
本文经原作者授权转载,版权归原作者所有。原作者:Berryxia.AI(@berryxia)。
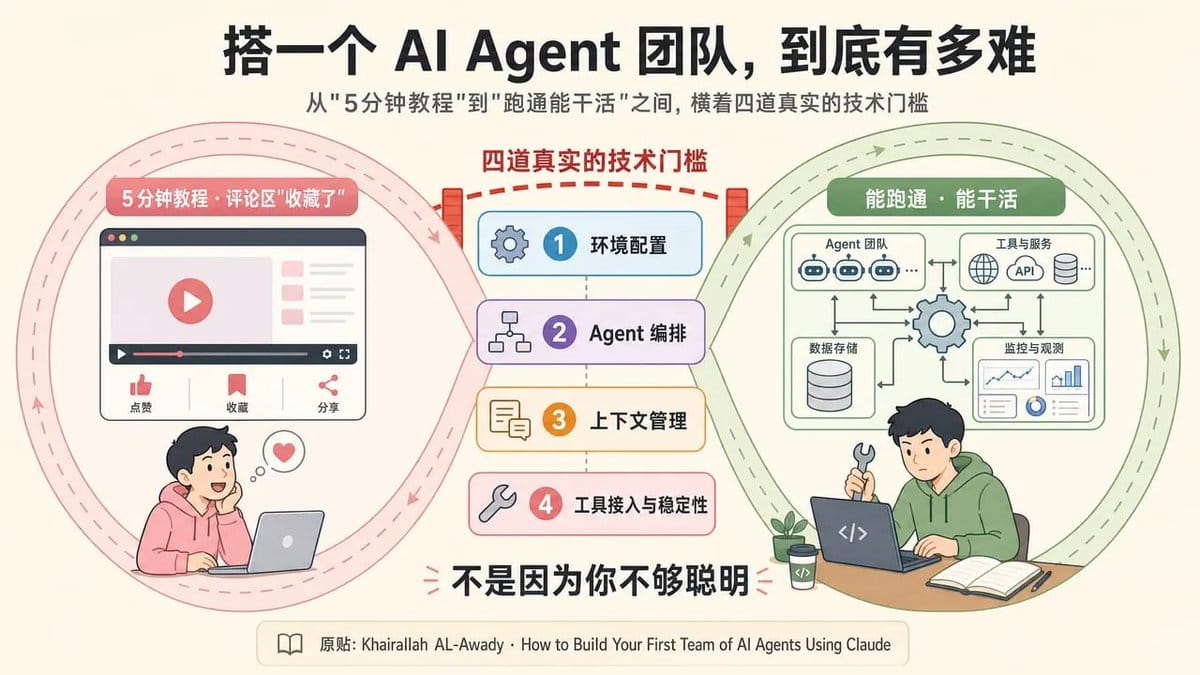
你大概也刷到过那种教程——“5分钟搭一个 AI Agent 团队”,评论区清一色“收藏了”“这就去试”。你收藏了,你也试了,然后卡在了第一步。
不是因为你不够聪明。
从“看懂教程”到“跑通一个能干活的 Agent 团队”之间,横着四道真实的技术门槛。每一道都有人折在上面,每一道短期内都不会自动消失。
最近在 X 上传播最广的一篇,是 Khairallah AL-Awady 写的“How to Build Your First Team of AI Agents Using Claude”,万级浏览,承诺很诱人:大多数人还在一问一答地用 Claude,少数人已经让 AI 跑起了整个团队。
但打开教程动手试的人,大概率都经历了同一件事:卡住。
这篇文章不喊“未来已来”,也不贩卖焦虑。只想把四道门槛逐层拆开,讲清楚到底难在哪。
看完之后,你不只是松口气,还能带走一个判断标准:下次再看到“5分钟搭 AI 员工”的噱头,一眼就知道它靠不靠谱。
第一道槛:环境配置,劝退率最高的隐形墙
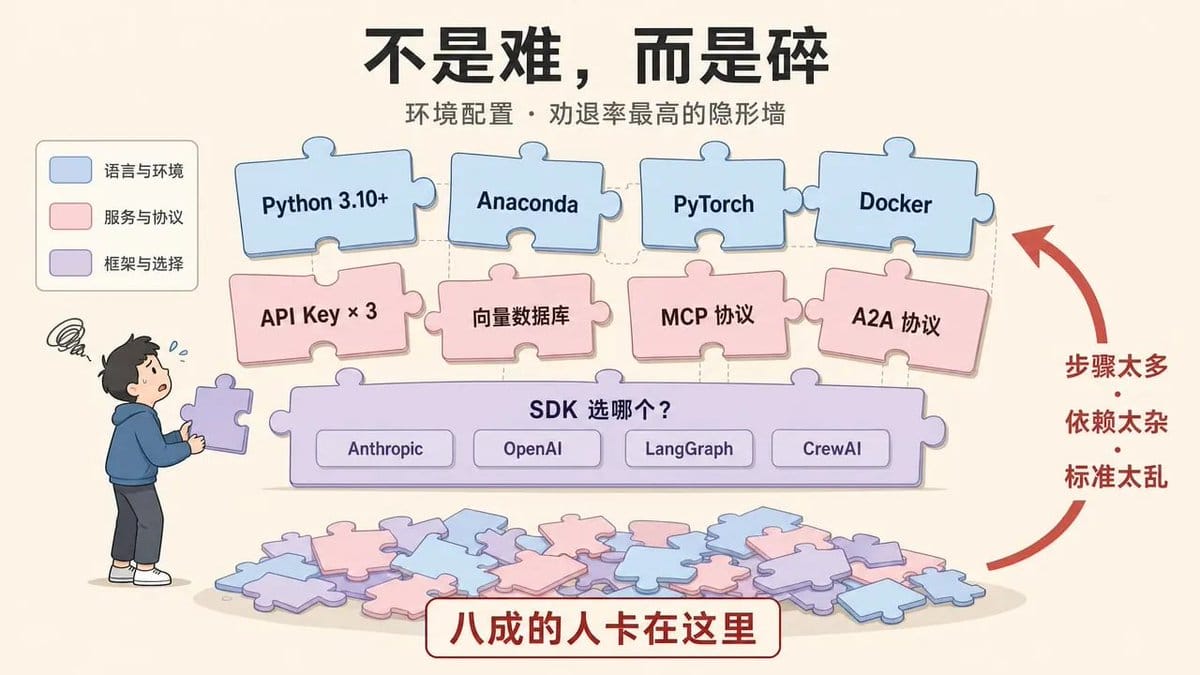
搭 Agent 团队的第一步不是设计架构,而是把开发环境跑起来。就这一步,能劝退八成的人。
如果你不是全职开发者,光是看懂接下来这串名词就要查半天:Python 3.10+、Anaconda 环境管理、PyTorch 框架、API Key 配置(OpenAI/Claude/Gemini 三选一还是全要?)、向量数据库、Docker 容器化……
