
本文经原作者授权转载,版权归原作者所有。原作者:知野(@knoYee_)。查看原文 →
相信大家是不是和我一样:
早上起来先刷 45 分钟推特,想看看有什么前沿资讯,结果淹没在一堆噪音中。
费尽心思,才找到两三篇可以细品的优质文章。
放进收藏里,再打开就不知道是什么时候了。

因此,我搭了一个每天早晨自动跑的 Research Agent。
Codex 驱动的。
跑了快两个月,分享一下详细的搭建过程和关键判断。
它的工作流程是:
- 在我碰任何信息源之前,Codex 已经替我把跟我工作相关的来源扫完,
- 过滤掉噪声,综合成一份结构化、五分钟能读完的 brief,
- 直接写进 Obsidian 库。

我醒来坐下,就可以直接进入工作状态。
Codex CLI + MCP + n8n。
我们需要把这三者串起来,这个工作流才能跑下去。
接下来是详细搭建流程。
从零搭一遍。
它实际做什么?
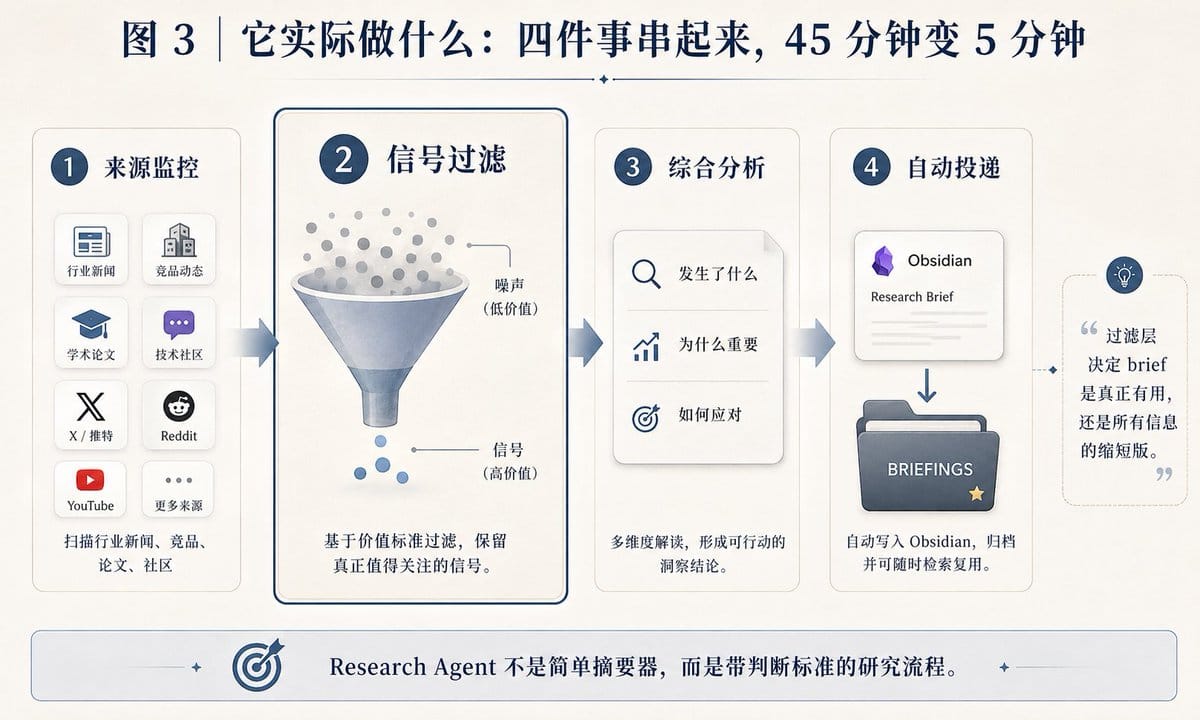
1. 来源监控
按你配置的清单读每一个信息源:
- 行业新闻、竞争对手网站、学术论文、newsletter、YouTube 频道研究内容、播客文字稿、GitHub 仓库、Reddit 子版块……
2. 信号过滤
按你定的标准分信号和噪声。
- 竞争对手发了新产品——信号。
- 一篇复述上周内容的博客——噪声。
过滤层决定了 brief 是真正有用,还是所有信息的缩短版。
3. 综合分析
不列 bullet points 交差。
写成结构化叙述:
- 发生了什么、为什么值得关注、跟你已知的事有什么关联、你可以怎么应对。
4. 自动投递
每天定时把 brief 放到 Obsidian 库的指定位置。
不靠手动触发。
四项串起来,45 分钟信息搜集变成 5 分钟阅读。
四个组件
1. Codex CLI
智能层兼执行层。
- 读来源里的原始信息,用你给的标准过滤重要内容,综合成结构化 brief,通过 MCP 直接读写 Obsidian 库。
- 不需要 Desktop 界面。
- 终端里的一个命令就能跑。
这是 Codex 做这件事最顺手的地方:
它生来就是命令行工具,定时任务、文件读写、MCP 调用都是原生能力。
2. Brave Search MCP
实时搜索能力。
- 有了它,能搜索实时网页,获取指定主题的最新动态。
- 免费层每月 2000 次查询,每天跑一次完全够用。
API key 在这里获取:
https://brave.com/search/api
3. 配置 Codex 的 MCP
在 Codex 配置文件里加这两段:
