
本文经原作者授权转载,版权归原作者所有。原作者:知野(@knoYee_)。查看原文 →
我相信大家在整理知识库时都有这样一个痛点:
优质的论文、好的想法被我们存入 Obsidian,资料越来越多,但可复用的结论却没有增加。久而久之,它们慢慢堆积成一个杂乱的仓库,甚至连我们自己也不愿意再去寻找。
今天我会从传统 RAG 讲起,带大家深度剖析 Agentic RAG 的工作原理,以及如何用 LLM Wiki + Obsidian 搭建第二大脑,实现数据飞轮。
一、传统 RAG 知识库
传统 RAG 的基本工作原理可以概括为:
- 将原始知识库切片,也就是 chunk;
- 将切片内容转成向量,存入向量数据库;
- 用户提问;
- 将 query,也就是用户问题,转成向量;
- 通过相似度检索找到相关切片;
- 将检索出来的切片连同用户问题一起交给 LLM;
- LLM 根据上下文生成回答。
简单来说,传统 RAG 的流程是:
原始知识库 → 切片 → 向量化 → 向量数据库 → 用户问题 → 相似度检索 → LLM 回答
但我们不难发现,在这个过程中存在一些明显漏洞。
1. 上下文丢失,导致检索失误
比如原文中写的是:
仅限于中国地区,某政策才会生效。
但如果切片或检索时上下文丢失,LLM 可能只看到后半部分,于是回答成:
该政策均可生效。
这就是传统 RAG 中常见的问题:切片本身可能破坏原文语境,导致 LLM 在回答时忽略重要条件。
2. 幻觉问题
当用户的提示 prompt 不够精准时,LLM 很容易自行补充不存在的信息。
比如原文只是说:
高级员工可报销大部分账单。
但 LLM 可能会回答:
高级员工可报销 80% 以上的账单。
这里的 “80%” 并没有来源,是模型自己补出来的内容。
3. 每次检索都需要从 0 开始
传统 RAG 每次回答问题时,通常都要重新从知识库中检索相关内容。
对于简单问题,这种方式还可以接受。
但对于复杂问题,比如需要跨论文、跨项目、跨时间线整合信息的问题,传统 RAG 往往处理得并不好。
它更像是一个机械检索系统,而不是一个真正会思考、会规划、会维护知识的系统。
二、为什么需要 Agentic RAG?
既然传统 RAG 只是机械地检索,那我们为什么不给它加一个“脑子”呢?
于是,Agentic RAG 应运而生。
简单来说:
Agentic RAG = Agent + RAG
Agentic RAG 不只是检索知识,它还具备:
- 规划能力;
- 调用工具的能力;
- 自我评估和检查的能力;
- 多轮任务拆解能力;
- 必要时重新检索和修正的能力。
它不再是一个静态检索系统,而是一个动态决策系统。
三、Agentic RAG 的工作流程
Agentic RAG 的完整流程大致如下:
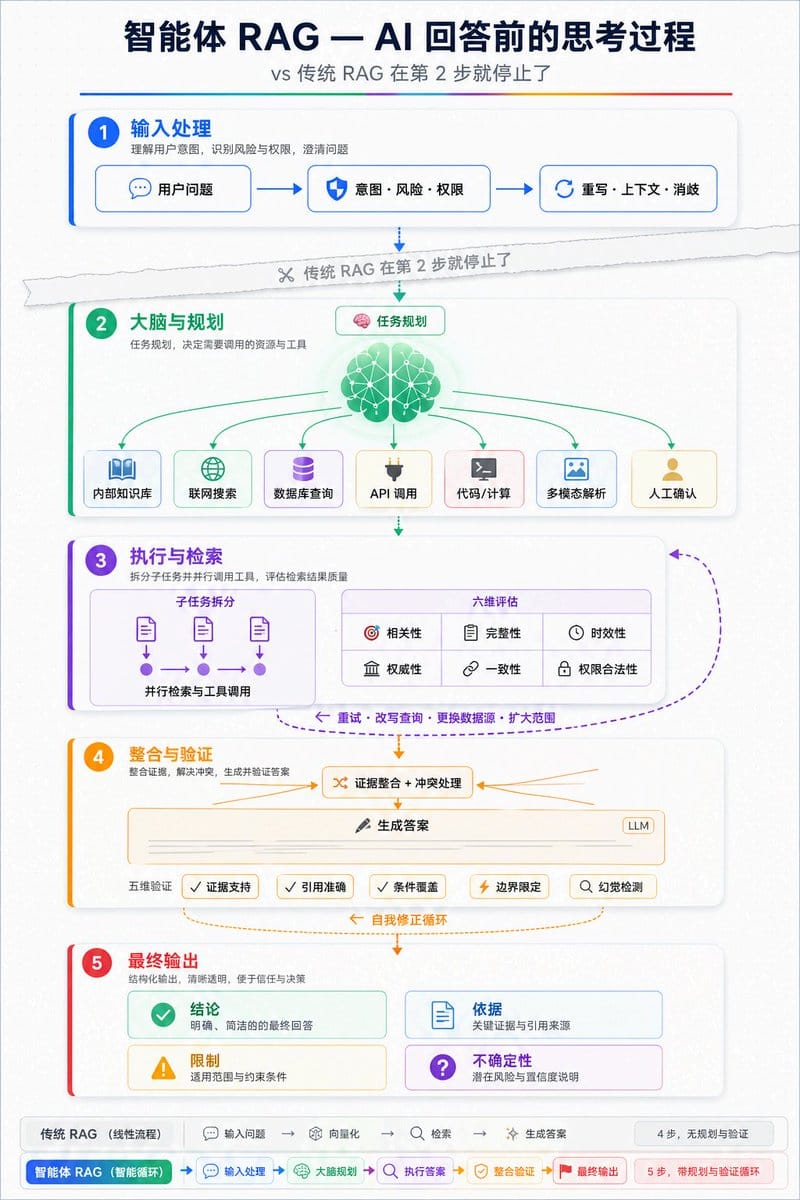
- 理解问题;
- 规划任务;
- 判断解决路径;
- 调用工具;
- 评估结果;
- 必要时重新检索;
- 生成答案;
- 验证答案。
也就是说,它不是简单地“搜一下然后回答”,而是会先判断:
- 用户真正想问什么?
- 这个问题是否需要拆解?
- 是否需要检索知识库?
- 是否需要联网搜索?
- 是否需要调用 API?
- 当前检索结果是否足够?
- 最终答案是否有证据支持?
四、Agentic RAG 的三个关键优化
1. 智能查询处理
Agentic RAG 会对用户的 prompt 进行优化和消歧。
当用户提出问题后,它不会立刻检索,而是会先尝试理解问题。
它会结合上下文和多轮对话,对用户问题进行重写。
如果问题比较复杂,它还会拆分和重组问题,最后形成一个更明确的任务范式。
例如,用户的问题可能是:
帮我整理一下最近看的 RAG 论文。
Agentic RAG 可能会将它拆解为:
- 最近看过哪些 RAG 论文?
- 每篇论文的核心观点是什么?
- 它们之间有什么相同点和差异?
- 是否可以归纳出一个知识框架?
- 哪些内容值得沉淀到长期知识库?
这就是智能查询处理的价值。
2. 动态决策与工具调用
Agentic RAG 拥有路由功能,可以进行多轮分支分析。
它会判断当前问题应该走哪条路径:
- 是否需要检索本地知识库?
- 是否需要访问外部网页?
- 是否需要调用 API?
- 是否需要查询数据库?
- 是否需要使用某个特定工具?
最后,它会将不同来源的信息动态整合起来,形成完整的任务计划。
这使得 Agentic RAG 不再局限于单次检索,而是能够处理更加复杂的任务。
3. 自我反思、评估和修正
Agentic RAG 会做两件重要的事。
第一件事,是对检索结果进行评估。
它会判断:
- 检索结果是否相关?