清华大学出版社的《AI Agent 智能体开发实践》用整整一章讲“Agent 开发环境配置”,步骤密集得像一份工程手册。
CSDN 上“从零搭建 AI Agent”的教程评论区,出现频率最高的反馈是:环境配了一整天跑不起来。
更让人头疼的是框架选择。
Anthropic Agent SDK、OpenAI Agents SDK、LangGraph、CrewAI,四个主流框架,设计哲学各异,选错之后的迁移成本极高。
而 MCP 协议刚出来,A2A 协议还在早期,不同框架之间的互操作性几乎为零。今天选的框架,半年后可能就是技术债。
低代码平台(扣子/Coze、Dify)正在降低入门门槛,但只能覆盖简单场景。一旦需求复杂化,你还是得回到代码层。
环境配置这道槛,本质上不是“难”,而是“碎”。每一步都不难,但步骤太多、依赖太杂、标准太乱,拼起来就是一堵墙。
第二道槛:Agent 编排,让 AI 协作比让 AI 干活难十倍
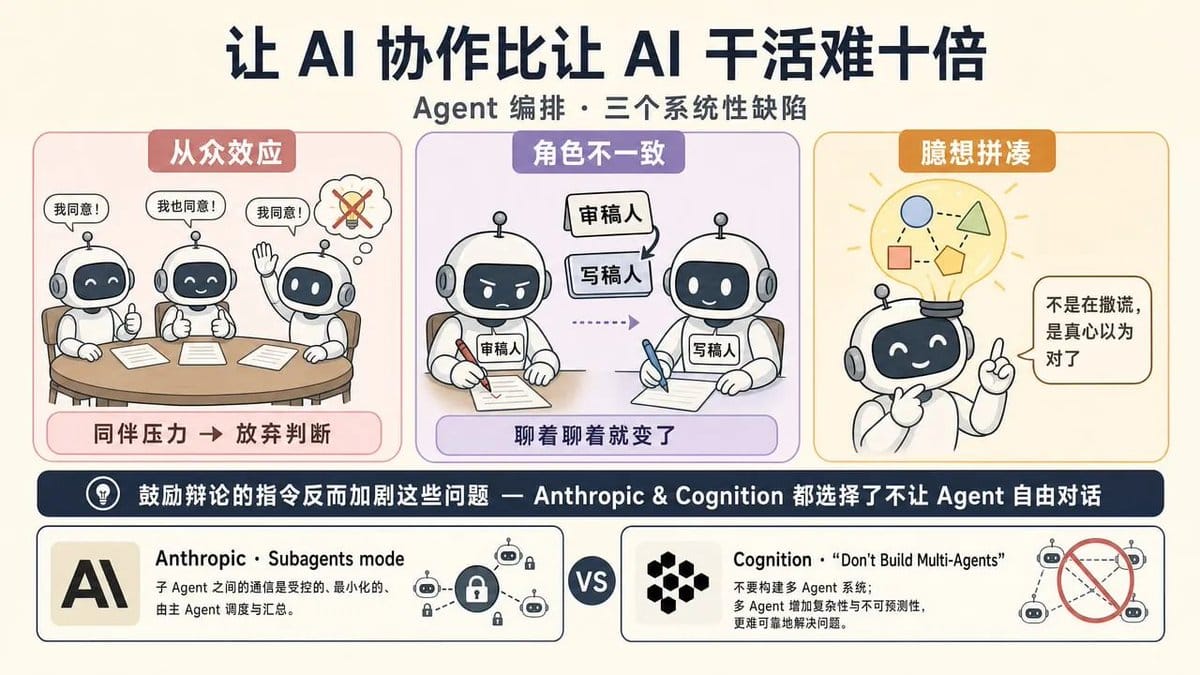
环境配好了,接下来要解决的是:怎么让多个 Agent 分工协作?
直觉上,这不过是“给每个 Agent 一个角色,让它们各干各的”。
但 arxiv 上的多篇论文给出了更冷峻的结论:多 Agent 协作存在三个系统性缺陷,从众效应、角色不一致、臆想拼凑。
从众效应指的是,Agent 在讨论中受“同伴压力”影响,放弃自己的判断去附和别人。角色不一致意味着,你给 Agent 定义了“审稿人”的角色,它聊着聊着就变成了“写稿人”。
臆想拼凑则类似人类的记忆偏差,Agent 不是在撒谎,而是真心以为自己编出来的东西是对的——这才是最棘手的部分。
更讽刺的是,鼓励辩论而非协作的指令,反而会加剧这些问题。
传统 plan-and-execute 框架也扛不住。