{ "mcpServers": { "filesystem": { "command": "npx", "args": [ "-y", "@modelcontextprotocol/server-filesystem", "/path/to/obsidian/vault" ] }, "brave-search": { "command": "npx", "args": [ "-y", "@modelcontextprotocol/server-brave-search" ], "env": { "BRAVE_API_KEY": "your-key" } } } }
- 第一,能访问实时信息源。
- 第二,能把结果写回你的本地知识库。
- 搜索能力解决输入。
- Filesystem MCP 解决输出。
二者接上,Research Agent 才不是聊天机器人,而是一个能持续工作的早报系统。
4. n8n
整个系统的调度心脏。
每天在你设定的时间触发 Research Agent,把 prompt 和背景信息一起传给 Codex,接收输出,保存到库。
可以自托管在每月约 5 美元的小服务器上。
- DigitalOcean 开一个基础 Ubuntu droplet,SSH 进去,npm 装 n8n,配成 service。
第一次搭大约半小时。
之后所有自动化工作流都可以复用这套基础设施。
5. CODEX.md
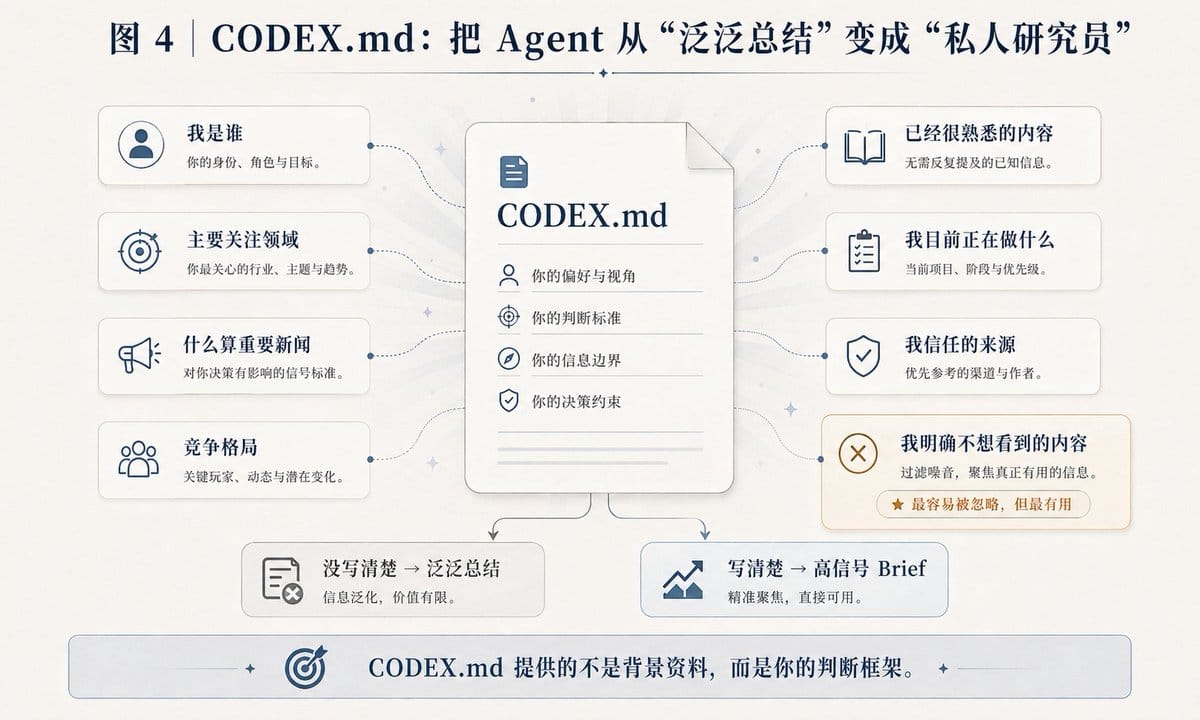
CODEX.md 是研究和决策背景。
这个文件决定了 brief 是跟你个人相关,还是任何人都能读的泛泛总结。
它告诉 Codex 四件事:
- 你是谁。
- 你关心什么。
- 你已经知道什么。
- 你现在正在做什么。
第一步:写 CODEX.md
这一步做对还是做废,直接决定产出质量。
在 Obsidian 库里创建:
Research Agent Context
- 我是谁
- [名字、角色、所做的工作]
- 我的主要关注领域
- [具体列出需要跟踪的主题、行业、领域]
- 对我来说什么算重要新闻
- [具体。不是“AI 新闻”,而是“Codex CLI 更新、新 MCP server 发布、多 Agent 框架、AI Agent 安全进展”]
- 我的竞争格局
- [你监控的具体公司、人物和产品]
- 我已经非常熟悉的内容
- [有深厚经验的领域——只需要真正重要的新动态,不要入门覆盖]
- 我目前正在做什么
- [活跃项目。相关新闻可以直接转化为行动。每周更新。]
- 我信任的来源
