
Tiny 跑在浏览器里,Small 适合移动端或本地轻量应用,Medium 是精度优先的本地部署档。
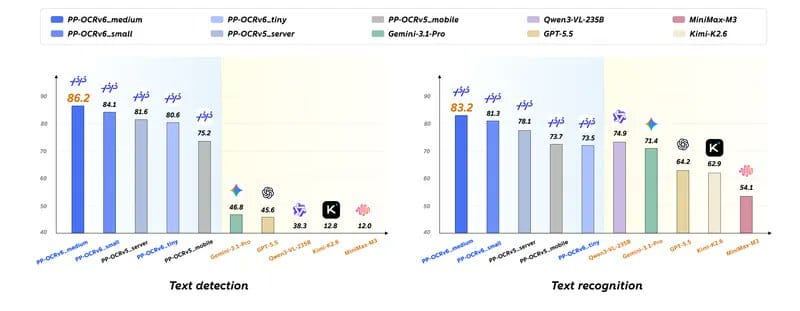
官方在 OCR 专项任务上的数据是这样的,检测/识别分(分越高越好):Medium 86.2/83.2,Small 84.1/81.3,Tiny 80.6/73.5。
对比一下 Qwen3-VL-235B 的 38.3(检测 Hmean)/74.9(识别准确率),这就是发布会说的那个“34.5M 赢 235B”的来源。
不过要理解为什么专用小模型能赢,有一个关键点:PP-OCRv6 的架构专门针对 OCR 这件事做了优化。
检测侧感受野从 3×3 扩到 7×7,对小字和密集文字更友好。识别侧加了轻量注意力模块处理字符上下文,字典覆盖中英日和 46 种拉丁语系共 50 种语言。
模型不大,但任务非常对口。
PP-OCRv6 文本检测与文本识别分数对比图 检测和识别两个 OCR 专项任务上,PP-OCRv6 三档都拉开了和 VLM 的差距,综合性能全球第一。
OCR 模型盘点横向对比图 Tiny / Small / Medium 三档覆盖浏览器、移动端、本地应用和服务器部署。
三、多图跑完,数字不说谎。
用 OmniDocBench 跑一遍之后,整体结果如下(text_block 编辑距离 quick_match 均值,多张,越低越好):
| 模型 | 类型 | 编辑距离(↓) | 备注 |
|---|---|---:|---|
| PP-OCRv6 Medium | 本地 34.5MB | 0.425 | 无需联网 |
| PP-OCRv6 Small | 本地 7.7MB | 0.443 | 无需联网 |
| PP-OCRv6 Tiny | 浏览器 1.5MB | 0.446 | 无需联网 |
| Apple Vision | macOS 原生 | 0.448 | macOS 原生 |三档 PP-OCRv6 的综合均值差距很小,5% 以内。但均值会骗人,拆到具体场景差距就出来了。
最典型的是手写笔记,Medium=0.228, Small=0.245, Tiny=0.283, Apple Vision=0.570. Medium 比系统原生 OCR 好了 2.5 倍。
篇幅有限,大家就直接看对比结果,我之前已经将上次的测试项目也开源可以翻看。
逐张对比如下:
| 文档类型 | V6 Medium | V6 Small | V6 Tiny | Apple Vision |
|---|---:|---:|---:|---:|
| PPT 幻灯片 | 0.004 | 0.008 | 0.004 | 0.000 |
| 中文单栏教材① | 0.295 | 0.295 | 0.295 | 0.304 |
| 中文单栏教材② | 0.326 | 0.320 | 0.322 | 0.137 |
| 手写笔记① ⭐ | 0.228 | 0.245 | 0.283 | 0.570 |
| 手写笔记② | 0.336 | 0.326 | 0.330 | 0.402 |
| 报纸① | 0.839 | 0.882 | 0.817 | 0.844 |
| 报纸② | 0.870 | 0.866 | 0.859 | 0.875 |
| 英文教材① | 0.267 | 0.270 | 0.274 | 0.287 |
| 英文教材②(彩色) | 0.592 | 0.591 | 0.644 | 0.611 |
|说明:⭐ = 三档差异最显著的场景
四、手写场景:Medium 把 Apple Vision 按在地上摩擦

