
本文经原作者授权转载,版权归原作者所有。原作者:huangserva(@servasyy_ai)。
你可能一直在浪费 Fable 5
想象一下,你买了一台超级跑车,但每次只开 5 分钟就停下来。这就是大多数人使用 Claude Fable 5 的方式。
十分之九的用户这样用它:打开对话框,问个问题,得到答案,关闭标签页。就像用法拉利去便利店买瓶水——能用,但完全没发挥它的真正价值。
Fable 5 的真正设计目标是什么? 它被设计成可以连续运行数天,每次运行都比上次更聪明。就像一个真正的助手,会从每次工作中学习,积累经验,不断进步。
但你只用了它几分钟。
这篇文章会告诉你如何构建一个真正会“成长”的 AI 系统——不是让 AI 模型本身变聪明(那是科幻),而是让它周围的整个系统越来越强大。
开始之前:理解三个层次
在深入 14 个具体步骤之前,我们需要先建立一个整体框架。把这个系统想象成一座三层楼的建筑:
第一层(地基): Fable 5 的核心能力——它能做什么,为什么比其他模型强
第二层(框架): 三个关键原语——让系统能够循环运行、动态调整、持续工作的基础机制
第三层(智能): 自我改进层——让系统真正“学习”和“进化”的秘密
现在,让我们从地基开始建造。
第一部分:认识 Fable 5 的真正实力
01 | Fable 5 不是“更大的 Sonnet”
2026 年 6 月 9 日,Anthropic 发布了 Claude Fable 5,这是首个公开可用的 Mythos 级模型——一个全新的层级,比 Opus 还要高。
这意味着什么? 用一个类比来说:
- Haiku 就像一个快速的实习生:便宜、快速、能处理简单任务
- Sonnet 像一个熟练的员工:能力全面,性价比高
- Opus 像一个资深专家:能处理复杂问题,但成本较高
- Fable 5 像一个项目经理:不仅能解决问题,还能规划数天的工作,管理团队,从经验中学习
Fable 5 的四大超能力
① 可以连续工作数天
以前的模型就像临时工,干完一件事就走了。Fable 5 更像正式员工,可以接手一个大项目,规划多个阶段,持续工作数天。它会自己检查进度,调整计划,甚至把部分工作分配给“助手”(子智能体)。
② 会自己检查工作质量
想象你写完一篇文章,Fable 5 不仅能写,还会自己设计测试来验证内容是否正确。它甚至能用“眼睛”(视觉能力)看截图,确认界面是否符合要求。
③ 能处理最复杂的代码项目
大型代码迁移、复杂系统实现、需要多天的编码任务——这些以前需要人类持续监督的工作,Fable 5 可以相对独立地完成。
④ 能完成多阶段知识工作
从深度研究、数据分析,到撰写报告、准备交付物——整个流程可以在最少监督下完成。
但要付出代价
Fable 5 的定价是:
- 输入 token:每百万 10 美元
- 输出 token:每百万 50 美元
这大约是 Opus 4.8 的 5 倍。所以关键问题是:如何让这个投入物有所值?
答案就是:不要把它当成“更强的聊天工具”,而要把它当成“自我改进系统的核心”。
02 | Self-improving ≠ Self-learning(这很重要)
在继续之前,我们必须澄清一个常见的误解。
很多人听到“自我改进的 AI”,脑海中浮现的画面是:AI 自己学习,更新自己的“大脑”(模型权重),变得越来越聪明。
这不是 Fable 5 在做的事。 实际上,没有任何公开可用的 AI 模型能这样做。
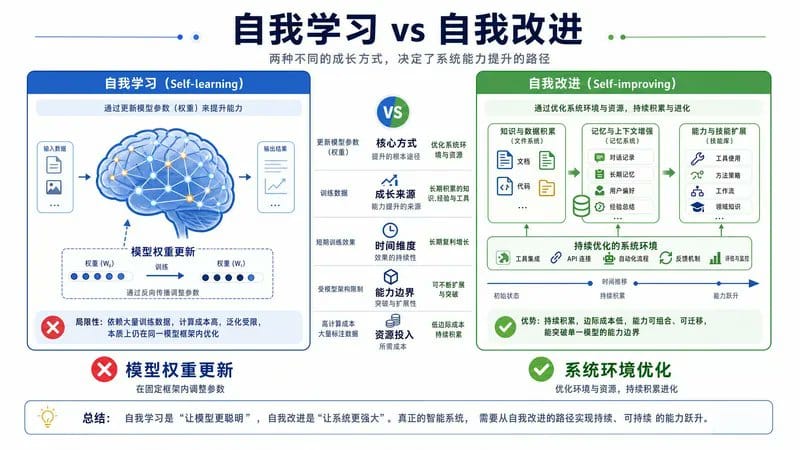
真正的“自我改进”是什么?