- [值得优先处理的具体 publication、newsletter、researcher、YouTube 频道、subreddit]
- 我明确不想看到的内容
- [你领域里常出现但浪费时间的主题。泛 AI 炒作文章、重复内容、不关心的公司公告。]
- Brief 格式偏好
- [你希望输出怎么组织]
- “我明确不想看到的内容”是大多数人会跳过的章节,也是最有用的一章。
写清楚了,过滤更激进,brief 只留真正可能行动的信号。
信息来源也要配。
Brave Search 给覆盖面,但最有价值的信息源——特定研究员博客、竞品发布页——需要直接列出来。
写进“我信任的来源”,加上具体指令。
比如:
- “每日检查 HN 首页 AI 与开发者工具相关内容。”
- “每周扫 arxiv.org/cs.AI 本周重要论文。”
第二步:写 research prompt

这是每天早晨运行的核心 prompt,放在 n8n 工作流里发给 Codex:
你是我的个人 research agent。请生成我的晨间简报。
先读我库里 CODEX.md 的 research context。
然后执行以下流程:
步骤 1:主要主题搜索
对 research context 中每个关注领域,搜索过去 24 小时重要动态。
步骤 2:信号过滤
纳入:
- 我关注的公司或工具发的新产品 / 重大更新
- 会改变我们对某领域理解的研究发现
- 竞争对手的战略行动
- 影响我所在领域的监管或政策变化
- 值得了解的新工具、框架、技术
排除:
- “明确不想看到”章节中注明的任何内容
- 复述 48 小时前已发布信息的二次内容
- 没有新增信息的观点文章
- 不关注的公司的公告
- 缺乏具体可行动细节的泛 AI 炒作
- 某分类没有重要事发生,直接写“今天没有”,不填充
步骤 3:竞争情报
专门搜竞争格局中列出的公司和人物。
突出战略转变、新品发布。
步骤 4:综合输出
严格按以下格式:
晨间简报 - [DATE]
生成时间:[TIME]
今天最重要的一件事
[今天最重要的单项动态。一段说明它为什么对你重要。]
发生了什么
[3-7 项。每项含来源 / 公司 / 主题、发生了什么、为什么跟你的工作有关。每项 1-3 句。]
竞争动态观察
[竞争格局中的重要行动。无则写“今天没有重要动态”。]
可采取的行动
[1-3 个具体行动。只有真正可行动时才写。]
深入阅读
[与今天首要事项相关的 2-3 篇完整文章链接]
重要格式规则:
- 整份 brief 五分钟能读完
- 每一项必须直接对应 research context 中的某个内容
