本文经原作者授权转载,版权归原作者所有。原作者:Xudong Han(@Xudong07452910)。
vibe coding搞了大半年,我慢慢摸出来一件挺让人无奈的事。
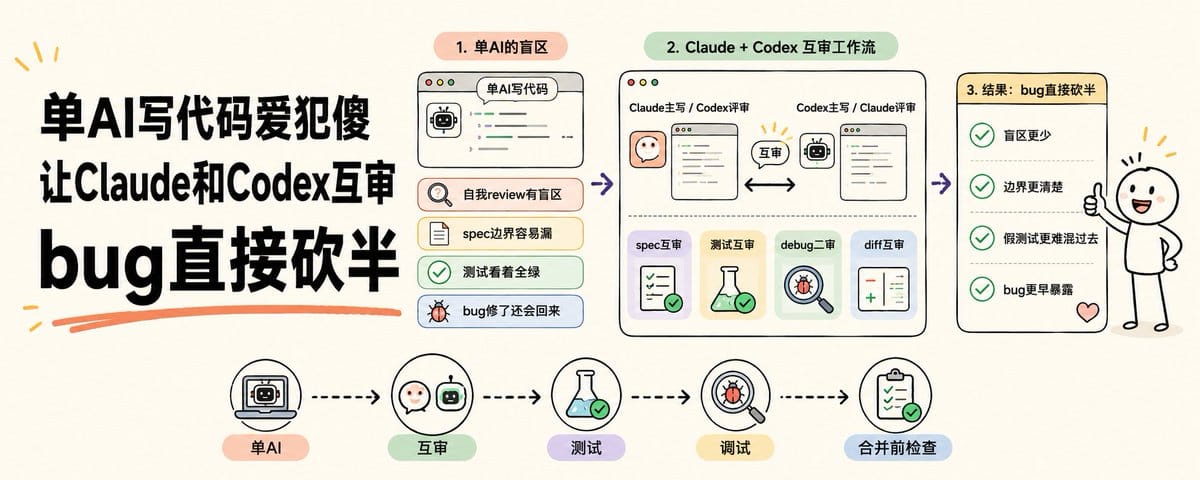
不管你用Claude Code还是Codex,单跑都有它自己的盲区。
Claude梳架构稳,偶尔抽象过头。Codex抠细节是一把好手,有时候看不清全局。最离谱的是,你让它review刚写完的代码,它几乎永远会跟你回一句「逻辑没问题」。
愚钝如我,踩了不知道多少次坑才反应过来。
自我review是人和AI共有的盲区。它review的根本不是代码,是它写代码那一瞬间脑子里的那套假设。当时怎么想的,现在还是怎么看。
破解办法说真的简单到不可思议,让一个不同厂商训练的AI来挑刺就完事了。Claude和Codex的训练数据、对齐策略、推理偏好都不一样,盲区天然不重合。一方写、另一方review,等于白嫖一份QA。
我自己这么跑了三个月,体感是spec歧义、边界遗漏、测试装样子这三类问题,互审至少能拦下60%。今天这篇就讲怎么配、怎么用。
一次性配好MCP互相调用
千万别开两个终端来回切,注意力一碎就什么都干不动了。正确做法是用MCP把两边注册成对方的工具,全程一个会话里跑。
Codex注册成Claude Code的工具,在Claude Code里执行
claude mcp add codex -- codex mcp-server注意是`codex mcp-server`,不是`codex mcp`。后者是Codex管理外部MCP server的子命令组,前者才是把Codex启动成MCP server的命令。我第一次配就栽在这上面,倒腾了一个小时才反应过来差了个`-server`。
反过来,Claude Code注册成Codex的工具
codex mcp add claude -- claude mcp serve两边都注册完,重启会话。你在Claude Code里直接说「让codex review一下」,它会自动调起Codex跑完把结果拿回来,反过来一样。整个过程注意力全程留在一个会话里,比两个终端来回粘贴舒服不是一个量级。
前置条件是两边都装好、登录过,强模型、思考强度、沙盒边界这些基础配置也得到位。不然review质量会肉眼可见地打折。
两种主流工作流
跑顺之后你会发现,互审其实有两种姿势,看活儿挑就行。
模式A,Claude主写 + Codex评审。适合绝大多数日常场景。Claude在长上下文、跨文件重构、文档生成、工程脚手架这些活儿上稳定性更高,让它扛主线最省心。每个关键节点(spec、测试、重要diff)丢给Codex二审。
模式B,Codex主写 + Claude评审。适合算法密集、底层调试、性能优化这些活儿。Codex在低层细节和数学推导上更稳,让它主写,Claude负责审整体架构和可读性。
怎么选呢,看你这次任务的瓶颈在哪。瓶颈在「想清楚整件事」用Claude主写,瓶颈在「抠对每一行」用Codex主写。两个都拿不准默认模式A,绝大多数活够用。
4个最该用的互审prompt
下面这4个我自己每周都在用,按价值排序。
1,spec互审。需求文档刚写完那一刻,是最值的一次review。
用codex review docs/spec.md,重点看,(1)有没有自相矛盾(2)有没有「快速」「友好」这种没说清的措辞(3)失败处理表是不是漏了常见case(4)有哪些隐含假设我没写出来。它的建议你逐条评估,同意的直接改spec,不同意的告诉我理由。