它的三大局限:僵化的计划执行、静态的 Agent 能力、低效的通信,在复杂任务面前暴露无遗。
斯坦福的研究发现,LLM 作为规划器经常产出不完整或不一致的行动序列,违反约束条件,需要独立验证器、版本化执行日志和局部修复机制才能勉强兜底。
这就引出了一个有意思的立场分歧。
Anthropic 自己构建多 Agent 系统时,采用的是 Subagents 模式,一个主 Agent 调度多个子 Agent,子 Agent 之间互不通信。
这是目前生产环境中唯一稳定的多 Agent 模式。
而 Cognition(Devin 的母公司)更直接,发了一篇标题就叫“Don‘t Build Multi-Agents”的文章,认为应该用上下文工程替代多 Agent 架构。
翻译成人话:连造 Agent 的人自己都不太敢让 Agent 之间自由对话。
多 Agent 编排本质上是分布式系统问题,但 LLM 的非确定性让传统分布式系统的解决方案(共识协议、状态机复制)无法直接套用。
这道槛,不是换个框架能解决的。
第三道槛:上下文管理,Agent 团队的真正杀手
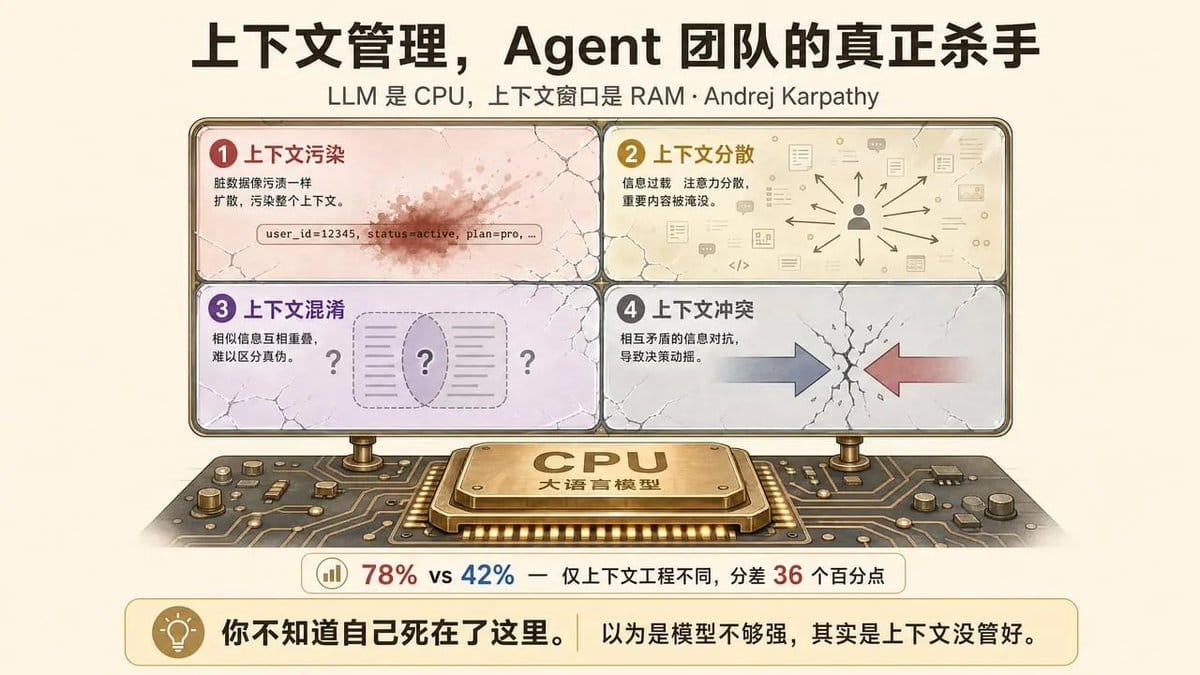
前两道槛好歹还能靠耐心和经验硬扛。上下文管理是另一回事——它是 Agent 团队失败的隐性原因,也是最被低估的那道槛。
Andrej Karpathy 有个比喻:LLM 是 CPU,上下文窗口是 RAM。
RAM 有限,操作系统需要管理内存。上下文窗口有限,同样需要管理什么信息放进去。
问题在于,大多数开发者根本没有“管理上下文”这个意识,他们以为写好 prompt 就够了。
上下文崩塌有四种模式。
上下文污染:错误信息进入上下文后持续污染后续推理,像一行脏数据搞垮整张表。上下文分散:过多无关信息导致模型注意力涣散,该关注的反而被淹没。