来看几张图,感受一下差距在哪。
先说手写笔记,这张是三档分化最清楚的地方。
📸 手写笔记测试样本,初中地理课笔记 手写笔记,初中地理课,含手绘表格

这是一张初中地理课的手写笔记,天气与气候,包含手绘表格,字迹不算特别工整。来对比一下两个本地方案的识别结果。
📸 PP-OCRv6 识别结果(edit dist 0.283 / Medium 0.228)

📸 Apple Vision 识别结果(edit dist 0.570) 截图请在此处补充

Apple Vision 那份结果——这还是 Apple 的亲儿子框架、accurate 档。
手写中文确实难,但 PP-OCRv6 Tiny 的编辑距离是 0.283,Medium 是 0.228,Apple Vision 是 0.570,差了整整一倍多。
而且三档之间的梯度很清晰。手写场景是最能体现参数规模价值的场景,这条路值得继续走。
五、名片、轮胎、点阵屏——四张「刁难图」实战

除了 OmniDocBench 的标准文档,我还额外测了四张真实世界的难图,覆盖透视变形、点阵字体、浮雕低对比度文字和七段数码管四个场景。
📸 斜拍名片 OCR 测试样本 名片透视,斜拍、小字、白字和彩色块混在一起

📸 点阵字体 OCR 测试样本 点阵字体,字形断裂,但背景干净 截图请在此处补充

📸 轮胎侧壁低对比压印 OCR 测试样本 轮胎压印,低对比、浮雕、斜角,肉眼能看到 TREADWEAR 220

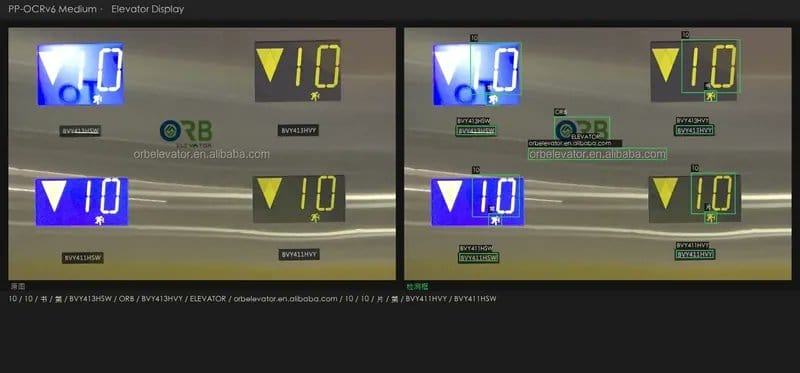
📸 电梯数码屏 OCR 测试样本 电梯屏,发光数字、反光金属面、多个小标签

名片透视——斜拍加彩色底,透视角度让字体变形是最大的难点。Medium 最完整,完整读出品牌、姓名、职位加电话和网址;Small 漏掉了职位这行;Tiny 只读出名字和品牌。Apple Vision 在名字识别上有错字。
📸 名片 OCR 结果对比面板 名片,Medium 最完整,Small 次之,Tiny 漏行,Apple Vision 有错字

点阵字体——字形断裂对字符集要求高,反而是 Small 最稳,两行都完整识别。Medium 同样稳,Tiny 识别 DotMatrix 字体时偶有字符缺失。
📸 点阵字体 OCR 结果对比面板 点阵字体,Small 最稳,Medium 同级,Tiny 偶有字符缺失

轮胎压印——低对比浮雕字是边界场景的代表,肉眼都不容易看清的那种。Medium 读出 TREADWEAR 220 和 PLACARD IN VEHICLE;Apple Vision 只读出了「220」,其余全丢;Tiny 读出了 TREADWEAR 但后续行识别不稳。
📸 轮胎侧壁 OCR 结果对比面板 轮胎压印,Medium 读出 TREADWEAR 220,Apple Vision 只读出「220」,Tiny 部分识别

电梯数码屏——七段数码字体加反光金属底,对所有模型都有挑战。三档 PP-OCRv6 都识别出了产品编号、品牌名和网址,Apple Vision 在反光区域有漏检。
📸 电梯数码屏 OCR 结果对比面板 电梯屏,三档 PP-OCRv6 产品编号和网址均识别,Apple Vision 反光区域有漏检
速度参考:Tiny 大约 3–15 秒一张,Small 4–25 秒,Medium 10–52 秒,Apple Silicon CoreML 加速。Apple Vision 0.16–0.54 秒。
六、大模型的「好心办坏事」:它会偷偷帮你改错别字!