- 信息是否完整?
- 是否遗漏了关键上下文?
- 是否需要重新检索?
第二件事,是对最终答案进行修正。
它会检查:
- 答案是否有证据支持?
- 是否遗漏了关键条件?
- 是否存在无来源推断?
- 是否需要补充引用或重新组织回答?
通过这套流程,Agentic RAG 优化了从问题理解到答案生成的完整路径。
五、Agentic RAG 仍然没有解决的问题
Agentic RAG 已经比传统 RAG 更智能。
但它仍然有一个痛点挥之不去:
它在检索时仍然主要是从 0 开始理解。
对于长期问答来说,它并没有天然做到持续总结,也没有自动形成长期知识结构。
换句话说,Agentic RAG 更擅长解决“当下如何回答”的问题,但并不天然解决“知识如何长期积累”的问题。
如果每一次提问、检索、总结都没有被沉淀下来,那么下一次遇到类似问题时,系统依旧要重新开始。
这样就无法实现知识的复利增长。
这时,LLM Wiki 就顺势而起。
六、什么是 LLM Wiki?
LLM Wiki 不是 Agentic RAG 的替代,而是长期知识底座。
它不是只为了回答某一个问题,而是为了组织和维护长期记忆。
可以把 LLM Wiki 理解为:
一个由 LLM 辅助组织、更新和维护的长期知识系统。
它的核心目标不是“临时检索”,而是“持续沉淀”。
它让每一次阅读、每一次提问、每一次总结,都能够变成下一次可复用的知识资产。
七、LLM Wiki 的三层架构
LLM Wiki 可以分为三层。
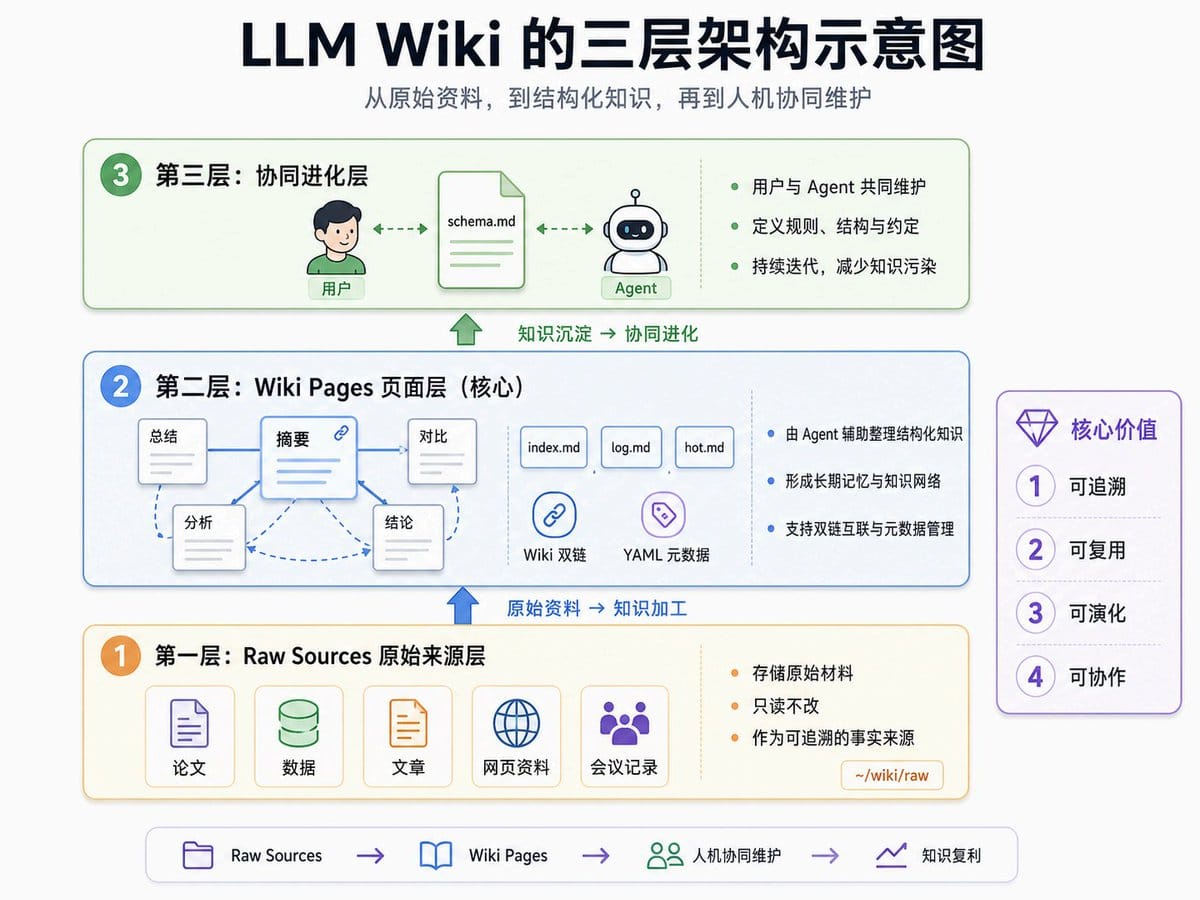
第一层:Raw Sources 原始来源层
路径示例:
~/wiki/raw
这一层用于存储原始资料。
包括:
- 论文;
- 数据;
- 文章;
- 网页资料;
- 会议记录;
- 项目文档;
- 原始笔记。
访问策略是:
只读不改。
Raw Sources 的角色是事实来源。
它是所有后续总结、分析、归纳的基础。
这一层非常重要,因为它保证了所有结论都可以追溯回原始材料。
第二层:Wiki Pages 页面层
这一层是整个 LLM Wiki 中最重要的一层。
它可以理解为 Agent 的结构化知识笔记,也是长期记忆的核心。
Wiki Pages 中存储的是经过加工后的知识,包括:
- 摘要;
- 总结;
- 对比;
- 分析;
- 结论;
- 主题页面;
- 项目页面;
- 方法论页面。
这一层不是简单复制原文,而是对原始资料进行知识加工。
