
本文经原作者授权转载,版权归原作者所有。原作者:实践哥MinLi(@MinLiBuilds)。查看原文 →
剪映的自动字幕要充会员,一年 ¥599。钱掏了,识别也就七成准:专有名词全错、语速一快整句漏掉、错别字一串,剩下的还得你一条条对着时间轴手补。花了钱,活还得自己干一半。
我嫌烦。正赶上 Claude 4.8 上市,我就去 ZenMux 上用上了它,写了个 skill 把这事彻底干掉:免费、全本地、还会自己通读纠错。录完口播把视频往 Claude 里一拖,说一句"加字幕",几分钟拿回成片,全程不打一个字。连“程序员”听成“程序儿”、“会议纪要”听成“会计记药”这种同音错,它都自己改对了。
空口无凭,直接上成品:下面这段 Anthropic 的英文演讲,我给它配的中英双语字幕,中文在上、英文在下,整段烧进画面,从听写、翻译到烧录我一个字没敲。
这篇就拿它当例子,把怎么写一个 skill讲明白。读完你会拿到三样东西:原理你懂了、门槛就一条命令、GitHub 链接在手。手痒了,今晚就能自己做一个出来。
导读:不用从头啃
按你现在的状态挑着看就行:
- Step1 原理解释,搞清楚提取字幕的原理。
- Step2 一个 Skill,今天就能用上。
- Step3 想自己照着写一个,五步列齐。
- 彩蛋,用 zenmux 调用 Claude Opus 制作和调用这个 skill
放心,全文你一条命令都不用自己敲。
Step1 原理解释:别慌,这是你的第一个本地小模型
先介绍whisper(openai 开源模型),这套流程里负责"听写"的耳朵。对很多人来说,这可能是你第一次在自己电脑上跑一个"模型"。一听"本地跑模型"就脑补显卡轰鸣、命令行报红?先深呼吸,完全不是那么回事。
说人话,whisper 就是一个轻量的装在你电脑上、专门把语音听成文字的小程序:
- 不联网:视频不上传、不进云端,全在你这台机器上算完,隐私零担心。
- 不花钱:开源免费,跑多少次都不要钱。
- 不用你装:第一次跑时 Claude/Codex 自己把它(连识别模型)装好,你只管把视频拖进去。
所以"本地跑模型"落到你身上,其实就是:你拖个视频,电脑后台默默把语音听成了字。体感跟装了个新 App 没区别。这道很多人觉得最高的坎,你一抬腿就过了。
三个角色:这活该拆给谁干
写 skill 最容易犯的错,是上来就让 AI"做一个加字幕的工具",它会把识别、纠错、烧字全塞进一坨代码,跑不准还没法改。
正确的第一步是先把活拆开,看每段谁最擅长。加字幕拆下来正好三个角色:
- whisper“耳朵”:把声音听成文字,还一句一句记下每句的精确时间。
- Claude/Codex:校对 whisper 的错误,沉浸式翻译。
- ffmpeg:把字幕永久印进画面,哪个平台都能看。
连起来就是一条流水线:
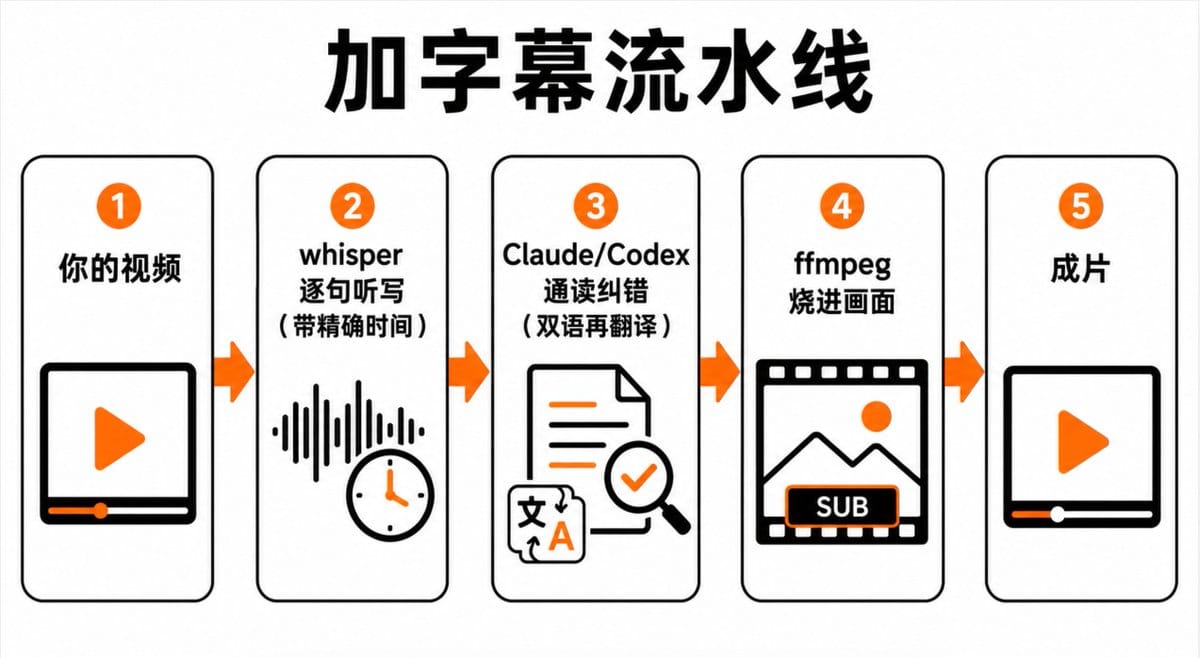
凭什么比剪映准?whisper 是一句一句记真实时间的,不像很多工具只给个大概、一长就对不上嘴;小模型翻译有错,这正好是 Claude/Codex 的活,剪映给不了。它现读现判列一张修正表,脚本只管照着批量替换。
写 skill 的第一原则:按"谁最擅长"拆活,确定性的手艺活(抽音轨、烧字)交给脚本,需要理解判断的那一步(纠错、翻译)留给模型。想清楚这条,skill 就成了一半。
顺带一提:英文视频配“英文原文 + 中文翻译”双语字幕,不用另写 skill,同一条流水线上,让 whisper 按英文识别、Claude/Codex 顺手翻译、换个双语样式就行。好 skill 的扩展是"加分支",不是另起炉灶。
Step 2 跑起来:下载、一条命令、说一句话
说了半天原理,这段最实在:真就三步,命令总共一条。
① 一个 prompt,安装过程会引导安装本地模型:
帮我安装这个 skill: git clone https://github.com/limin112/video-subtitle ~/.claude/skills/video-subtitle② 重启一下 Claude Code,让它认到这个新 skill。
③ 把视频拖给它,说一句:"给这个视频加字幕。"(想要双语就说"配中英双语字幕"。)完事。
