
本文经原作者授权转载,版权归原作者所有。原作者:Berryxia.AI(@berryxia)。
这是一份面向普通读者、创作者和初学开发者的科普教程。它不假设你已经懂 Three.js、实时语音或 AI Agent,而是从一个朴素问题开始:
如果一座盛唐长安城不是只能观看,而是可以走进去、和李白对诗、和导游问路、在 AI 展馆里听智能讲解,会是什么体验?
我们用两周左右的高强度开发,把这个想法做成了一个可在线访问、可开源复用的 Web 3D 互动项目。
项目地址:
- 在线体验:https://andyhuo520.github.io/tang-changan/
- GitHub:https://github.com/andyhuo520/tang-changan

上图是我们为语音 NPC 面板,使用GPT-image-2 模型生成的素材,准备的一组角色视觉素材。项目里每个核心角色都可以拥有自己的头像、视频开场和待机状态,让“和 NPC 说话”更像在游戏里见到一个具体的人。
1. 最初的设计目标
一开始,我们并不是想做一个普通的“3D 展示页”。我们的目标更像一个小型数字文旅实验:

- 它要像游戏一样能玩。 玩家可以进入场景,用 WASD 操控角色,而不是只能转动相机看模型。
- 它要像博物馆一样能逛。 场景里有宫殿、朱雀大街、珍宝馆、诗画展厅、AI 展馆。
- 它要像真实导览一样能说话。 玩家不是点几个固定按钮,而是能按住麦克风和 NPC 语音交流。
- 它要有盛唐气质。 色彩、建筑、人物、诗词、小游戏都围绕“长安”“诗酒”“万邦来朝”展开。
- 它要能开源。 最终要能部署到 GitHub Pages,让别人直接体验,也能阅读代码学习。
用一句话概括:
我们想把“盛唐长安”做成一个可漫游、可对话、可游戏、可展示 AI 能力的浏览器 3D 世界。
2. 第一阶段:先搭出一个能看的长安沙盘
任何复杂互动项目,第一步都不是做功能,而是先让“世界存在”。
我们先用 Web 3D 技术搭建了一个低多边形风格的长安微缩沙盘。核心技术是 Three.js:它可以在浏览器中渲染 3D 场景,不需要用户安装客户端。
这一阶段的重点是:
- 建立主场景、相机、灯光、后期效果;
- 搭建朱雀大街、宫殿、城门、市集、塔楼、河道等地标;
- 用低多边形材质保持性能,让普通浏览器也能跑;
- 加入昼夜、季节、天气、雾效等氛围变化;
- 做出俯瞰视角,让它第一眼像一张“会动的唐代城市地图”。
这一阶段看起来像“美术搭建”,但其实它决定了后续所有玩法的边界:哪里能走、哪里能互动、哪些地标能承载剧情。
3. 第二阶段:把展示页变成可玩的游戏
只有沙盘还不够。我们希望玩家不是“看长安”,而是“走进长安”。
于是项目进入第二阶段:加入 WASD 游戏模式。
玩家点击「走进长安」后,会进入角色选择:
- 世子
- 商贾
- 侍女
- 游侠
每个角色有自己的头像、默认名字、初始钱包和物品。进入游戏后,玩家可以:
- 用 WASD 移动;
- 用鼠标调整视角;
- 靠近 NPC 按 E 对话;
- 靠近店铺或展馆按 F 触发互动;
- 查看钱包、体力、行囊、任务提示。
这一阶段真正完成了从“3D 页面”到“小游戏”的转变。
4. 第三阶段:让 NPC 不只是摆设
很多 3D 场景的问题是:建筑很漂亮,但里面没有生活。
所以我们给城市加了大量 NPC 和小游戏,让它变得有烟火气。
4.1 NPC 互动
玩家靠近路人、文士、商贾、仕女、官员、僧人等 NPC,可以触发对话。不同 NPC 会有不同身份和口吻。
4.2 诗词小游戏
我们设计了偏唐风的互动玩法:
- 飞花令:给出一个关键字,玩家从诗句中选择含有该字的一句;
- 对对联:给出上联,从多个候选句里选下联;
- 猜谜:用民俗谜语和长安史实做选择题;
- 猜拳:快速轻量的小互动,配合随机奖励。
小游戏不是单纯为了“好玩”,而是让诗词和历史知识变成可参与的体验。
5. 第四阶段:做珍宝馆与诗画展厅
为了让项目更像数字文旅产品,我们加入了展厅系统。
玩家可以进入不同展馆,欣赏诗画、珍宝和历史主题内容。例如:
- 《步辇图》
- 《历代帝王图》
- 《簪花仕女图》
- 诗词与书画主题展
- 丹青馆 DIY 展厅