它真正让知识从“资料”变成“可复用的结论”。
Wiki Pages 的导航文件
这一层可以设计三类导航文件:
- index.md
- log.md
- hot.md
1. index.md:总目录
index.md 相当于整个 Wiki 的总入口。
它负责告诉我们:
- 当前知识库有哪些主要主题;
- 每个主题下面有哪些关键页面;
- 新用户或新 Agent 应该从哪里开始阅读;
- 整个知识库的结构是什么。
2. log.md:更新日志
log.md 用来记录知识库的变化。
包括:
- 新增了哪些页面;
- 修改了哪些页面;
- 删除了哪些内容;
- 哪些结论发生了变化;
- 哪些来源被补充进来。
它的作用是让知识库的演化过程可追踪。
3. hot.md:重点高频页面
hot.md 用来记录高频使用或重点关注的页面。
比如:
- 最近经常访问的页面;
- 当前项目最重要的页面;
- 高频问题对应的页面;
- 值得复习和迭代的页面。
它相当于知识库中的快捷入口。
Wiki Link 与 YAML Frontmatter
Wiki Pages 中还有两个非常重要的机制。
1. Wiki Link 双链互联
Wiki Link 用来将不同的 Wiki 页面串成一个知识网络。
比如:
- [[Agentic RAG]]
- [[LLM Wiki]]
- [[Obsidian]]
- [[知识飞轮]]
- [[Source-first]]
通过双链,不同页面之间不再是孤立的,而是可以互相引用、互相连接。
这让知识库从普通文件夹变成了一个知识网络。
2. YAML Frontmatter 页面元数据
YAML Frontmatter 用来记录页面的元信息。
例如:
- 来源;
- 作者;
- 创建时间;
- 更新时间;
- 标签;
- 页面状态;
- 可信度;
- 关联主题。
示例:
--- title: Agentic RAG tags: - RAG - Agent - LLM status: developing source: - paper-a.pdf - article-b.md created: 2026-04-27 updated: 2026-04-27 ---
这样一来,每个页面都不只是文本,而是带有结构化信息的知识节点。
第三层:协同进化层
第三层是用户和 Agent 一起维护、迭代知识库。
这一层的核心文件是:
schema.md
schema.md 用来定义整个知识库的结构和约定。
例如:
- 页面应该如何命名?
