
本文经原作者授权转载,版权归原作者所有。原作者:知野(@knoYee_)。
Fable 5 和 Mythos 5 是同一个模型。
区别只有一件事:
Fable 5 套了三层安全分类器,Mythos 5 没有。
你用 Fable 5 时,有些问题它不会直接回答。不是拒绝,是悄悄切到 Opus 4.8 替你处理。
我们需要知道在什么场景下会自动降级
三层分类器
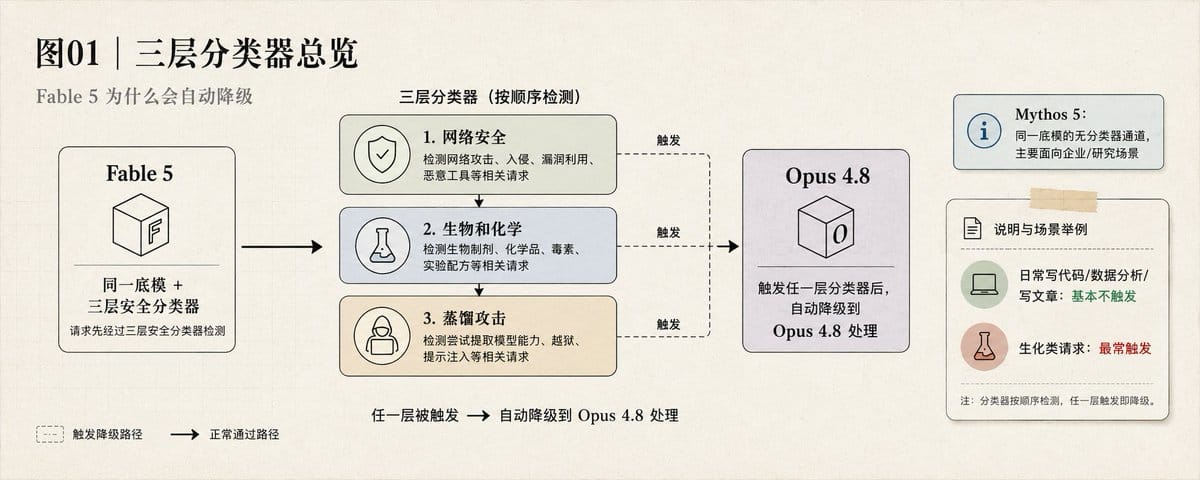
第一层,网络安全
检测漏洞利用和攻击性网络任务。
日常写代码、做数据分析、写文章基本不触发。
第二层,生物和化学
触发最频繁的一层。
Anthropic 说 Fable 5 在 AAV 病毒外壳预测等任务上超越了专用蛋白质语言模型。
能力太强了,所以对大多数生物化学请求实施降级。
学术界走 Mythos 5 通道,普通用户走 Fable 5 会被拦。
第三层,蒸馏攻击
检测大规模能力提取行为,防止通过大量 API 调用把模型能力迁移到另一个模型。
普通开发者基本不可见。
频繁调用 API 做微调相关工作可能触发。
大部分时候还是 Fable 5
