
本文经原作者授权转载,版权归原作者所有。原作者:花叔(@AlchainHust)。
上周MiniMax发了M3,主打三件套:编程能力大幅提升、长上下文、原生多模态。先看它自己放出来的成绩单。
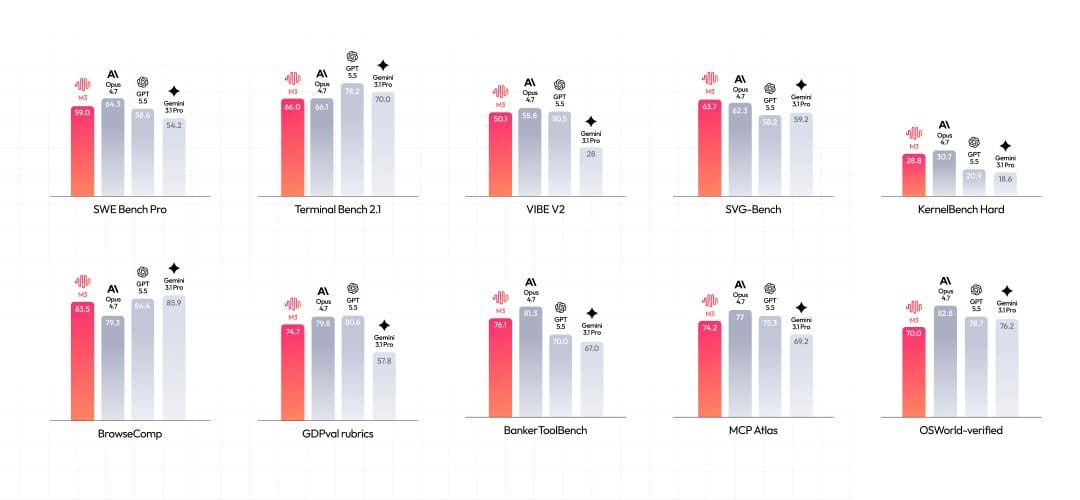
红色那根是M3。我的整体判断:编程和agent工具调用这块,它确实摸到了前沿线,跟Opus 4.7、GPT-5.5基本站到了同一档。少数偏弱的项,后面会说。
不过相比榜单,我自己更感兴趣的倒是它官宣里最技术的那块,一个叫MSA的东西,全称MiniMax Sparse Attention,稀疏注意力。
发布当天官方只有博客和一张架构图,好些细节悬着,现在完整的技术论文放出来了,30页,我从头到尾读完了,收获不小:之前悬着的细节都摊开了,还有几个藏在附录里的实验,比正文还有意思。这篇文章里不少细节,就来自这份论文。

说起来,这两年但凡国产模型聊长上下文,几乎都绕不开「稀疏注意力」这四个字。先把场上的牌摊一下:NSA和DSA都是DeepSeek的,去年2月那篇被讨论很多的Native Sparse Attention是DeepSeek放的论文,去年9月V3.2上线的DSA是它落到生产里的实现;Kimi有MoBA,2025年2月和NSA前后脚放出;现在MiniMax又来一个MSA,给M3配套。
乍一看,大家好像在做同一件事,名字都长得差不多。但我把这四份方案的论文翻出来摆一起看,发现它们看着像,骨子里的取舍其实分道扬镳。今天就来干这件事,把四份方案放一张桌上,讲讲到底差在哪。
一、先问一句:为什么大家都奔向稀疏
要理解稀疏注意力,得先知道它在解决什么问题。
注意力机制(attention)是Transformer的核心。简单理解,模型每生成一个新词,都要回头把前面所有的词扫一遍,算一算我现在该重点看谁。这个扫一遍所有人的操作,就是full attention,全注意力。
问题出在「所有人」这三个字。
假设上下文里有n个词,模型每生成一个新词,都要回头看一遍前面全部n个词。写到第100万个词的时候,光这一步就要看100万次,整篇累计下来,计算量就是n的平方级别,也就是O(n²)。上下文一千个词的时候没人在乎,可你要做100万词的1M上下文呢?平方一下,是一万亿级别的运算量。
不止算力。模型还得把前面所有词的信息存下来备查,存的这堆东西叫KV cache。上下文越长,这个缓存越大,显存直接吃满。
所以1M上下文这件事,技术上早就能做,真正的拦路虎是经济账:太贵,跑不起。
稀疏注意力的思路就一句话:生成下一个词的时候,没必要真的回头看完前面100万个。绝大部分是不相关的废话,模型只要挑出真正相关的那一小撮来精算就行。
挑谁、怎么挑、挑多细,就是这场三国杀的全部分歧所在。
顺便交代下MiniMax自己的来路,因为它这次选稀疏不是拍脑袋。早期的MiniMax-01和M1走的是另一条更激进的路,以线性注意力(Lightning Attention)为主的混合架构,想绕开softmax、把那个O(n²)直接干到接近线性。后来M2又退回了老老实实的full attention,还专门写了篇长文解释为什么。兜了一圈,M3落到稀疏注意力这条中间路上。这条路没线性那么激进,但比full attention省得多,算是它试出来的一个平衡点。