- 标签应该如何使用?
- 什么内容可以写入 Wiki Pages?
- 什么内容必须保留在 Raw Sources?
- 当不同来源之间出现冲突时,应该如何处理?
- 页面状态如何定义?
- Agent 更新页面时需要遵守什么规则?
这一层的意义在于:
它把 LLM 从自由生成的写作者,规范成一个遵守 Wiki 规则的知识维护者。
有了 schema.md,LLM 不再是随意总结,而是按照既定规则参与知识库维护。
八、LLM Wiki 如何解决传统知识库痛点?
LLM Wiki 的出现,帮助我们解决了开头提到的几个问题。
1. 资料越来越多,但结论没有增加
过去,我们只是把资料存进去。
但 LLM Wiki 会进一步把资料加工成:
- 摘要;
- 主题页面;
- 对比页面;
- 方法论页面;
- MOC 路线图;
- 可复用结论。
这样,资料不再只是堆积,而是会被不断提炼。
2. 知识难以复用
通过 Wiki Pages、MOC、双链和标签,知识会被组织成网络。
下次遇到类似问题时,我们不需要重新从原始资料中翻找,而是可以直接进入相关页面。
3. 知识没有长期结构
传统 RAG 更像一次性问答。
而 LLM Wiki 会把每一次阅读、检索、总结和更新,都沉淀进长期知识结构中。
这就是知识复利的来源。
九、用 Obsidian 可视化 LLM Wiki
接下来,我们可以用 LLM Wiki + Obsidian 的方式可视化知识库。
只要 Wiki 以 Markdown 文件组织,我们就可以直接在 Obsidian 中打开 Wiki 所在的文件夹。
这样,知识库就会以本地 Markdown 的形式出现在 Obsidian 中。
我们可以利用 Obsidian 的能力来浏览和维护它:
- 双链;
- 标签;
- 图谱;
- 文件夹;
- 搜索;
- MOC;
- 插件系统;
- Canvas;
- 本地存储。
十、推荐的 Obsidian 目录结构
我建议目录可以这样设计:
wiki/ ├── index.md ├── schema.md ├── moc/ ├── pages/ ├── raw/ └── assets/
对应关系如下:
- index.md:总入口;
- moc/:主题地图;
- pages/:正式知识页面;
- raw/:原始材料;
- schema.md:知识库规范;
- assets/:图片附件。
十一、MOC:主题地图
首先,我想单独着重介绍一下 MOC。
我们对普通目录并不陌生。
普通目录通常是按照顺序罗列知识点,比如:
- 第一章;
- 第二章;
- 第三章;
- A 文件夹;
- B 文件夹;
- C 文件夹。
但当我们进行一个复杂项目时,所需的知识通常是交错分布在不同目录中的。
这时,MOC 的作用就体现出来了。
MOC 不是普通目录,而是一张主题地图。
它会把不同位置的知识点抽出来,围绕一个问题、一条路径或一个项目重新组织。
当我们下次再碰到类似问题时,就可以顺着 MOC 直接进入对应知识路线。
比如,一个关于 Agentic RAG 的 MOC 可以包含:
- [[传统 RAG]]
- [[向量数据库]]
- [[Query Rewrite]]
- [[Tool Calling]]
- [[Self-Reflection]]
- [[LLM Wiki]]
- [[Source-first]]
- [[知识飞轮]]
这样,MOC 就不只是目录,而是解决问题的路线图。
十二、双链交叉引用:构建知识网络
在现实中,我们经常会遇到这样的情况:
一个知识点 A,同时属于 B 类、C 类、D 类。