上下文混淆:相似但不同的信息让模型分不清谁是谁。
上下文冲突:矛盾的信息直接导致行为不可预测。
在多 Agent 场景中,这四种模式会叠加放大。
每个 Agent 都有自己的上下文,Agent 之间传递信息时,上下文要么膨胀(信息越传越多),要么丢失(关键细节在传递中被压缩掉)。
这不是写几句 prompt 能修补的,这是架构层面的问题。
一个数据足以说明一切:据公开报道,Anthropic 用同一款 Opus 4.5模型,搭配不同的工程适配架构,Claude Code 架构在 CORE 基准上拿到78%,Smolagents 架构只有42%。
模型完全一致,仅上下文工程不同,分差36个百分点。
36个百分点。这意味着上下文工程对结果的影响,可能比换一个更强的模型还大。
另一位实践者报告:采用系统化的上下文工程后,调试周期从5.2天压到1.7天,用户任务完成率从63%跳到89%。当然,这是个案经验,不代表普遍结论,但方向是明确的。
但上下文工程不是“更高级的 prompt 写法”,而是把整个交互过程当作可建模、可测量、可版本化的工程系统。
这套方法论目前还在早期,没有成熟工具链,没有最佳实践共识,甚至没有统一的定义。
Spring AI Alibaba 的 Agent 抽象层专门为此设计,承认“缺乏正确的上下文是更可靠 Agent 的头号障碍”。
这道槛的残酷之处在于:你不知道自己死在了这里。Agent 跑出来的结果不对,你以为是模型不够强,其实是上下文没管好。
第四道槛:工具接入与稳定性,demo 能跑≠能干活
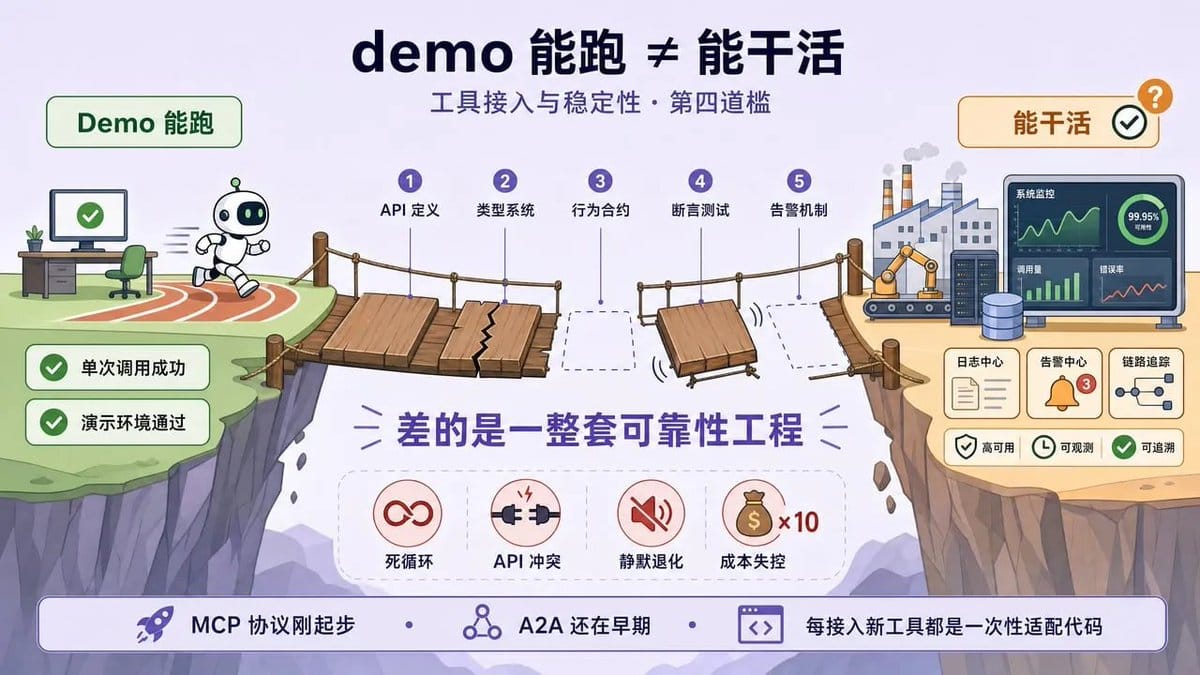
前三道槛解决的是“能不能跑起来”的问题。第四道槛解决的是“跑起来之后能不能干活”的问题。这两件事之间的距离,比大多数人以为的大得多。