用一个更贴切的类比:
Self-learning(自我学习,不是 Fable 5): 就像一个人通过学习改变自己的大脑结构,变得更聪明。
Self-improving(自我改进,Fable 5 的方式): 就像一个人的能力没变,但他的工作环境越来越好:
- 有了更完善的笔记本(Memory 系统)
- 积累了更多的工作模板(Skills 库)
- 建立了更高效的工作流程(Orchestration 系统)
- 有了更好的质量检查机制(Verification Loop)
关键洞察: Fable 5 本身(模型)始终保持不变。但它周围的整个系统——文件、记忆、技能、工作流——在不断积累和优化。
Anthropic 的工程团队明确指出:
“与其直接提示和引导 Fable 5,不如设计循环,让模型响应环境反馈进行自我纠正,并管理自己的上下文。”
这就是我们要构建的:一个让 Fable 5 越用越强的系统。
03 | 四层架构:复合增长的秘密
现在我们来看这个系统的整体架构。想象一座四层楼的建筑,数据和经验从底层向上流动,每一层都在前一层的基础上增加价值。
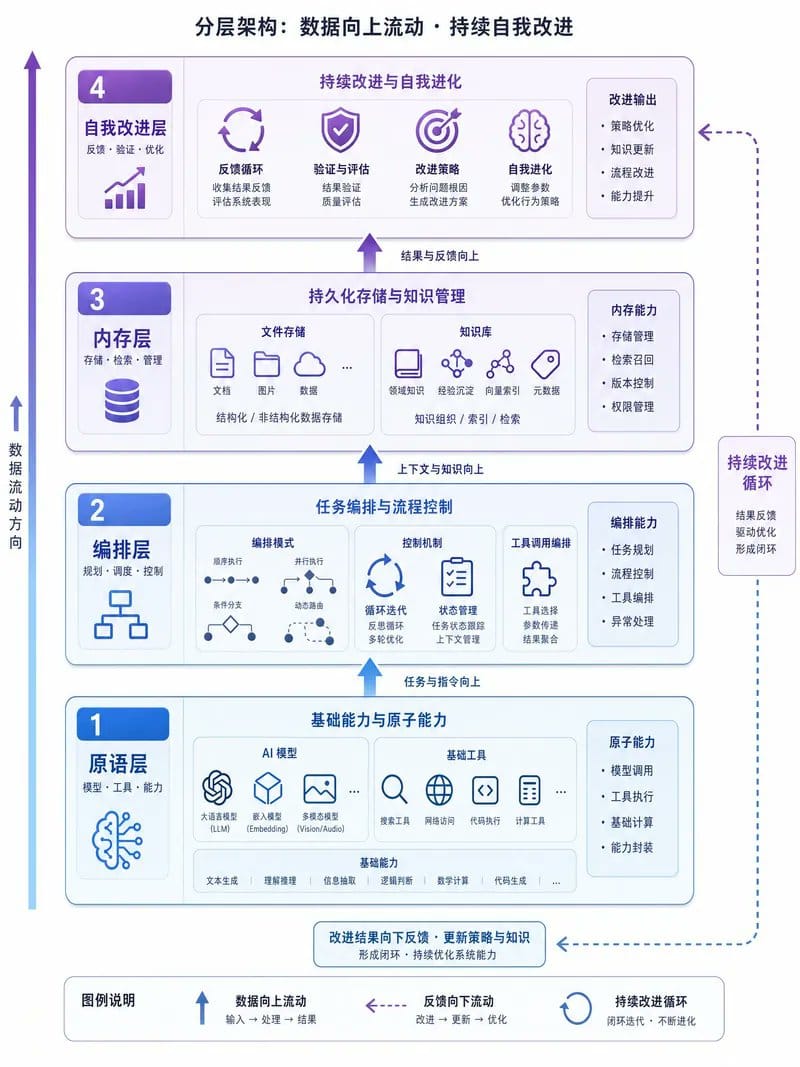
第 1 层:原语层(基础能力)
这是大多数人停留的地方。包括:
- Fable 5 模型本身
- 基础的工具和命令
- 简单的对话交互
类比: 就像你有一个很厉害的员工,但没有给他任何工作流程、文档模板或质量标准。每次都从零开始。
第 2 层:Orchestration 层(工作流控制)
这一层让系统能够:
- 设定目标并循环优化直到达成(/goal 和 Outcomes)
- 动态创建复杂的 Workflows
- 在云端持续运行,即使你的电脑关机(Routines)
类比: 给员工配备了项目管理工具、工作流程图、自动化脚本。工作开始变得有条理。
第 3 层:Memory 层(知识积累)
这一层让系统能够:
- 保存 State 文件,记录已验证的事实
- 积累 Skills 库,存储工作方法
- 建立知识库,不用每次重新学习
类比: 员工有了笔记本、工作手册、经验总结。不再重复犯同样的错误。
第 4 层:Self-improvement 层(智能进化)
这是魔法发生的地方:
- 系统自己检查输出质量
- 从失败中提炼经验教训
- 把学到的东西写回 Skills 库和 Memory
- 形成闭环:每次运行都让下次更好
类比: 员工不仅工作,还会反思总结,更新工作手册,优化流程。能力在复利式增长。
为什么这个架构能复合增长?