普通目录很难直观展现这种关系。
比如:
[[Agentic RAG]] 可能同时属于:
- [[RAG]]
- [[Agent]]
- [[知识管理]]
- [[第二大脑]]
- [[LLM 应用架构]]
如果只用文件夹分类,就必须把它放进某一个固定目录。
但通过双链,我们可以让同一个知识点同时连接多个主题。
这样,知识库不再是树状结构,而是网络结构。
这也是 Obsidian 最适合做第二大脑的原因之一。
十三、Source-first:让每个结论都可追溯来源
LLM 有一个通病:
当页面不完整时,它可能会自行补充。
这就会带来知识污染,也会带来风险。
所以我们需要 Source-first 机制。
Source-first 的核心原则是:
先保留原始资料,再整理 Wiki 页面,关键结论必须绑定来源。
具体来说:
- 原始资料放在 raw/ 中;
- Wiki 页面只能基于原始资料进行总结;
- 关键结论必须能追溯到来源;
- 没有来源的内容不能当成事实;
- 如果来源之间出现冲突,要在页面中标明冲突,而不是强行合并。
通过 Source-first,我们可以在很大程度上抑制 LLM 幻觉。
十四、页面生命周期:让知识持续更新
知识不是写完就结束。
知识是会变化的。
有些页面刚刚创建,还没有完善。
有些页面已经比较成熟。
有些页面可能已经过期。
如果没有生命周期管理,知识库很快又会变成新的混乱仓库。
因此,我们需要为页面标注状态。
例如:
- draft:刚创建;
- developing:正在完善;
- verified:已验证;
- stale:可能过期;
- deprecated:已废弃。
示例:
--- title: LLM Wiki status: developing created: 2026-04-27 updated: 2026-04-27 ---
有了页面生命周期,我们就可以知道:
- 哪些页面可以直接引用;
- 哪些页面还需要补充;
- 哪些页面需要复查;
- 哪些页面不应该再使用。
这会显著提高知识库维护的科学性。
十五、三层架构 + 四个高级用法
总结一下。
LLM Wiki 的三层架构是:
- Raw Sources 原始来源层;
- Wiki Pages 页面层;
- 用户与 Agent 协同进化层。
它的四个高级用法是:
- MOC 主题地图;
- 双链交叉引用;
- Source-first 来源优先;
- 页面生命周期管理。
这三层架构和四个高级用法组合起来,就形成了一套人机共同协作的知识库系统。
十六、数据飞轮如何形成?
真正的价值不只是存资料,而是形成数据飞轮。
这个飞轮大致是这样的:
- 阅读论文、文章和资料;
- 将原始内容放入 Raw Sources;
- Agent 辅助总结成 Wiki Pages;
- 用户审阅、补充和修正;
- 页面通过双链和 MOC 进入知识网络;
- 下次提问时,Agent 优先复用已有结构;
- 新问题继续产生新页面或更新旧页面;
- 知识库越用越清晰,越清晰越好用。
这就是知识复利的过程。
使用越多,结构越清晰。
结构越清晰,下一次复用成本越低。
十七、结语
在 AI 浪潮下,每一个想法都弥足珍贵。
真正重要的,不只是把信息保存下来,而是让信息变成可以复用、可以追溯、可以持续演化的知识结构。
LLM Wiki + Obsidian 的价值就在于:
它把零散资料变成长期知识,把一次性问答变成持续积累,把个人笔记变成可演化的第二大脑。
我今天的分享就到这里。
愿这篇推文可以给你带来收获。
下一期,我们手把手实操:如何搭建一个真正可用的知识库。