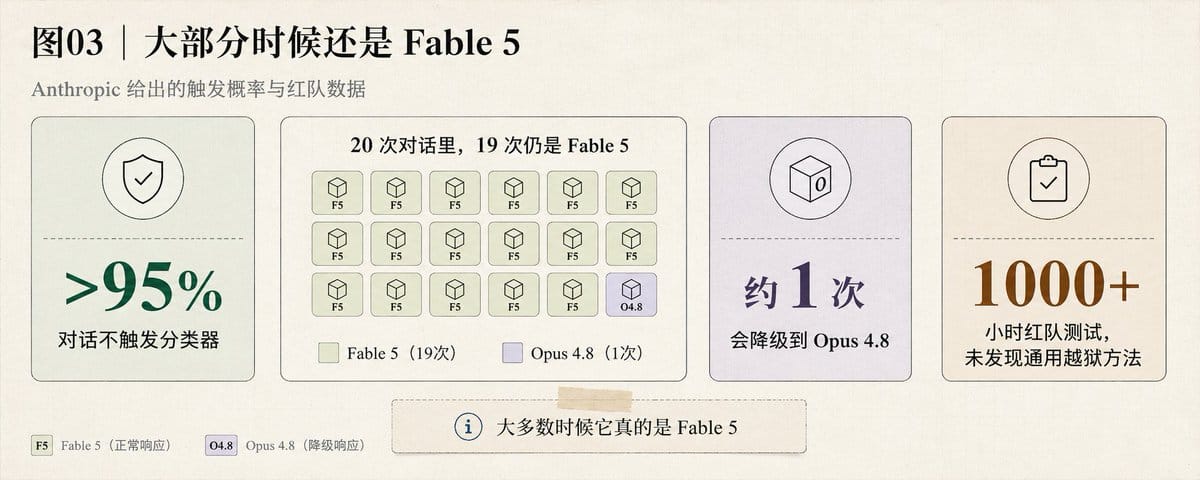
Anthropic 的数据:
- 超过 95% 的 Fable 对话完全不触发任何分类器。
- 20 次对话里,19 次实际跑的是 Fable 5。
- 1 次被降级到 Opus 4.8。
- 红队测试跑了 1000 多个小时,没有发现通用越狱方法。
降级不是拒绝
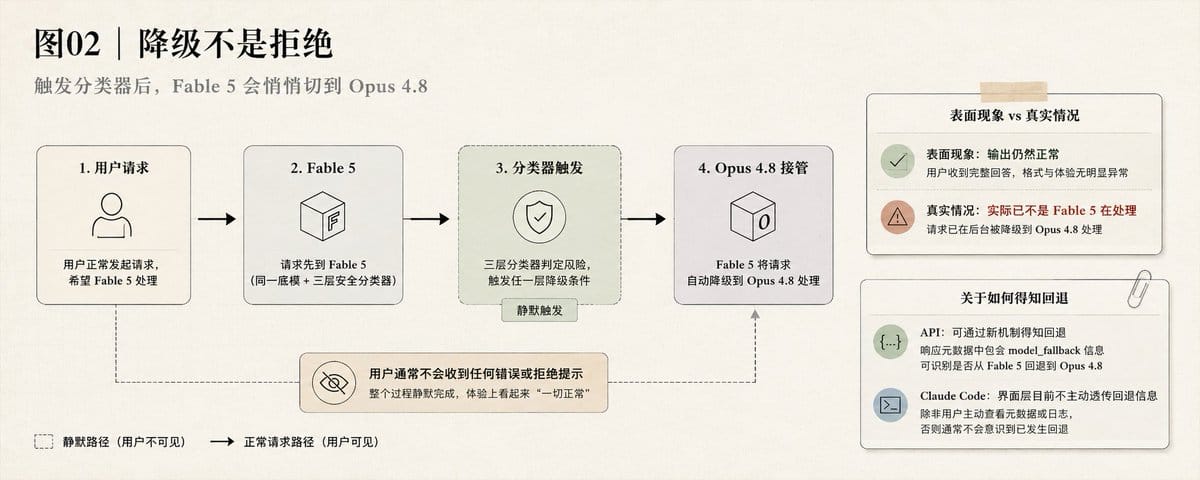
被拦截的请求不会收到错误。
Fable 5 直接不处理,Opus 4.8 接管。
输出看起来一切正常,只是质量不是 Fable 5 的质量。
API 有新机制通知回退,可以配成自动切模型。
在 Claude Code 里手动切成 Fable 5,如果某次回复质量感觉明显不对——比平时的 Opus 4.8 还不如——去 API console 查那段时间的请求有没有被降级。
Claude Code 界面层目前不主动透传回退信息。
分类器触发可能还在调
Simon Willison 实测时提到分类器触发频繁。
频繁到 API 需要专门的新机制来通知用户。