展厅的作用是把“游戏”与“文化内容”连接起来:玩家既可以玩,也可以看展、听讲解、理解背后的历史语境。
6. 第五阶段:加入 AI 展馆
项目最特别的一部分,是我们把现代 AI 品牌做成了唐风展馆。
我们设计了一个“天枢府 / AI 展馆”概念:在盛唐长安里出现一个古今穿越的科技坊市。不同 AI 品牌不再只是 logo,而是变成一座座唐风殿宇,每个展馆都有自己的讲席和风格。
其中 Agora 馆作为核心语音互动展馆,承担了实时语音能力展示。
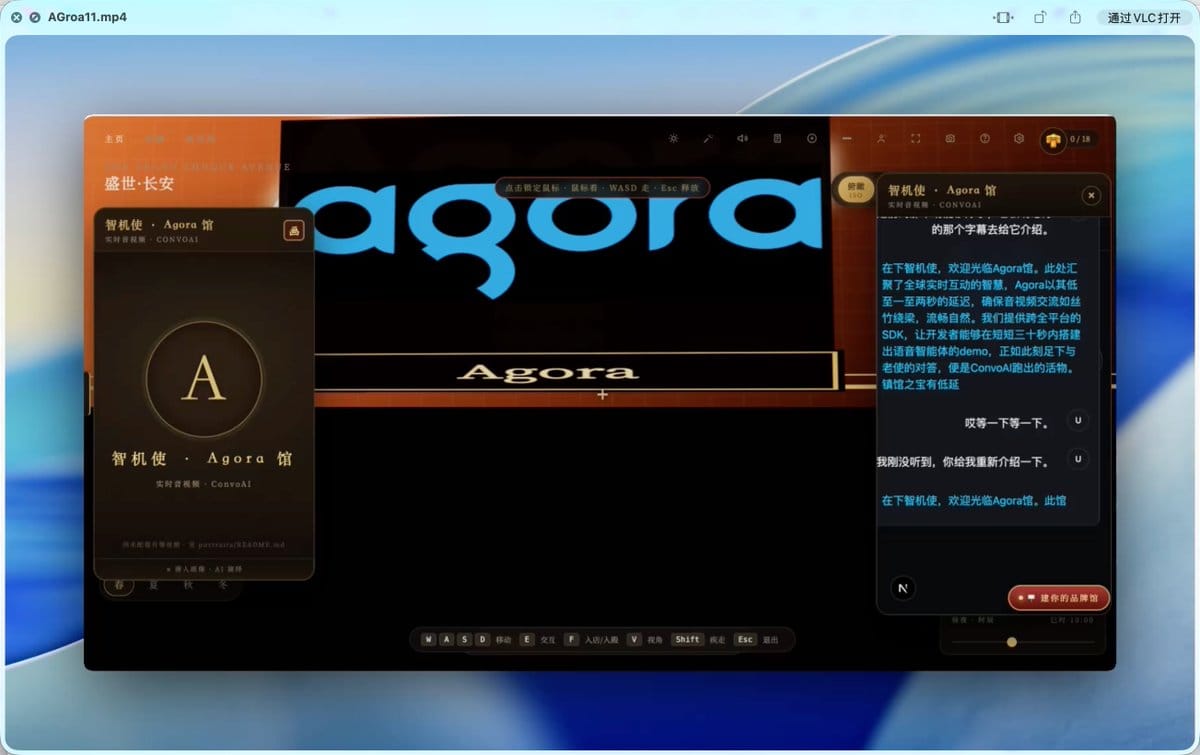
在游戏场景中,Agora 不只是一个外部服务名,而是被设计成一座可进入、可互动、可召唤智机使讲解的“Agora 馆”。这能帮助非技术用户理解:语音 AI 不只是后台 API,它可以成为一个场景化体验。
在视觉上,我们做了:
- 唐风殿宇;
- 品牌 logo 立柱;
- 发光牌匾;
- 展馆说明牌;
- 可交互门口热点;
- 现代科技与古代街景混合的小彩蛋。
在叙事上,我们把它包装成:
大唐长安出现了一座“智机府”,各路 AI 智机使在这里讲解不同的智能能力。
这样做的好处是:AI 展示不再像一个冷冰冰的产品页面,而是变成了玩家在游戏世界里能探索的一部分。
7. 第六阶段:接入实时语音 Agent
这是整个项目最核心、也最难调的一部分。
我们的目标不是让 NPC 弹出文字框,而是让玩家真的能用语音和角色交流。
7.0 开发前置:安装 Agora Skills / Agora CLI
在这个项目里,Agora 语音能力并不是直接把 App ID 写死在网页里,而是通过 Agora Skills + Agora CLI 完成项目登录、能力检查、环境变量写入和 ConvoAI 就绪检查。
你可以把它理解成:
Agora Skills 负责告诉 Agent 怎么集成 Agora;Agora CLI 负责登录账号、绑定项目、写入 .env.local。
更具体地说,这里有两层:
层级作用谁来使用Agora Skills给 AI Coding Agent 的集成说明书,告诉 Agent 应该用官方 quickstart、怎么检查 ConvoAI、怎么处理 token 和环境变量Cursor / Claude / AgentAgora CLI真正执行登录、项目选择、能力检查、环境变量写入的命令行工具开发者和 Agent 都会用。
所以,“安装 Agora Skills”在实际复现时,通常会落到两件事:
- 确保你的 AI 开发环境已经有 Agora Skill / Agora 参考资料;
- 在本机安装并登录 agora CLI,让项目可以拿到有效的 Agora 项目配置。
第一步:确认是否已有 Agora Skill / Agora CLI
如果本机还没有 agora 命令,可以安装:
curl -fsSL https://raw.githubusercontent.com/AgoraIO/cli/main/install.sh | sh安装完成后,重新打开终端,确认命令存在:
which agora
agora version如果能输出路径和版本号,说明 CLI 已经进入你的 PATH。
安装后检查:
agora doctor如果终端能看到 Agora CLI install is healthy,说明 CLI 本身可用。
如果 agora 命令不存在,通常是 shell 没有加载新的 PATH。可以重开终端,或检查安装脚本输出里提示的 PATH 配置。
第二步:登录 Agora 账号
agora login
命令会打开浏览器完成授权。正常流程一般是:
- 终端打印一个 https://sso2.agora.io/... 登录链接;
- 浏览器打开 Agora SSO 页面;
- 登录并授权 Agora CLI;
- 浏览器回调本机 localhost;
- 终端显示 Session stored 和 Status: authenticated。
登录后检查状态:
agora auth status你希望看到类似:
Status : authenticated
Scope : basic_info,console