关键在于这个循环:
- 第 1 层执行任务,产生输出
- 输出流向第 4 层,被评分和分析
- 经验教训被提炼并写入第 3 层(Memory 和 Skills)
- 明天的任务从第 3 层读取昨天积累的知识
- 循环往复,系统越来越强
核心真理: 模型本身是无状态的(每次对话都是新的),但系统是有状态的(Memory 和 Skills 在持续积累)。
04 | 不要在所有任务上都用 Fable 5
这里有个重要的成本控制策略。记住,Fable 5 的成本是 Opus 的 5 倍。如果你在所有任务上都用它,账单会让你破产。
聪明的做法是:按任务复杂度路由模型(Model Routing)。
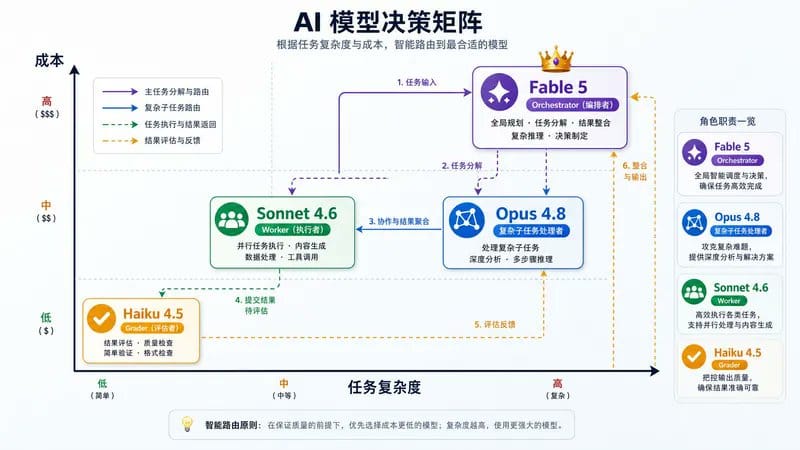
四个模型,各司其职
想象一个公司的组织架构:
Fable 5 = 项目经理($$$)
- 负责:整体规划、任务分解、跨天协调
- 使用场景:需要持续数天的复杂项目
- 例子:大型代码迁移、多阶段研究项目
Opus 4.8 = 技术专家($$)
- 负责:复杂但有界的子任务
- 使用场景:架构决策、复杂调试、深度代码审查
- 例子:设计系统架构、解决棘手 bug
Sonnet 4.6 = Worker($)
- 负责:大量的日常工作
- 使用场景:代码重构、测试编写、文档更新
- 例子:修复简单 bug、更新 README
Haiku 4.5 = Grader($)
- 负责:快速验证和评分
- 使用场景:检查输出质量、简单分类
- 例子:验证代码格式、检查测试是否通过
黄金组合
生产环境中最经济的模式:
Fable 5 做 Orchestrator + Sonnet 4.6 做 Worker + Haiku 4.5 做 Grader + Opus 4.8 做 Fallback
这就是 Anthropic 内部团队使用的模式。
过渡到下一部分: 现在你理解了 Fable 5 的能力和定位。但要让它真正发挥作用,我们需要三个关键的“Primitives”——就像编程语言的基础构建块。让我们进入第二部分。
第二部分:三个让系统“活”起来的 Primitives
如果第一部分是认识工具,第二部分就是学习如何使用工具。这里有三个核心机制,它们让 Fable 5 从“一次性对话”变成“持续运行的系统”。
05 | Loop 机制:设定目标,不断优化直到达成
想象你给员工布置任务时说:“把这个做好”,然后就走了。员工做完后,你怎么知道是否真的“做好”了?
这就是 /goal 和 Outcomes 要解决的问题:让系统知道什么叫“完成”,并 Loop 优化直到真正达标。
核心思想
这两个工具本质上是同一个想法的两种实现:
- 你设定一个明确的 Goal(例如:“所有测试必须通过”)
- 一个独立的 Grader 检查工作是否达标
- 如果没达标,系统自动开始下一轮优化
- 如果达标了,Loop 退出,任务完成
关键点: Grader 是独立的,不是做任务的那个 AI。这很重要(我们马上会讲为什么)。
什么时候用哪个?
用 /goal(在 Claude Code 中):
- 工作在你本地电脑上
- 需要快速的反馈循环
- 适合:编码、调试、优化单个文件
用 Outcomes(在 CMA 中):
- 工作需要在云端运行数小时或数天
- 需要 GPU、Sandbox 等特殊环境
- 适合:ML 训练、大型迁移、长期研究
过渡: 但为什么 Grader 必须是独立的?这引出了一个关键发现……
06 | 为什么 AI 不能给自己的作业打分?