- 一个刚发布的模型分类器触发这么多,要么阈值还在调,误触率高。
- 要么 Anthropic 故意先保守跑一阵再放开。
两件事都可能。
如果我们感觉某次结果不对劲,第一个怀疑应该是它是不是实际跑在 Opus 4.8 上。
30 天数据留存
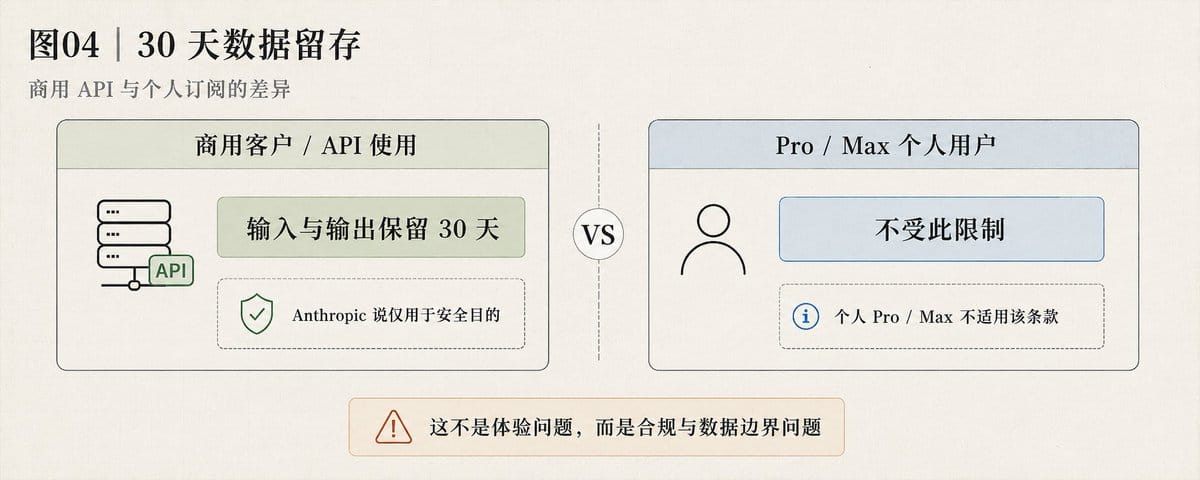
Fable 5 和 Mythos 5 有一个之前 Claude 模型没有的条款。
商用客户的流量必须保留 30 天。
Anthropic 说只用于安全目的。
通过 API 使用的,输入和输出会被存 30 天。
Pro 和 Max 个人用户不受此限制。
能力很强的地方也有边界

代码生成和推理比 Opus 4.8 强很多。
但不是全场景碾压。
速度比 Opus 4.8 慢
Simon 的体验是显著慢。
改几行代码、查一个函数用法、格式化一段文本——Fable 5 不如 Opus 或 Sonnet。
更慢,更贵,效果差不多。
上下文窗口 100 万 token
长时间 Agent 运行后还是会满。
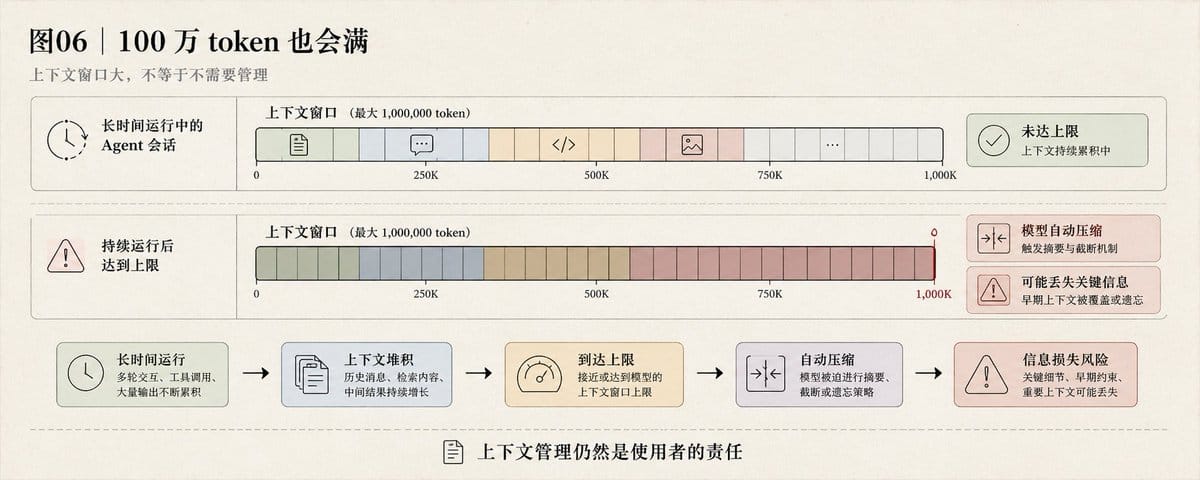