二、MSA是怎么做的
先把主角讲透,再去和别人比。
论文里给MSA的定位是两个分支:一条索引分支(Index Branch),一条主分支(Main Branch)。官方架构图长这样:
全是英文标注,看着有点劝退。我把它的逻辑翻译成了中文:
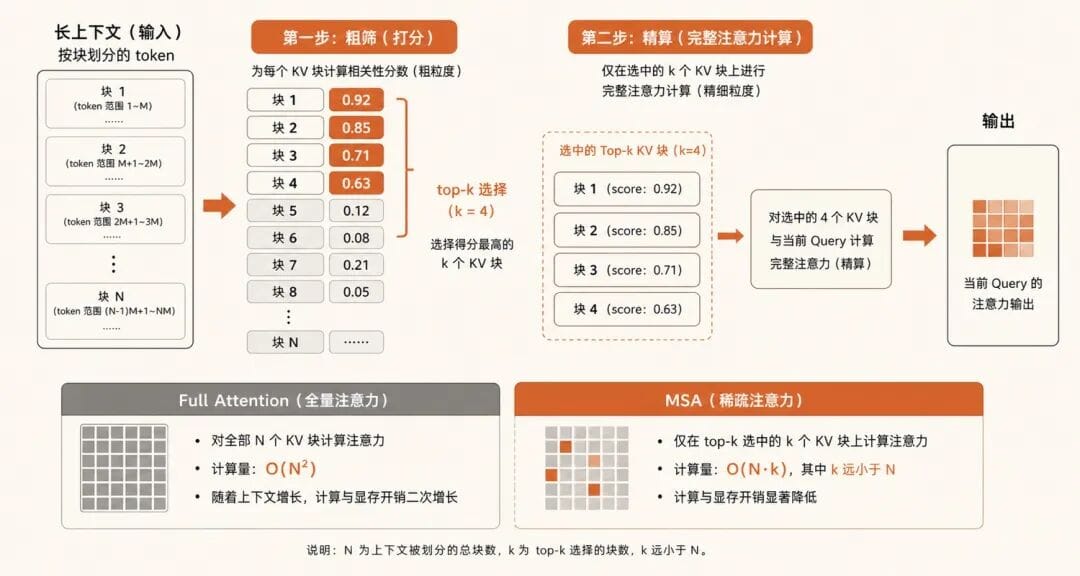
按这张图,MSA的做法可以理解成先粗筛,再精算两步走。
第一步,粗筛。索引分支把前面的上下文切成一块一块的(一块128个token),用一个很轻的打分动作快速估一估每块跟当前要生成的内容相不相关:先给块里每个token打个分,取块内最高分当这块的分(论文里叫block max pooling),然后挑出16块:当前位置所在的那块必选,其余按得分高低挑。
第二步,精算。主分支只在挑出来的这16块上跑完整的注意力计算,剩下没被选中的直接跳过。16块乘以128个token,等于每生成一个词,固定只精算2048个token,不管你上下文是10万还是100万。这就是省钱的来源:全注意力的开销跟着上下文长度涨,MSA把精算预算焊死了。
打个不太严谨的比方。你要在一本一千页的书里找一段话,full attention是从头到尾逐字读完,MSA是先翻目录和小标题、圈出最可能相关的那几页,再逐字精读那几页。前者保证不漏,但慢;后者快得多,赌的是目录足够可信。这个比方有个失真要点破:书的目录是印死的,MSA的目录是每写一个新词就重新翻、重新排一次的,而且没人帮它编,是模型自己学出来的。怎么学出来的,下面马上讲。
读论文之前我有个疑问:这个负责挑块的索引分支,自己不也要扫全文打分吗,凭什么它不贵?论文给了答案,轻到夸张。注意力可以理解成64只眼睛并行各看各的,这是主分支干活的配置;索引分支砍到只用1只眼睛粗扫(论文的配置是每个注意力组1个打分头,外加全模型共享1个key头)。打分时还跳过了softmax里最贵的指数运算,理由很简单:挑top-k只关心名次,做不做softmax,名次都不变。粗筛的成本被压到几乎可以忽略。
还有个问题更要命:挑top-k这个动作是不可导的,没法用正常的训练方法教索引分支「该挑哪块」。论文的解法是给它配了一套完整的训练配方:让索引分支拿主分支的注意力分布当老师,用KL散度对齐(你主分支真正关注谁,我就学着给谁打高分);训练信号只更新索引分支自己的参数,不许串到主干网络去(梯度截断);开头40B个token先跑全注意力热身,等索引分支学得差不多了再开启稀疏。
像学徒先跟着老师傅看,看明白了才放手让他自己挑。放手之后老师也没下岗,KL对齐继续在挑中的块上做。至于学徒压根没挑中的块怎么纠错,论文没专门展开,只给了监控数据:索引分支挑出来的块,覆盖了主分支九成以上的注意力权重,算是用结果说话。