Anthropic 的工程师做了大量实验,发现了一个重要现象:
“Verifier sub-agents 往往优于 Fable 5 的 self-critique”
这不是 Fable 5 不够聪明,而是一个结构性问题。
用一个生活例子理解
想象你写了一篇文章,然后自己检查:
自我检查的问题:
- 你知道自己想表达什么,所以容易“脑补”缺失的逻辑
- 你已经投入了努力,潜意识里不愿意承认有大问题
- 你看到的是“我想写什么”,而不是“实际写了什么”
让别人检查(Independent Verifier)的优势:
- 他们只看到文字本身,没有你脑海中的背景
- 他们没有“沉没成本”,更容易指出问题
- 他们能发现你视而不见的盲点
AI 也一样。
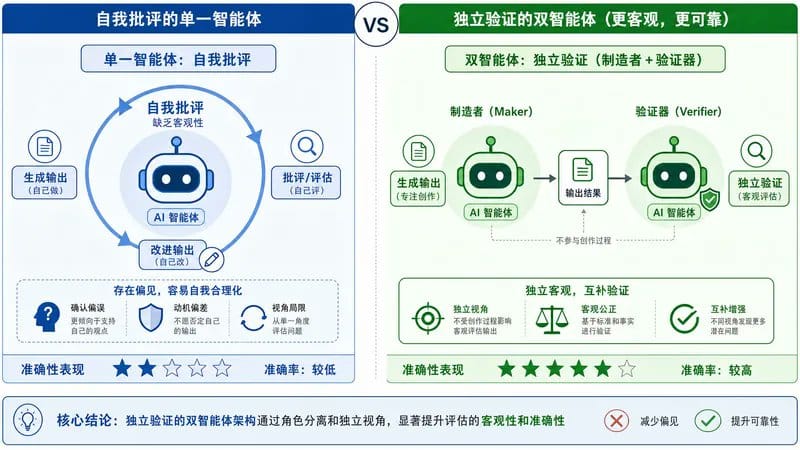
实验数据证明了什么?
Anthropic 的 Parameter Golf 实验显示:
有 Independent Verifier 的 Fable 5:
- 敢于尝试大胆的架构改变
- 即使中间结果不好,也会继续探索
- 最终获得了约 6 倍于 Opus 4.7 的改进
没有 Independent Verifier 的 Opus 4.7:
- 倾向于保守的小改动
- 一旦看到负面结果就停止
- 停留在“足够好”而不是“真正好”
设计原则: 在你的系统中,Maker 和 Verifier 必须分离。这不是可选项,是必需品。
07 | 动态工作流:让 AI 自己设计工作流程
现在我们有了 Loop 机制(目标驱动)和 Verification 机制(独立检查)。但对于复杂任务,我们还需要一个能力:动态编排多个步骤。
核心思想
传统方式:你预先设计一个固定的工作流程,AI 按步骤执行。
动态工作流:AI 根据任务即时编写自己的工作流程——包括并行处理、条件分支、循环优化等。
类比: 就像给员工一个项目,他不仅执行,还自己设计项目计划、分配子任务、决定哪些可以并行做。
三种最有用的模式
对于 Self-improving 系统,这三种模式最重要:
① Fan-out and Synthesize(扇出和综合)
把一个大任务分成多个独立的小任务,并行处理,然后综合结果。
例子: 要评估一个 Skills 库中的 20 条规则是否还有效。与其串行检查,不如:
- 启动 20 个并行的 Verification Agents
- 每个检查一条规则
- 最后综合所有结果
② Adversarial Verification(对抗性验证)
对每个“Maker” Agent,自动生成一个“Verifier” Agent.
例子: 一个 Agent 写代码,另一个 Agent 专门找 bug。Verifier 完全不知道 Maker 的思路,只看代码本身。
③ Loop Until Done(循环直到完成)
持续运行直到满足停止条件。
例子: 修复 bug 的循环:
- 运行测试
- 如果有失败,分析原因并修复
- 再次运行测试
- 重复直到所有测试通过
为什么这很强大?
因为 Workflow 是为任务定制的,而不是通用的。就像定制西装比成衣更合身。
过渡: 但这些 Loops 和 Workflows 都有一个前提:系统必须能持续运行。如果你的笔记本电脑关机了怎么办?