满之前没有压缩提示。
满了之后模型自己压缩,压缩过程中可能丢失关键信息。
和 Opus 的行为一样——上下文管理仍然是使用者的责任。
扩展推理的稳定性还有问题
Simon 测试了五种思考努力级别,high 级别消耗的 token 比 medium 少。
这在逻辑上不对——推理级别越高 token 应该越多。
说明扩展推理的调度机制还在调,不同级别之间的行为不是线性可控的。
Fable 和 Mythos 的边界不是固定的
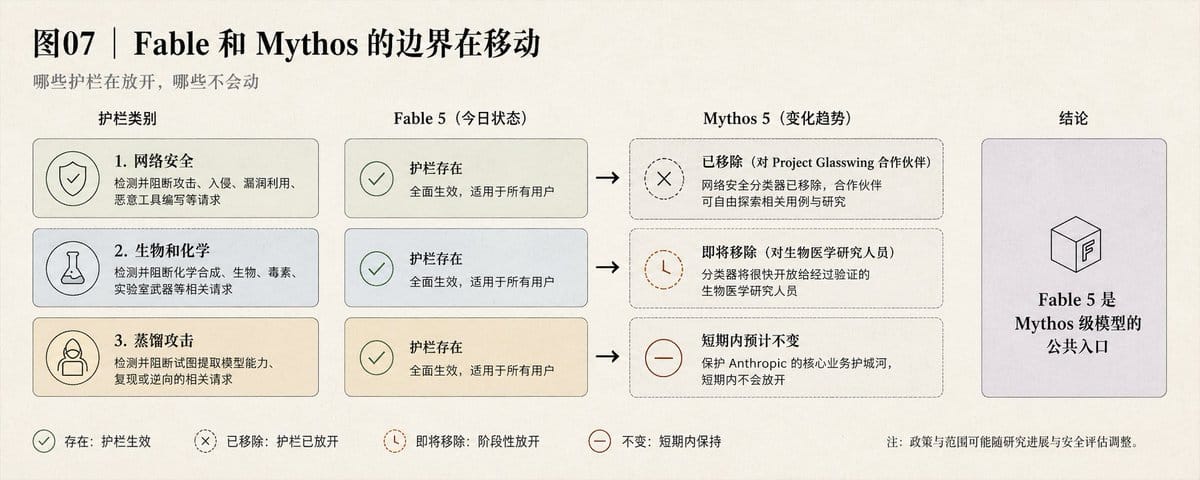
Fable 5 有全部三类护栏。
Mythos 5 没有。
这个边界在移动。
- 网络安全分类器在 Mythos 5 上已经移除,供 Project Glasswing 合作伙伴使用。
- 生物和化学分类器很快会对生物医学研究者开放移除版本。
- 蒸馏分类器短期内不会动——能力蒸馏是 Anthropic 的核心商业护城河。
最后
Fable 5 是 Mythos 级模型的唯一公共入口。
当工作碰不到三类护栏的情况下,它确实是我们能用到的最强 Claude 模型。