这里有件事我想多说几句。
大模型做 OCR,有个很有趣的缺陷——幻觉。不是那种“胡说八道”的幻觉,而是更隐蔽的:它会把图片里写错的字“纠正”过来。
手写笔记里的错别字,VLM 看到后,不是忠实地抄下来,而是读成正确的写法。从“理解语义”的角度看是聪明的,但从“逐字还原”的角度看,这是一个 bug,不是 feature。
公开数据里有一个很有意思的指标:PP-OCRv6 精确匹配率 93.2%,Qwen3-VL-235B 是 80.6%。差了将近 13 个百分点。
这个指标衡量的是“识别出的文字是否和图片完全一致”,不允许任何“聪明的修正”。
七、结论:别问哪个最强,先问你要抄写员还是翻译家

三档跑完,我对 PP-OCRv6 的判断反而比一开始更清楚了。
Tiny 适合浏览器或嵌入式,1.5MB,图片全程不出本地。
Small 是甜点档,7.7MB,速度和精度的均衡点,手写提升可以感知。Medium 是本地精度优先的选择,手写、彩色教材这类边界场景提升明显,适合对精度有要求但不想调 API 的本地部署。
三档共通的是,数据可以不出本地,不需要 API key,随便一台笔记本就能跑起来。
差别在部署形态:Tiny 可以做成纯前端在线版,打开网页就跑。
Small 和 Medium 放在 FastAPI + ONNX Runtime 的本地 Studio 里跑,前端负责上传、历史记录、框选可视化和表格导出,后端负责加载模型推理。
对很多场景来说这是刚需,敏感文档的公司内网,离线环境,不想为每次 OCR 付 API 费用的个人开发者。
但更重要的是,不同职业的人,对 OCR 的需求根本不是同一件事。
律师审合同——合同扫描件的每一个字都不能错。把“定金”读成“订金”,把“甲方”读成“乙方”,这份合同就废了。律师要的是逐字还原,一个字都不能脑补。这就是抄写员的活,PP-OCRv6 三档随便哪个都够用,而且数据不出本地,合同不用上传到别人的服务器。
老师改手写作业——几十本作业本拍成照片,要的是把学生写的字尽可能准确地读出来。手写识别是 PP-OCRv6 的强项,Medium 比 Apple Vision 好了 2.5 倍。老师不需要理解版式,不需要联网,打开笔记本就能批量处理。
财务核发票——发票上的金额、税号、日期,每一个数字都必须和图片完全一致。大模型的“补全语义”能力在这里反而是风险——它可能把模糊的数字“纠正”成它认为合理的数字。专用轻量模型,读到什么就是什么,没有脑补,更可靠。
研究者读论文——双栏排版的英文学术论文,要的不是逐字抄写,而是理解文档结构:哪段是摘要,哪个是图注,公式和正文怎么排。这是翻译家的活,现阶段调用多模态大模型更合适。
所以回到那个问题:OCR 的未来是不是越来越大的 VLM?
不是一条路吃掉另一条,是 OCR 本身就是两件事。逐字抄写和文档理解,需要的是两种完全不同的能力。
抄写要求忠实——图片里写什么就读什么,错别字不能“纠正”,漏字不能“补全”,精确匹配率才是硬指标。理解要求聪明——双栏要知道先左后右,表格要还原行列结构,阅读顺序比单字准确更重要。
别瞎花钱。
看清楚自己的场景,再选工具。
你要的是抄写员还是翻译家,这比哪个模型分数最高重要得多。
本文由 YouMind 自动从 Markdown 转换排版。