08 | Worktrees:让多个 AI 并行工作不打架
当你的系统开始生成多个 Agents 并行工作时,会遇到一个经典问题:文件冲突。
问题场景
想象两个程序员同时编辑同一个文件:
- 程序员 A 在修改第 10 行
- 程序员 B 也在修改第 10 行
- 他们都保存了
- 结果?一个人的修改覆盖了另一个人的
多个 AI Agents 并行工作时,完全一样的问题。
解决方案:Git Worktrees
Git Worktrees 就像给每个 Agent 一个独立的工作空间:
- 共享同一个代码仓库的历史
- 但每个 Agent 在自己的分支上工作
- 互不干扰
- 完成后再合并
类比: 就像给每个员工一个独立的办公室,而不是挤在一个开放空间里抢同一张桌子。
三个关键应用场景
① Maker 和 Verifier 隔离
Maker 在 Worktree A 中写代码,Verifier 在 Worktree B 中检查。Verifier 的实验不会破坏 Maker 的成果。
② 并行实验
要测试 5 种不同的架构方案?启动 5 个 Worktrees,每个测试一种。最后选最好的合并。
③ 长期项目的 Checkpoints
每个主要阶段用一个 Worktree。如果某个阶段失败了,不会影响其他阶段。
09 | Routines:让系统在你睡觉时工作
现在我们到了一个关键能力:让系统在云端持续运行,即使你的电脑关机了。
这就是 Routines 的作用。
核心概念
Routines 是保存的配置,包括:
- 要运行的提示和任务
- 使用的代码仓库
- 需要的权限和工具
- 触发条件(什么时候运行)
配置好后,它在 Anthropic 的云基础设施上运行。你的笔记本电脑可以关闭,任务继续进行。
为什么这对 Fable 5 至关重要?
记住,Fable 5 被设计成可以工作数天。但如果任务运行在你的笔记本电脑上:
- 你关机了,任务就中断了
- 网络断了,任务就失败了
- 电脑休眠了,任务就暂停了
Anthropic 的 Parameter Golf 实验在 8×H100 GPU 上运行了 8 小时。这种任务不可能在本地运行。
三种触发方式
① Scheduled Triggers:每天自动运行
例子: 每天早上 7 点:
- 重新运行昨天的测试套件
- 把新发现的问题记录到 Skills 库
- 把摘要发到 Slack
- 你醒来时,系统已经更聪明了
② API Triggers:出问题时自动响应
例子:
- CI 测试失败 → 自动触发调查 Routine
- 服务器报警 → 自动触发诊断 Routine
- 系统不是按时间表运行,而是按需响应
③ GitHub Triggers:从真实工作中学习
例子:
- 有人提交 PR → 自动用最新 Skills 评估
- PR 合并后 → 把新模式写入 Skills 库
- 代码库和 Skills 库保持同步
示例配置
每天早上 7 点,用 Fable 5 在云端运行:
目标:重新运行昨天的评估套件
- 新通过的测试 → 提炼模式到技能库
- 新失败的测试 → 调查并记录到状态文件
- 把摘要发到 Slack
不停止,直到摘要发送完成且状态文件更新过渡到第三部分: 现在我们有了基础能力(第一部分)和运行机制(第二部分)。但系统如何真正“学习”和“进化”?这就是第三部分的内容——Self-improvement 层。
第三部分:让系统真正“成长”的 Self-improvement 层
这是整个架构中最神奇的部分。前面的所有内容都是为了这一层服务:让系统从每次运行中学习,持续变强。
10 | Memory 的五个进化阶段
大多数人对“AI Memory”的理解停留在“它能记住我们的对话”。但真正有用的 Memory 系统要复杂得多。
Anthropic 的研究发现,有效的 Memory 需要经历五个阶段的进化。每个阶段都是一个质的飞跃。
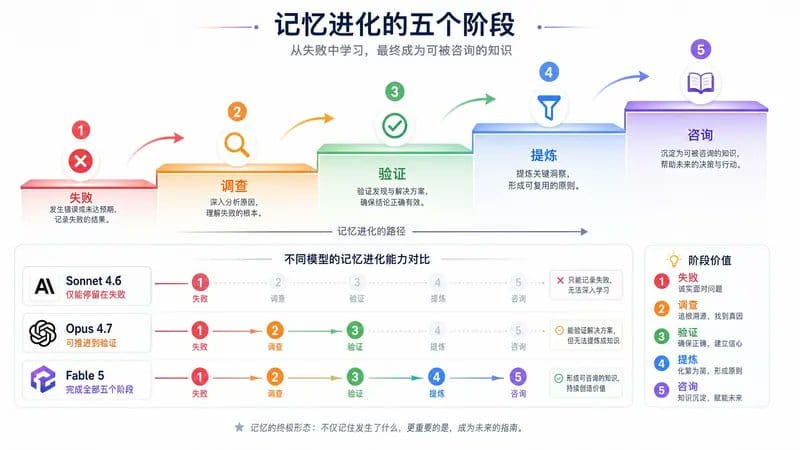
五个阶段详解
用一个具体场景来理解:假设 AI 在处理数据库查询时遇到了错误。
Stage 1: Failure - 诚实记录
最基础的能力:知道出错了,并记录下来。
例子: “查询失败了,返回了空结果”
大多数系统停在这里。 下次遇到类似问题,还是会犯同样的错误。
Stage 2: Investigation - 追根溯源
不仅记录失败,还要弄清楚为什么失败。
例子: “查询失败是因为字段名错了,我用了 prc_usd 但实际字段叫 prc"
这需要主动探索。 很多模型会跳过这一步,直接猜测。
Stage 3: Verification - 确保正确
把猜测变成已验证的事实。
例子: “我运行了 SELECT MIN(prc), MAX(prc) FROM trades,确认 prc 字段存储的是美元金额,范围在 0.01 到 999.99 之间“