- 不填充,不闪烁其辞
- 重要就说清楚为什么重要
- 今天新闻平淡,直接说明平淡
- 保存到:BRIEFINGS/[YYYY-MM-DD]-morning-brief.md
第三步:搭 n8n 工作流
五个节点。
节点 1:Schedule Trigger
设为早上 6 点。
在你打开电脑前,brief 已经生成好了。
周一至周五:
0 6 * * 1-5
包含周末:
0 6 * * *
节点 2:Read File
读取库里 CODEX.md 的完整内容。
节点 3:Code
把 prompt 和 CODEX.md 内容拼成 API 请求:
const codexMd = $node["Read CODEX.md"].json.content; const today = new Date().toISOString().split('T')[0]; const time = new Date().toLocaleTimeString(); const systemPrompt = `你是个人 research agent。 今天是 ${today},当前时间 ${time}。 可通过 Brave Search MCP 访问实时搜索,请充分使用。 用户的 CODEX.md research context: ${codexMd}`; return { model: "gpt-5-codex", max_tokens: 4096, messages: [ { role: "system", content: systemPrompt }, { role: "user", content: "请按 research context 中规定的格式和指令,生成我的晨间研究简报。" } ] };
节点 4:HTTP Request
调用 OpenAI API:
URL: https://api.openai.com/v1/chat/completions Method: POST Headers: Authorization: Bearer [你的 OPENAI_API_KEY] Content-Type: application/json
Body 使用节点 3 的输出。
节点 5:Write File
把结果写进 Obsidian 库:
const response = $node["Codex API Call"].json; const content = response.choices[0].message.content; const date = new Date().toISOString().split('T')[0]; return { filename: `${date}-morning-brief.md`, content: content };