算子层面,论文把博客里提过的「outer gather Q」展开讲了。常规稀疏kernel的做法是以query为中心:每个query各自去把它要的KV块捞出来,同一块数据被不同query反复读。MSA反过来,以KV块为外层:把所有选中了这块的query聚集到一起,一次性算完,每块数据只读一次。像仓库拣货,与其每个订单派一个人满仓库跑、同一个货架被踩好几遍,不如按货架来,一个货架前把所有要这件货的订单一起处理掉。
论文给这事算了笔账。先交代个背景:GPU的脾气是算得飞快、搬数据很慢,瓶颈常在搬运不在计算,所以衡量这类kernel的好坏,看的是搬一次数据进来能算多少下,行话叫计算访存比。按query为中心组织,这个比值大约等于注意力的组内头数,论文实验模型的配比下是16;按KV块为中心,大约是块大小的三分之二,128的块就是85左右。光是 top-k 选择这一步的 kernel 就实现快 3-5 倍,计算访存比的提升落到了实测里。
顺带说一句,去年NSA论文里也有一套面向GQA的数据装载设计,但方向正好相反,它是以query位置为中心把一组头凑到一起装载。我之前以为两家是同一个思路,读完论文才发现搞反了,这个反转恰恰是MSA kernel的核心创新。论文作者除了MiniMax还有北大和NVIDIA的人,kernel这块下了重本。
效率上论文给的数字:在一个109B参数的实验模型上,1M上下文时MSA的注意力计算量缩到了全注意力基线的1/28,H800上实测预填充(prefilling,把你那一长串输入读进去的阶段)快14.2倍,解码(decoding,逐字往外蹦的阶段)快7.6倍。
论文还挺老实地解释了为什么实测加速追不上28.4倍的理论值:建索引、挑top-k、聚集query这些动作本身都有开销。这种把丑话说在前面的写法,挺加分的。不过也得替读者问一句:这些数字全来自论文的实验模型,M3本体多大、实际跑起来快多少,论文没披露,只能等第三方实测。
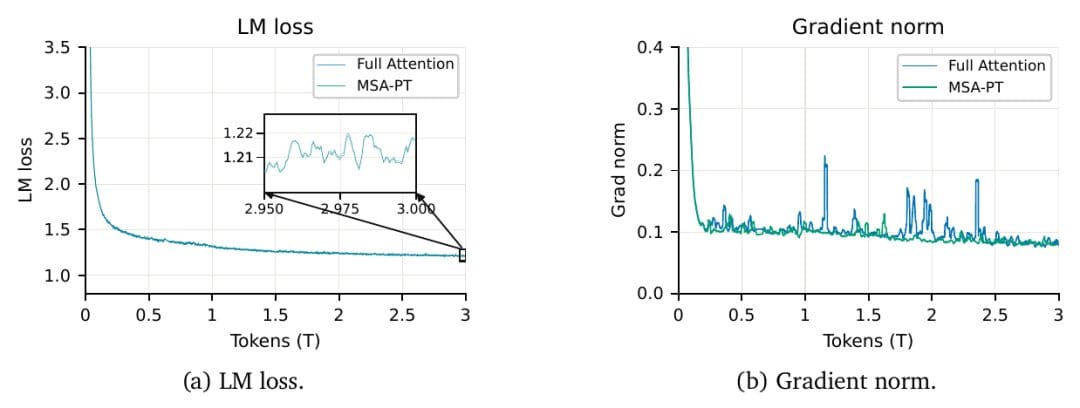
省了这么多,能力掉不掉?论文做了个3T token的对照实验:同一个109B模型,一个用全注意力训,一个从头用MSA训,loss曲线几乎重合。
下游benchmark上,从头稀疏训练的版本(论文里叫MSA-PT)不光没拖后腿,在长文本检索、数学、视频理解等好几项上反超了全注意力基线,RULER-8K一项84.2对79.8。
论文里还有条对行业可能更实用的路线:MSA-CPT,拿一个已经训好的全注意力模型,花400B token做继续训练,就能把它改装成稀疏注意力,能力几乎无损。换句话说,MiniMax 顺手把改装入口也对生态开了,以后Qwen、GLM 这些模型如果想做 1M 上下文,都有便宜的路可走。当然改装版也不是处处全赢:论文给它追加了128K的长文扩展实验,综合检索分还差全注意力0.6分,重排序任务差2分多。论文结尾承认这是残余差距,要靠更长的稀疏训练或者加大选择预算去填。
最后说说我觉得全论文最有意思的部分,附录。
附录里有张可视化图,把训练好的索引分支到底在挑什么画了出来,每个小图是一个头的选择概率热力图:
图里能看到三种模式:沿对角线的深色带(永远关注最近的内容)、最左边一条竖线(所有头都盯着开头几个token不放:注意力分数必须全部分出去,没什么值得看的时候,开头几个token就成了停车场,业内管这叫attention sink)、以及各组各不相同的斜向条纹(不同头各自负责回看不同距离的远程信息)。没有人教过它这些,全是KL对齐训练自己涌现出来的。
更有意思的是论文接下来的操作。既然sink现象这么普遍,要不要学GPT-OSS给每个头显式加一个可学习的sink参数?试了,没收益,砍掉。早期版本还强制索引分支必须选上开头第一块和附近的局部窗口,后来发现模型自己就会这么选,强制规则纯属多余,也砍掉。最终版只保留一条强制规则:当前token所在的块必选,防止模型连眼前的内容都不看。
这一连串「试过了,没用,砍掉」的负结果,比任何宣传语都更能说明MSA的设计哲学。论文开篇自己写了:遵循奥卡姆剃刀,消融实验做完,只留下必不可少的组件。
三、三国杀:三个分歧点
把主角讲透了,可以把四份方案摆上桌了。
先交代下NSA。它在2025年2月16号首发到arXiv,跟Kimi的MoBA(2月18号)前后脚放出,把稀疏注意力从实验室里的想法正式推到了台前。
但这俩还不是同一家同一个东西的两个版本:NSA和DSA是DeepSeek不同团队在不同时点的不同实现。NSA是论文,DSA是DeepSeek半年后(2025年9月29号)发布V3.2-Exp时落地的生产实现。同源思想,不同落地,论文里是三分支架构,DSA里改成更轻的Lightning Indexer做token级精挑。一个偏学术完备,一个偏生产效率。
到这里场上其实就三家公司:DeepSeek(手里捏着NSA论文和DSA实现两张牌)、Kimi(MoBA)、MiniMax(MSA)。到今天MSA发布,稀疏注意力差不多成了国产模型做长上下文的标配动作。
但标配不等于做法一样。这四份方案的分歧,集中在三个轴上。
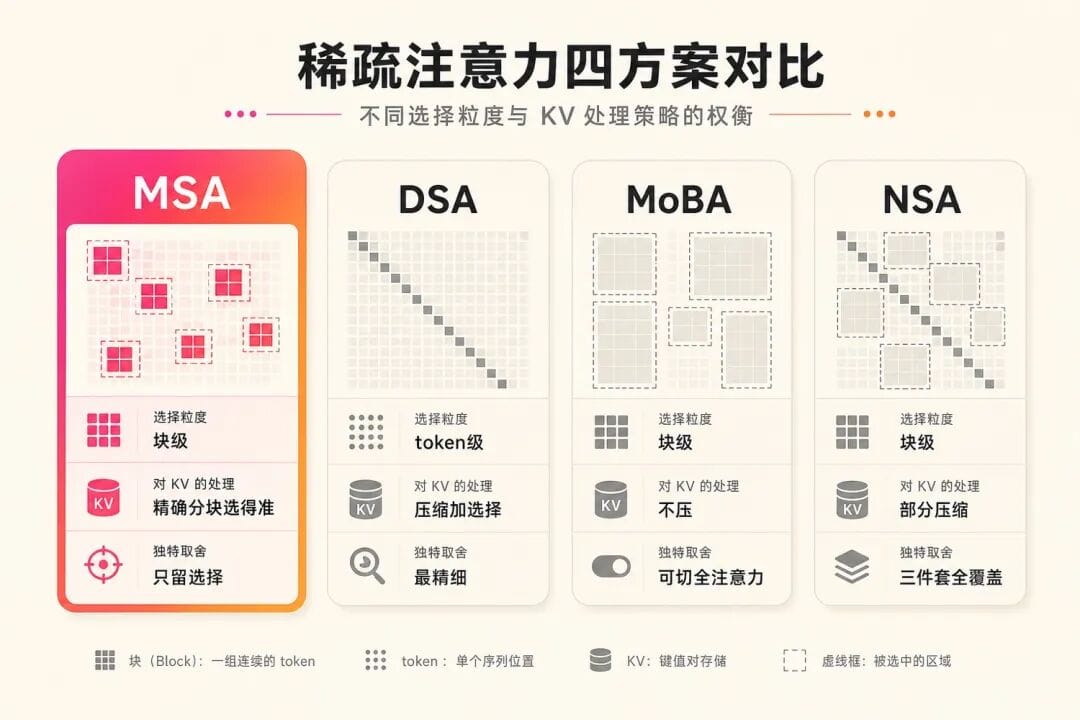
分歧一:挑得多细,token级还是块级
前面说稀疏注意力要挑相关的来算,那挑的颗粒度多大?
DeepSeek的DSA挑得最细,是token级。它的Lightning Indexer给每一个历史token单独打分(为了快,激活函数用ReLU、计算能跑在FP8低精度上),再精确挑出最相关的2048个token。
MSA和MoBA走的是块级。它们不逐个token挑,而是先把上下文切成块,以块为单位打分、整块整块地选。MoBA的打分方式更糙一点:把块内所有key向量取个平均当这块的代表,连额外参数都不引入。
这里有个对仗很工整的细节:DSA每个query挑2048个token,MSA挑16块乘128也是2048个token,预算一模一样,分歧全在颗粒度。
DSA赌的是逐token挑能捞到散落各处的零碎信息;MSA赌的是相关内容通常成段聚着,按块挑足够,而且块状的内存访问对GPU友好得多。MSA论文里点了token级方案一句:长上下文下,光是从一百万个token里做top-k挑选这个动作本身,就要占掉不可忽略的延迟。