会不会卡在装环境上?不会。whisper、识别模型、烧字用的完整版 ffmpeg,全是 Claude/Codex 第一次运行时替你下、替你装,你一条命令都不碰;它只会问你一句"要下个约 1.6GB 的模型,行吗",点头就行。装完往后每个视频秒进。
Step 3 你也能照着写一个 skill
想用的看到这就够了。想自己写一个的再往下看,其实没那么玄。
skill 本质就是一个文件夹,这个加字幕 skill 摊开就仨东西:
video-subtitle/ ├── SKILL.md ← 唯一必需:给 Claude/Codex 的说明书 + 干活步骤(它的大脑) ├── scripts/ ← 干活的小工具(抽音轨、排版、烧字这些手艺活) └── references/ ← 深水区细节,用到再翻
你可能会问:我又不懂技术,怎么知道该用 whisper、用 ffmpeg?这些全可以跟 AI 聊出来。只把需求一说:"想在本地把语音转成带时间点的字、还要能烧进画面",Claude/Codex 就把 whisper.cpp、ffmpeg 这些现成轮子挑出来、讲清楚各自干啥、还帮我比了几个方案。你负责说清楚要什么,技术选型交给它,这正是不懂代码也能写 skill 的原因。
照这五步,今晚就能搓出你第一个:
- 挑对题:找一件"已经有好工具、但中间缺一步判断"的活。加字幕就是:whisper 能听、ffmpeg 能烧,就差中间'这词到底是哪个'的判断,正好 Claude/Codex 补上。
- 按"谁最擅长"拆角色:手艺活写脚本,需要读懂内容的判断留给模型现场做。
- 脚本全参数化别写死:能探测的探测、该当参数的当参数,换个视频不改一行代码。
- 把坑写进 SKILL.md:你踩过的每个坑(比如"whisper 不吃视频、得先抽音轨""系统自带 ffmpeg 烧不了字、要装完整版")都写成一句"注意"。skill 的本质,就是把你踩过的坑,固化成 Claude/Codex 下次的默认动作,你踩一次,它和所有下载的人都不再踩。
- 测一遍:对着 SKILL.md 自查一遍,再拿两三个真实视频跑,错了把现象贴回去让它改,三五轮就稳。
嫌从零写麻烦,用官方的 skill-creator(Claude)或 $skill-creator(Codex)访谈着生成一版,再按上面五步 review。工具能帮你写,质量得你自己把关。
链接放这了,免费、开源、不限次数:
https://github.com/limin112/video-subtitle
到这儿三件事齐了:原理你懂了(whisper 听 + Claude/Codex 校 + ffmpeg 烧)、门槛就一条命令、下一步明明白白(重开 Claude/Codex,拖个视频说"加字幕")。手痒了别忍,现在就把那行 clone 敲进去,挑条手边的视频亲手跑一遍,把剪映那 599 省下来。
再省一笔:把模型这步挂到 ZenMux
接下来恰个饭。
整条流水线里,whisper、ffmpeg 都在本地白跑,唯一烧 token 的就是 Claude/Codex 纠错 + 翻译那一步。而这步用不上顶配模型,读懂内容、按格式吐回来就够,挑个便宜又够用的轻量款最划算。
开头说我去 ZenMux 用 Claude 4.8,就是图这个:一个 key 接各家模型,新模型上线还常免费开放。在 ~/.zshrc 里加个小函数,专门用它启动 Claude Code 来跑这个api:
export ZENMUX_API_KEY="sk-ai-v1-xxx"
# 换成你在 zenmux.ai 注册拿到的 key
claude-zenmux() {
ANTHROPIC_BASE_URL="https://zenmux.ai/api/anthropic" \
ANTHROPIC_AUTH_TOKEN="$ZENMUX_API_KEY" \
ANTHROPIC_API_KEY="" \
API_TIMEOUT_MS=30000000 \
claude "$@"
}重开终端后用 claude-zenmux 代替 claude 启动,再跑加字幕,纠错/翻译那步就走 ZenMux 上你指定的便宜模型了。想换模型就改那三行的型号,哪个新模型免费就薅哪个。这下 whisper 免费、ffmpeg 免费、模型这步也挑便宜款,整条流水线几乎不花钱。
跑通了再往前一步:挑一件你天天重复、又"就差中间一步判断"的活,照那五步写出你自己的第一个 skill。写出来了,回评论区告诉我你做的是啥。