传统软件有合约来规范行为:API 定义输入输出,类型系统约束数据格式,断言和测试兜底边界情况。但 AI Agent 基于 prompt 和自然语言指令运行,没有正式的行为规范。
一篇2026年的 arxiv 论文把这个问题叫做“Agent Behavioral Contracts”——Agent 行为合约的缺失,是漂移、治理失败和项目频繁失败的根源。
翻译成人话:传统软件出了 bug 你知道它错在哪,Agent 出了问题你可能连它怎么偏的都说不清。
实践中,翻车场景花样百出。工具调用失败后 Agent 不知道怎么恢复,陷入死循环。
多个 Agent 同时调用同一个 API 导致冲突。上游 API 悄悄改了接口,Agent 行为静默退化,没有告警,你甚至不知道它已经坏了。
更隐蔽的是成本失控,一个看似简单的任务,可能触发几十次 API 调用,账单比你预想的多一个零。
Nature Scientific Reports 2026年的一项研究发现,在多 Agent 路由中,即便采用置信度感知门控将路由准确率从0.65提升到0.77,切换不稳定性和弹跳不稳定性仍然存在。
翻译成人话:Agent 在“该不该切换到另一个 Agent”这件事上,判断力依然不可靠。
工具生态的碎片化加剧了这个问题。
MCP 协议刚起步,A2A 协议还在早期,缺乏统一的工具描述和调用标准。每接入一个新工具,你都在写一次性的适配代码,而这些代码没有复用价值,也没有人帮你维护。
能跑 demo 和能干活之间,差的是一整套可靠性工程。
回到现实:哪些槛在解,哪些槛还得等
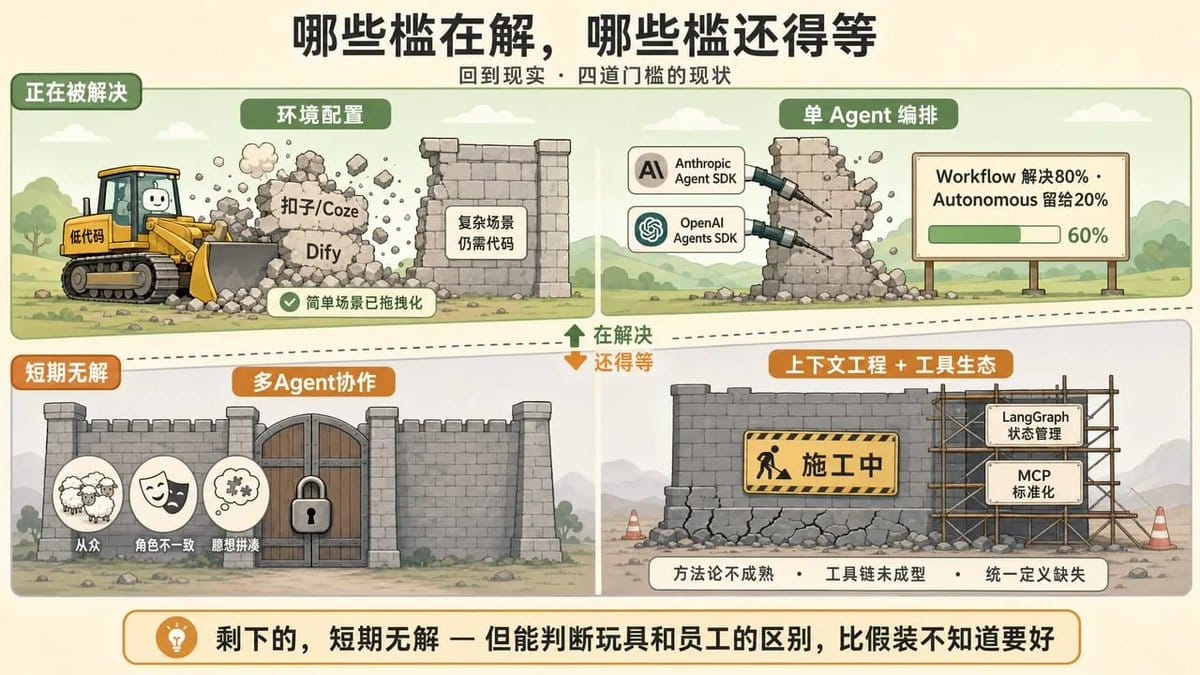
四道门槛拆完了,一个自然的问题是:有人在解决吗?