路径指向:
/your/vault/path/BRIEFINGS/${date}-morning-brief.md
可选节点 6:Telegram 通知
brief 投递后,手机收到提醒。
你甚至可以在起床前先看完。
第四步:接上反馈回路
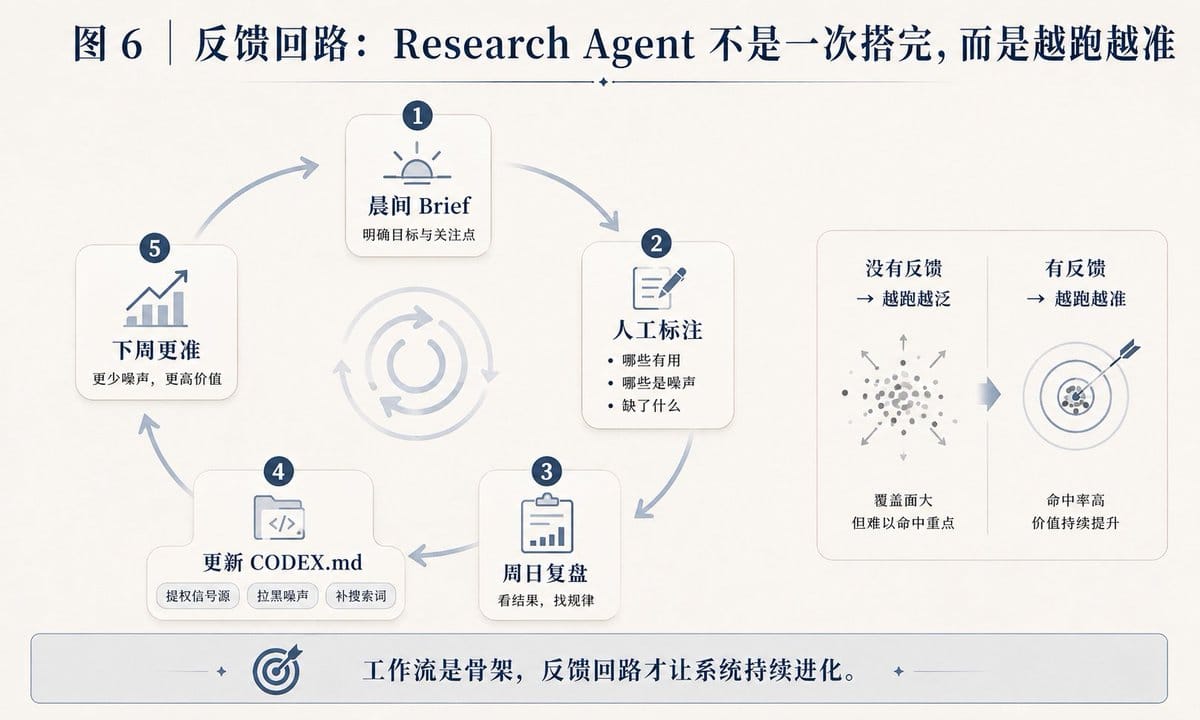
这是整个系统里最容易被跳过、但决定 brief 是越跑越准还是越跑越烂的一步。
每次读完 brief,花两分钟在文件底部写标注:
我对这份 Brief 的笔记
[哪些有用、哪些是噪声、缺了什么]
- 每周日,让 Codex 读过去一周所有 brief 和你的标注,更新 CODEX.md。
- 持续产出信号的来源,提权。
- 持续产生噪声的主题,加进“不想看到”清单。
- 反复缺失的信息类型,补充搜索关键词。
- 被标记为“有用”的内容模式,记录为明确偏好。
有了这个回路,到第三个月,brief 对你的信息需求会比第一周校准得准确得多。
扩展方向
- 1. 主题深挖
哪天 brief 里出现重大动态,扔进 deeper research 队列。
队列处理器自动对该主题跑一次全面 research,生成详细分析笔记,不等到第二天。
- 2. 竞争情报即时提醒
配一条轻量工作流,每四小时查一次竞品新闻。
发现重要动态,立刻 Telegram 通知,不等晨间 brief。
- 3. 周报
周日不跑标准日报。
让 Codex 读过去七天的七份日报,生成周报:
- 本周最大主题是什么。
- 对你所在领域长期意味着什么。
- 最重要的单条动态你要怎么应对。
- 你预期发生但没发生的事意味着什么。
但搭完只是第一步
第一周你大概率会发现 brief 还不够准。
有些内容你觉得有用但没出现。
这不是系统有问题,是 CODEX.md 还没被真实反馈打磨过。
接下来要做的事,比搭建更重要:
- 持续调控。
- 每次读完 brief,写两行标注。
- 每个周日花十分钟扫一眼当周标注,改 CODEX.md。
- 该提权的提权,该拉黑的拉黑。
- 缺什么信息类型,就补一句搜索指令。
- 第二周会比第一周准。
- 第一个月会比第二周更准。
你的关注方向会变,项目在推进,CODEX.md 也要跟着动。
工作流是骨架。
后期的打磨,才决定它能不能真的成为你的研究系统。
这只是一条路,大家也可以搞一个云服务器来完成,也可以实现24小时在线的效果。