关键区别: 不再是“可能是”,而是“确认是”。
Stage 4: Distillation - 形成通用规则
把具体经验提炼成可以应用到其他场景的原则。
例子: “在查询时间分桶指标时,始终明确指定时区,因为默认 UTC 会导致时间不匹配”
这是质的飞跃。 一个具体问题变成了一条通用规则。
Stage 5: Consultation - 成为未来的指南
在下次任务中,主动查阅这些规则,而不是重新推导。
例子: 下次处理时间相关查询时,系统会先查看规则:“哦,我需要明确指定时区”,然后直接写出正确的查询。
这是 Memory 的终极形态: 不仅记住过去,还能指导未来。
不同模型的表现
Anthropic 的实验数据:
Sonnet 4.6: 停在阶段 1
- 能记录失败,但很少深入调查
- 下次遇到类似问题,重复犯错
Opus 4.7: 到达阶段 3
- 能验证解决方案
- 但验证覆盖率只有 17%(30 个问题中验证了 5 个)
- 很少提炼成通用规则
Fable 5: 完成全部五个阶段
- 验证覆盖率达到 73%(30 个问题中验证了 22 个)
- 能提炼通用规则并在后续任务中应用
关键洞察: 这不是模型“更聪明”,而是 Fable 5 有足够的耐力和上下文窗口来完成整个进程。
11 | State Files: Memory 实际存在的地方
五阶段进展是概念框架。但 Memory 实际存储在哪里?答案是:State Files(STATE.md)。
为什么需要 State Files?
想象你和一个健忘的助手工作:
- 今天你们解决了一个问题
- 明天他完全忘记了
- 你们又从头开始解决同样的问题
- 永远在原地打转
State File 就是助手的“工作日志”,让他能从昨天继续,而不是从零开始。
一个真实的 State File 结构
# 项目记忆 · 交易平台
## 已验证的事实(阶段 3 - 不要再猜测这些)
- prc 字段存储的是美元,不是美分
验证方式:SELECT MIN(prc), MAX(prc) FROM trades
确认日期:2026-06-09
- user_id 通过 JOIN 匹配 auth_users.uid,不是 auth_users.id
确认日期:2026-06-09
- 测试数据库使用 Stripe 沙箱密钥
生产环境使用真实密钥(从环境变量读取)
## 通用规则(阶段 4 - 先查阅再行动)
- 查询时间分桶指标时,始终明确指定时区
原因:默认 UTC 会导致时间不匹配
- 认证中间件顺序很重要:rate_limit -> jwt -> rbac
颠倒顺序会导致 401 错误
- 对于超过 100 万行的表,不要直接 ALTER
解决方案:分批处理,每批 1 万行
## 待调查的失败(阶段 1 → 2)
- 2026-06-09:tests/e2e/checkout 测试偶尔失败(约 1/50)
假设:Stripe webhook 竞态条件
重现步骤:见 debug/checkout-flake.md
## 经验教训(阶段 4 的提炼)
- PowerShell 在 Windows CI 上有 TLS 1.2 问题
解决方案:改用 bash
- Stripe webhook 测试需要 STRIPE_WEBHOOK_SECRET
如果缺失,跳过测试并显示清晰的消息
## 上次会话(阶段 5 - 恢复点)
2026-06-10 03:30 UTC
- 分类了 7 个失败
- 起草了 3 个修复(claude/fix-*)
- 上报了 4 个问题
下一步:在生产负载下验证 claude/fix-rate-limit-order 中的认证中间件修复两个黄金规则
规则 1:离开前必须写入
每个工作会话结束时,必须更新 STATE.md:
- 尝试了什么
- 什么成功了
- 什么失败了
- 学到了什么新规则
如果不写,下次会话就从零开始。
规则 2:开始前必须读取
每个新会话开始时,必须先读取 STATE.md 和相关技能。
Anthropic 的数据显示: 不这样做的话,即使是 Fable 5 也会退化到 Sonnet 级别的记忆表现。
类比: 就像医生看病人,必须先查看病历,而不是每次都当新病人问诊。
12 | Skills 库:让经验跨项目复用
STATE.md 是项目级的 Memory——只对当前项目有用。但有些经验教训是通用的,应该在所有项目中应用。
这就是 Skills 库的作用。
Skills vs State Files
State Files(STATE.md):
- 项目特定的事实和经验
- 随项目结束而结束
- 例子:“这个项目的 prc 字段是美元”
Skills:
- 通用的工作方法和规则
- 跨项目使用
- 例子:“处理价格字段时,始终验证单位”
Skills 如何进化?