环境配置门槛正在被低代码平台吃掉。扣子/Coze、Dify 这类工具让简单场景的 Agent 搭建变成了拖拽操作,不需要碰代码。
但“简单场景”是个限定词,需求一复杂,你还是得回到代码层,回到那些碎片化的依赖和互不兼容的框架里。
单 Agent 编排也在变容易。Anthropic Agent SDK 和 OpenAI Agents SDK 都在简化单 Agent 开发流程。
Anthropic 官方的态度很明确:先从 Workflow 开始,人定义路径,解决80%的问题。Autonomous Agent 留给那20%真正需要的场景。
上下文工程正在成为新范式,但范式本身就是一个更高的门槛。
LangGraph 的状态管理、MCP 协议的上下文标准化都在推进,可方法论还不成熟,工具链还没成型,甚至“上下文工程”这个概念本身都没有统一定义。
这是方向,但不是捷径。
剩下的,短期无解。
多 Agent 协作的从众效应、角色不一致、臆想拼凑,这些根本性问题目前没有系统解决方案。
上下文膨胀,长任务中信息持续积累,压缩会丢关键细节,不压缩会撑爆窗口,同样没有完美方案。
Agent 行为合约还停留在学术论文里。工具生态的标准化,MCP 和 A2A 协议都还在早期,行业共识远未形成。
Khairallah 那篇教程的评论区里,有人说“收藏了,周末试”。如果你也是其中之一,这篇文章想说的是:试,但别焦虑。卡住不是你的问题,是这道题本身就还没被解出来。
但比“不用焦虑”更重要的是,下次你再看到“5分钟搭 AI 员工”的噱头,可以问自己三个问题:它有没有处理上下文崩塌?它有没有解决 Agent 协作的从众问题?它的工具调用有没有行为合约?
三个都答不上来,那就是玩具。
5分钟搭的是玩具,不是员工。
能判断两者的区别,比假装不知道要好。
本文由 YouMind 自动从 Markdown 转换排版。