Codex经常会戳出Claude自己看不见的边界。比如「你说关键词是中文优先,那英文消息呢」「群是按ID指定还是按群名?群名会被人改」。这种问题Claude自己review自己的spec时,物理上看不到。
2,测试互审。让Codex不看实现只看测试,这一招狠到我现在还在用。
用codex review tests/test_xxx.py,不要看实现代码,只看测试本身。回答四个问题,(1)如果我把实现某一行删掉/改错,这套测试有多大概率变红(2)有没有哪条测试,实现写成「永远返回True」也能过(3)有没有哪条断言太弱(4)输入case覆盖有没有明显漏掉的方向。
Codex会精准把那些装样子的测试给你揪出来。我有一次被它点过,「你这个`test_long_message_truncation`只测了10000字能跑过去,但没断言判定结果是否仍然正确,其实只在测函数没崩,没测函数答对了」。一句话给我整不会了。
3,debug二审。复现脚本写好之后,让Codex独立诊断一遍。
用codex看tests/regression/test_xxx.py,这个测试当前是红的。请你不要看src/下任何代码,只根据复现脚本的输入和期望输出告诉我,(1)你猜根因在哪个模块(2)你猜的依据(3)建议的最小复现路径。
两家模型独立诊断,结论吻合的根因可信度极高。结论不一致的,恰恰是你最该深挖的地方。两个模型都答错的概率,比一个模型答错的概率小一个数量级。
4,重要diff互审。合并前最后一道闸门。
用codex review最近这次的diff,重点看,(1)有没有破坏现有公开接口(2)有没有偷偷加try-except吞掉真实错误(3)有没有跟spec不一致的行为(4)有哪些隐藏的并发/边界问题。给我一个红/黄/绿的评级和理由。
这一步看着多余,但你坚持一个月就知道它替你拦下来多少东西。
各自最适合的场景速查
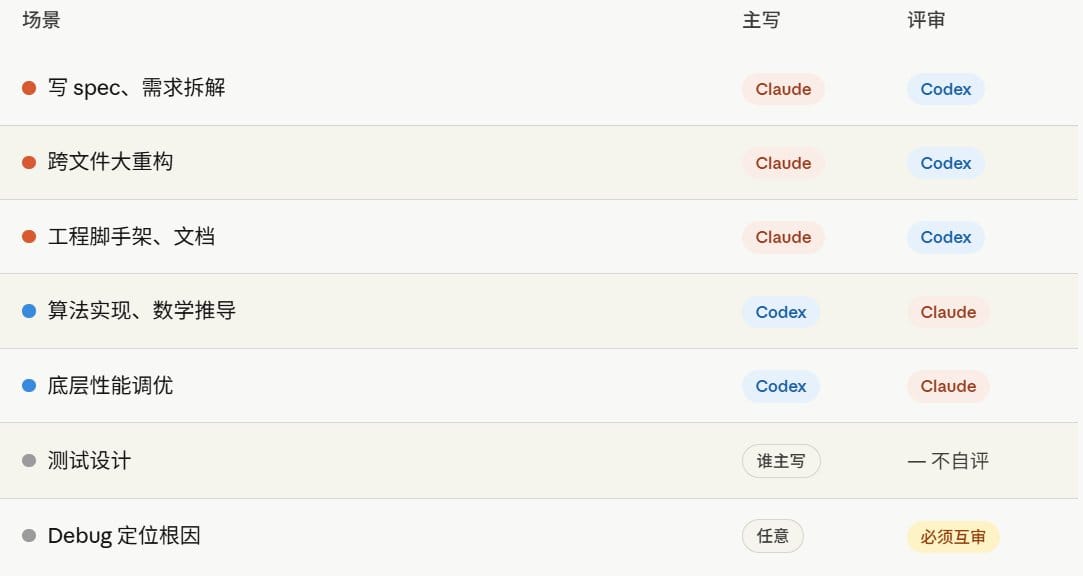
最值钱的两条铁律,测试一定要让没写实现的那一方写,debug一定要让对方在不看fix的前提下独立诊断。这俩是AI自我作弊概率最高的地方,没有例外。
几个新手最容易踩的坑
坦率的讲,互审也不是万能的,我一开始把它供成了神,照样踩了几次坑。
第一,别把互审当神坛。两个模型都答错的case也存在,互审是降低概率不是消除概率。结论一致不代表正确,只代表两边盲区没重合。最后拍板的永远是你。
第二,让评审方完整看上下文。spec、相关代码、复现脚本路径一次性给全,别让它脑补。上下文给不全,review质量等于猜。
第三,review冲突时千万别简单合并意见。让它们各自给出证据,你看完证据再拍板。直接「折中」最后两边都不满意。
第四,别每次都互审。重要节点(spec、测试、debug、合并前)必审,小修小补没必要,不然token账单让你怀疑人生。
写到这儿,我挺想多聊一句。
互审最大的价值不是「找到更多bug」,是给你一份廉价到不真实的第二意见。Claude加ChatGPT订阅一个月几十美金,跟真人reviewer的时薪比便宜得离谱。
更重要的是这俩评审员永远在线、永远没情绪、永远说真话。你同事看到你写得糟糕的代码可能还会客气两句,模型不会。它们不用照顾你的面子。
回到开头那句话,自我review是共有的盲区。
你想想看,人做不到完美自我review,是因为脑子里只有一套训练分布,过去十几年累积的经验和偏见。AI也一样,单一模型就是单一套训练分布。
但你让两个不同厂商训练的AI互相挑刺,相当于把两套独立分布叠在一起照着代码看。伪绿测试、模糊spec、症状疗法debug,一个看不见的,另一个看得见。
vibe coding时代真正稀缺的不是写代码的速度,是愿意挑你刺的对手。
两家不同训练分布的AI,把这件最贵的东西做成了一行配置命令。