一个新 Skill 可能只有几行基础指令。但经过两周的实际使用,它会变成这样:
---
name: CI 故障分类
description: 分类 CI 失败,为简单的起草修复,上报复杂的
---
# CI 故障分类技能
## 分类规则
- env:缺少密钥或环境变量 → 上报给人类,不要自动修复
- flake:重试后通过 → 重试一次,然后提交 issue
- bug:与最近提交相关的确定性失败 → 起草修复
- dependency:与版本升级相关 → 起草回滚
- infra:超时、内存溢出、运行器问题 → 上报
## 已知失败模式(两周实战中添加)
- webhook-race:Stripe webhook 在测试中途到达导致 e2e checkout 测试失败
修复:在 tests/utils/webhook.ts 中添加 2 秒稳定延迟
- tls-handshake:Windows 运行器上 PowerShell 的 TLS 1.2 失败
修复:改用 bash
- db-migration:超过 100 万行的 trades 表上的 ALTER 在 30 秒时超时
修复:分批处理,每批 1 万行
## 反模式(真实事故后添加)
- 永远不要禁用失败的测试来让 CI 变绿
正确做法:提交 issue
- 永远不要在没有人类批准的情况下修改 .github/workflows/
- 永远不要在没有安全审查的情况下触碰 src/payments/ 或 src/billing/
## 状态管理
每次运行后更新 STATE.md,记录分类、起草的修复、上报的问题
## 评估套件
每周对照 eval/ci-triage-cases.jsonl 运行
任何新失败的案例 → 在验证器确认后添加到已知失败模式复合增长的契约
每个确认的经验教训都写入 Skill,不仅仅是聊天记录。
- STATE.md 随项目消失
- Skills 永久保存在 ~/.claude/skills/
- 两周严格实践后的 Skill,比 Fable 5 从头推导的任何东西都强
类比: STATE.md 是项目笔记,Skills 是工作手册。笔记可以扔,手册要一直带着。
13 | Visual Verification:让 AI 用“眼睛”检查工作
到目前为止,我们讨论的 Verification 都是基于文本的——检查代码、日志、测试结果。但有些东西必须用眼睛看才能判断:用户界面。
问题场景
你让 AI 实现一个登录页面:
- 代码写完了
- 测试通过了
- 但界面看起来完全不对:按钮位置错了,颜色不对,布局乱了
传统的验证器只能检查代码和测试,看不到实际效果。
Fable 5 的解决方案
Fable 5 可以:
- 渲染界面并截图
- 用视觉能力“看”截图
- 对照设计要求检查
- 如果不符合,描述具体差距
- 把反馈返回给制造者
整个过程在循环中自动完成,不需要人类介入。
实际工作流程
步骤 1:Maker Agent 写 UI 代码
- 实现登录表单
- 渲染并截图
步骤 2:Verifier Agent 用视觉检查
- 读取截图
- 对照设计要求:“登录按钮应该是蓝色,位于表单底部”
- 对照 STATE.md 中的先前截图
- 对照 Skills 库中的设计规范
步骤 3:判定
- ✓ 匹配 → 任务完成
- ✗ 不匹配 → 描述差距:“按钮是灰色的,应该是蓝色;按钮在右上角,应该在底部”
步骤 4:Loop
- Maker 根据反馈修改
- 重新渲染和截图
- Verifier 再次检查
- 重复直到通过
真实案例
Anthropic 的 Parameter Golf 实验中:
- Fable 5 查看训练曲线图(Visual Artifact)
- 判断曲线是否符合收敛标准
- 决定是继续训练还是停止
- 整个过程没有人类看图表
关键洞察: Visual Verification 不是“锦上添花”,而是某些任务的必需品。UI、数据可视化、设计保真度——这些用纯文本 Verifier 会错过关键问题。
14 | Safety Boundaries:Fable 5 不会做什么
最后一个步骤经常被忽略,但在生产环境中至关重要:理解 Fable 5 的限制。
Fable 5 内置了安全分类器,会在某些高风险领域拒绝响应:
- 网络安全漏洞研究
- 生物学
- 化学
- 模型蒸馏
为什么这很重要?