还用读书那个比方。DSA像逐字挑出书里所有相关的词,MSA和MoBA像按段落、按章节来挑。前者更精准,后者更省事,赌的东西不一样。
分歧二:压不压KV
这一条是我觉得最有意思的分歧,藏着两种不同的信念。
DeepSeek这一路是两层叠加。底层有个叫MLA的设计,先把KV压成一个更小的潜向量再存,省显存(打个比方,与其存一张高清原图,不如存一张压缩过的小图,要用时再放大,放大了有点糊,但大轮廓都在,MLA干的就是这件事)。DSA再叠在MLA上头,在压缩后的KV上做token级的稀疏选择。它的官方报告里写得很直白,DSA是「建在MLA之上」的。DeepSeek又压又选,省显存这条线一以贯之。
MSA不压KV,是个纯选择器,论文原话叫selector-only design,KV原原本本存着,所有功夫都花在「选得准」上。
这背后像是两种不同的信念。DeepSeek觉得信息禁得起压,糊一点没关系,省下来的显存更值钱。MiniMax不这么看:要省就省在挑选上,真正要算的那一下,别糊。
分歧三:要不要辅助分支
NSA是个三件套结构,三条分支并行:一条压缩分支(把连续的块压成代表,看个大概),一条选择分支(挑最重要的块精算),还有一条滑动窗口分支(专门照顾最近的token)。三条各管一摊,最后用一个学出来的门控加权汇总,理论上覆盖得最全。NSA还有个挺巧的设计:选块用的重要性分数不另算,直接复用压缩分支算注意力时的副产品,几乎零成本。
MSA砍掉了另外两条,只留那个初筛加精算的选择动作。
我觉得这个减法本身就是一种态度,而且读完论文发现,这个减法是做了对照实验才下的手,不是图省事。论文专门拿一个计算量完全对齐的基线做了对比:同样的稀疏预算,固定只看开头一块加最近的窗口,在一堆agent任务上一致地更差。结论是位置固定的稀疏模式不如让模型自己动态挑。滑窗分支不是忘了做,是验证过不值得单独留。
还有个对比里常被忽略的角:MoBA。它和MSA同样是块级选择,但它有个自己的取舍,能在全注意力和稀疏注意力之间灵活切换。MoBA论文在百万上下文实验里的用法很实际:模型最后3层保留全注意力、其余层用MoBA,预填充阶段用稀疏、生成阶段切回全注意力。说明Kimi自己也清楚稀疏在哪些环节有短板,用混合配置绕开。
所以如果让我用一句话概括MSA,我会说:它更像NSA的减法版。把三件套砍成一件,赌的是工程上的简洁和好落地,而不是论文上的面面俱到。
三个分歧之外还有条暗线:那个挑块的小脑,是怎么教出来的。四家给了三种答案。NSA让它搭主结构的便车,端到端一起训;MoBA干脆不给它配参数,蹭主模型的学习信号;DSA和MSA不约而同选了第三种,单独给小脑找老师,就是前面讲过的KL对齐那套。越靠近生产的方案,越往第三种靠,生产级方案在训练配方上正在收敛。我猜这不是巧合:到了千亿参数的规模,训练稳定性比架构的优雅重要得多。
下面这张表把四份方案的取舍放一起,可能更清楚。
四、为什么「便宜」才是1M的真问题
讲完技术细节,退一步看。这四份方案折腾来折腾去,本质上都在干同一件事:把长上下文从能做变成用得起。
