本文经原作者授权转载,版权归原作者所有。原作者:Echo ./(@0xEcho99)。
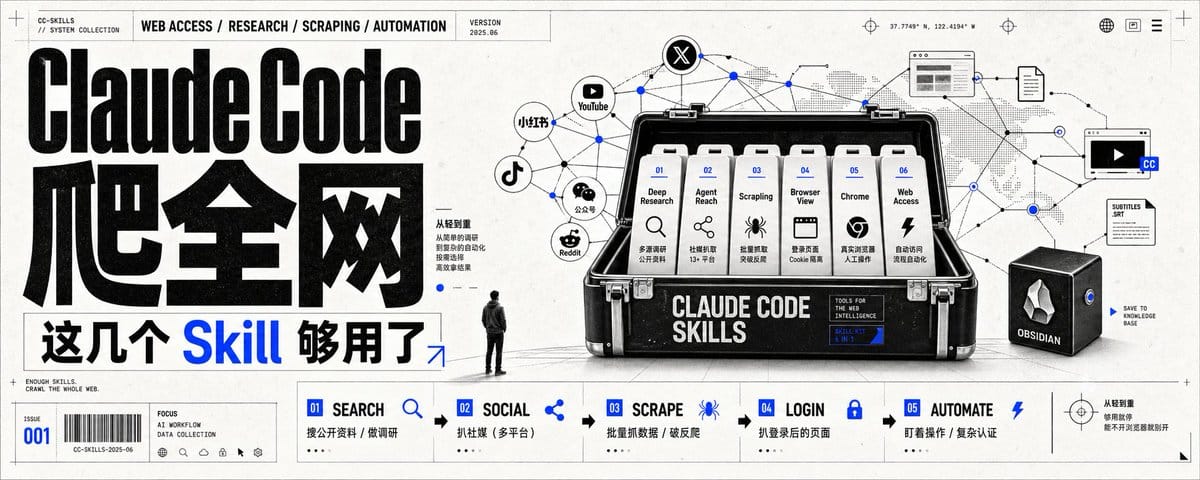
Claude Code 配上这几个 Skill,基本能爬全网了。
◉ 扒社媒(小红书 / X / 抖音 / YouTube / 公众号 / Reddit)
→ Agent-reach。一个开源的 AI 脚手架,支持 小红书 / X / 抖音 / YouTube / 公众号 / Reddit 等多个平台通过 API 访问。通过安装 CLI 工具、配置搜索引擎等方式,帮助 AI Agent 实现对各种平台的访问。
项目地址:github.com/Panniantong/agent-reach
◉ 批量抓数据 / 破反爬
→ Scrapling。一个开源的自适应网页抓取框架,支持从单次请求到全量爬取。通过内置静态、JS 渲染、反爬隐身三种抓取器,帮助 AI Agent 高速提取结构化数据、绕过 Cloudflare 等反爬,且网页改版后能自动重新定位元素、不易失效。
项目地址:github.com/D4Vinci/Scrapling
◉ 扒登录后的页面 / 让 AI 自己操作
→ Browser-use。一个开源的浏览器自动化框架,让 AI 像人一样操作网页。由 LLM 驱动(需配置一个模型),帮助 AI Agent 自主完成填表、点击、操作后台等多步任务,并能复用你 Chrome 里已登录的状态。
项目地址:github.com/browser-use/browser-use
◉ 要盯着它操作 / 复杂认证的页面
→ Claude in Chrome。Anthropic 官方的浏览器扩展。通过把 Claude 装进你真实的 Chrome,帮助你亲眼看着它在页面里点击、填写、操作,适合需要盯着、或认证特别复杂的页面。
官网:claude.ai/chrome
◉ 要全自动联网 / 接管日常 Chrome
→ Web-access。一个开源的 Agent 联网 Skill,覆盖从公开搜索到登录后操作的全场景。通过在 WebSearch / WebFetch / curl / CDP 之间自动择优、并用 CDP 接管你日常的 Chrome(天然带登录态),帮助 AI Agent 完成各种联网任务,还能检索本地浏览器的书签与历史。
项目地址:github.com/eze-is/web-access
核心是从轻到重,够用就停,能不开浏览器就别开。
前几天用这套扒一个课程网站,后台全流程把文档和视频扒下来、自动翻译加字幕、存进 Obsidian,非常丝滑。
直接把这篇文章扔给你的 Agent 去下载并根据从轻到重,够用就停,能不开浏览器就别开的原则配置即可食用。