想象你构建了一个自动化的代码审查系统,运行得很好。某天,它突然在安全审计任务上静默失败了——因为触发了分类器。
如果你没有设计回退机制,系统就会看起来“坏了”,但你不知道为什么。
四个设计原则
① 为安全工具领域设计回退
如果你的系统涉及:
- 安全扫描工具
- 漏洞研究
- 渗透测试
- 某些类型的代码审查
解决方案: 明确将这些任务路由到 Opus 4.8,或者将分类器阻止呈现给人类审查。
② 科学计算领域同样需要回退
生物学、化学、密码学相关的任务可能触发分类器。
③ 在技能中记录预期行为
技能应该知道哪些任务可能触及分类器,并记录:
- 预期的回退路径
- 如何处理分类器阻止
- 何时需要人类介入
④ 阅读系统卡
Fable 5 的 319 页系统卡详细记录了分类器的范围。在部署到生产环境之前,必须阅读。
设计原则
将安全边界视为已知的回退,而不是意外的失败。
- 配备显式处理的系统:稳健
- 忽略边界的系统:脆弱
当 Anthropic 更新分类器策略时,前者继续工作,后者产生静默回归。
十大常见错误:不要这样用 Fable 5
在结束之前,让我们总结十个最常见的错误——这些错误会让 Fable 5 的潜力只发挥 10%。
① 用 5 分钟就关闭
错误: 像用 Sonnet 一样用 Fable 5——问个问题,得到答案,关闭。
为什么错: 以 Mythos 级定价燃烧,没有复合效应。就像用法拉利去便利店。
正确做法: 用于需要持续数天的复杂项目。
② 让 AI 给自己打分
错误: 让同一个 AI 既生成输出又验证输出。
为什么错: 自我批评存在结构性偏见,准确率显著低于独立验证。
正确做法: 制造者和验证器必须分离。
③ 没有状态文件
错误: 每个会话从零开始,不保存状态。
为什么错: Fable 5 的记忆优势消失 70%+。就像每天都是第一天上班。
正确做法: 每次会话结束时写入 STATE.md,开始时读取。
④ 技能从不更新
错误: 创建了技能,但从不根据真实失败更新。
为什么错: 静态技能很快就过时了,浪费了复合增长的机会。
正确做法: 每次重要失败后,将经验教训写入技能。
⑤ 在简单任务上用 Fable 5
错误: 用 Fable 5 做文档更新、简单重构、lint 修复。
为什么错: 成本是 Opus 的 5 倍,但这些任务不需要 Fable 5 的能力。
正确做法: 按复杂度路由:Fable 5 做编排,Sonnet 做执行,Haiku 做验证。
⑥ 在本地运行长任务
错误: 在笔记本电脑上运行需要数小时的任务。
为什么错: 电脑关机、网络断开、系统休眠都会中断任务。
正确做法: 用例程在云端运行长任务。
⑦ 忽略安全边界
错误: 没有为分类器阻止设计回退。
为什么错: 系统会在某些任务上静默失败,看起来像 bug。
正确做法: 明确处理安全边界,设计回退路径。
⑧ 用文本验证视觉任务
错误: 用纯文本验证器检查 UI、图表、设计。
为什么错: 会错过关键的视觉问题。
正确做法: 对视觉任务使用视觉验证。
⑨ 没有明确的完成标准
错误: 不用 /goal 或 Outcomes,让 AI 自己判断何时“够好”。
为什么错: AI 会在“差不多”就停止,而不是真正完成。
正确做法: 设定明确的、可验证的完成标准。
⑩ 没有审查数据保留策略
错误: 在不了解数据保留条款的情况下处理敏感数据。
为什么错: 可能产生合规问题(30 天/2 年保留期)。
正确做法: 在处理敏感数据前审查策略。
结论:Fable 5 是系统,不是工具
核心真理
Fable 5 不是“更快的聊天工具”。它是复合系统的基底。
第一个公开可用的 Mythos 级模型的发布,不是为了让你更快地得到答案,而是为了让你构建一个能够持续学习、不断进化的系统。
数据证明了一切
Anthropic 自己的实验清楚地显示了差距:
参数高尔夫实验:
- 有独立验证器的 Fable 5:获得了约 6 倍的改进
- 没有验证器的 Opus 4.7:停留在保守的小改进
持续学习基准:
- 有记忆系统的 Fable 5:验证覆盖率 73%
- 有记忆系统的 Opus 4.7:验证覆盖率 17%
关键洞察: 在每次比较中,模型本身是相同的。改变的是它周围的系统。
从明天开始
不要试图一次构建整个系统。选择一层,从明天开始:
如果你还没有验证器: 实现第 6 步——让独立的 AI 检查输出
如果你没有状态文件: 实现第 11 步——创建 STATE.md 并坚持读写
如果你没有视觉验证: 实现第 13 步——让 AI 用“眼睛”检查 UI
然后是下一层,再下一层。
最后的话
自我改进是系统的属性,不是模型的属性。
Fable 5 给了你原材料——长上下文、子智能体、视觉能力、数天级耐力。
但只有当你构建了正确的系统——循环、验证、记忆、技能——这些能力才能复合增长。
停止提示。开始构建系统。
本文基于 Anthropic 工程博客、团队的公开实验,以及 2026 年 6 月的 Fable 5 发布文档。
#AI 智能体 #Fable5 #自我改进系统 #Claude #Anthropic