这件事的意义比1M这个数字本身大。长程Agent连干十几个小时、在百万行代码库里排查问题、把几小时的视频一次喂进去理解,这些更性感的能力,全都压在长上下文用得起这个前提上。底座便宜了,楼才盖得起来。
M3也有还没冲到顶的项。官方自己公布的成绩里有一项叫PostTrainBench的测试,M3拿了0.371,排在Opus 4.7(0.424)和GPT-5.5(0.393)后面。前沿也不等人,Anthropic已经更到了Opus 4.8,6月9号又放出了更强的Fable 5。但M3的强项是编程到前沿、原生多模态、真1M这三样能凑一块,而且开源。
我觉得把前沿能力带进开源世界这件事,本身就有分量:开源模型能拿到的能力上限,又被抬了一格。论文里还承诺MSA的推理kernel单独开源,不过截稿时它印的仓库地址还是404,等它放出来。
回到开头那个问题:为什么2026年大家都不约而同奔向稀疏注意力?
因为全注意力那条路,在1M这个量级上,经济账算不过来了。线性注意力又太激进,训练和质量上的坑还没填平。稀疏注意力是当下这个阶段,省钱和保质之间那个还算靠谱的平衡点。
这场仗的下一回合其实已经打响了。DeepSeek今年4月发布的V4,把1M上下文下每个token的推理计算量压到了V3.2的27%,KV cache更是只剩10%,靠的是压缩得更狠的新一代注意力方案。对照分歧二那条线看,DeepSeek把「压」的信念贯彻到了底;MiniMax刚刚交出的,是「选」的答卷。两边都不是纸上谈兵,是各自旗舰模型上的真金白银。
至于MSA、DSA、MoBA、NSA谁的取舍最对,现在下结论太早,毕竟四家押的注本来就不一样。DSA多花一笔打分成本,赌细粒度挑选物有所值;MSA赌的是选得准比压得狠重要;NSA要的是面面俱到;MoBA最实际,给自己留了随时切回全注意力的退路。
哪种赌注能赢,得等更多真实场景的长跑来验证。但有一点已经挺清楚了:长上下文这场仗,比的不再是谁能做到1M,而是谁能让1M便宜到随便用。
参考资料
- 《MiniMax Sparse Attention》论文:https://github.com/MiniMax-AI/MSA/blob/main/docs/MiniMaxSparseAttention.pdf
- MiniMax M3官方博客:https://minimaxi.com/blog/minimax-m3
- 《Why Did M2 End Up as a Full Attention Model?》:https://www.minimax.io/news/why-did-m2-end-up-as-a-full-attention-model
- DeepSeek DSA(V3.2,DSA instantiated under MLA):https://api-docs.deepseek.com/news/news250929
- NSA论文:https://arxiv.org/pdf/2502.11089
- MoBA论文:https://arxiv.org/pdf/2502.13189