Expires At : ...如果这里显示未登录,重新执行 agora login。
如果登录成功但后面 agora project list 返回:
ACCOUNT_BLOCKED
说明不是代码问题,而是 Agora 账号或控制台权限被限制。此时需要换一个可用账号,或先解除账号限制。
第三步:选择或创建 Agora 项目
登录后先列出项目:
agora project list
如果你已经有项目,可以选择它:
agora project use <project-id-or-name>
如果还没有项目,可以通过 Agora Console 创建,或用 CLI 初始化 quickstart 项目:
agora init voice-agent-demo --template nextjs这个命令会做三件事:
- 创建或绑定一个 Agora 项目;
- 克隆官方 quickstart;
- 写入本地 .env.local。
本项目是从 official quickstart 的思路继续改造的:先确保官方 demo 能跑,再把它嵌入到《大唐长安》的 3D 场景中。
第四步:检查项目是否支持 ConvoAI
实时语音 Agent 依赖 Agora 的 Conversational AI 能力。可以运行:
agora project doctor --feature convoai如果提示没有启用,可以尝试:
agora project feature enable convoai然后再次运行 doctor 确认。
你希望看到的结果是 project doctor 没有 blocking issue。它不等于“语音一定已经通了”,但至少说明控制台项目配置层面准备好了。
第五步:把 Agora 项目凭据写入语音后端
本项目的语音后端读取:
tang-voice-agent/server/.env.local其中最关键的是:
AGORA_APP_ID=...
AGORA_APP_CERTIFICATE=...可以让 Agora CLI 自动写入:
cd tang-voice-agent/server
agora project env write .env.local --overwrite注意:AGORA_APP_CERTIFICATE 是敏感信息,不要提交到 GitHub。项目的 .gitignore 已经忽略 .env.local。
写入后可以检查文件是否存在,但不要把证书贴到公开地方:
ls -la .env.local
grep AGORA_APP_ID .env.local如果只是自查证书是否存在,可以看键名,不要打印完整值:
sed -E 's/=.*/=***/' .env.local第六步:启动语音服务
后端:
cd tang-voice-agent/server
source venv/bin/activate
python3 src/server.py前端 iframe:
cd tang-voice-agent/web
AGENT_BACKEND_URL=http://localhost:8000 bun run dev主游戏默认会把语音面板指向:
http://localhost:3000
如果线上部署语音服务,可以通过 URL 参数指定:
?voiceOrigin=https://你的语音前端域名
第七步:验证语音链路
先验证后端能返回 Agora 配置:
curl http://localhost:8000/get_config再验证能启动一个 agent:
curl -X POST http://localhost:8000/v2/startAgent \
-H "Content-Type: application/json" \
-d '{"channelName":"diag-001","rtcUid":111,"userUid":222,"personaId":"brand_agora"}'如果返回 agent_id,说明后端成功请求 Agora 创建了一个语音 Agent。
最后打开游戏,进入 Agora 馆,点击右侧语音面板,观察三件事:
- 面板不再一直停在“召唤中”;
- 麦克风能采集声音;
- AI 有返回语音和字幕。
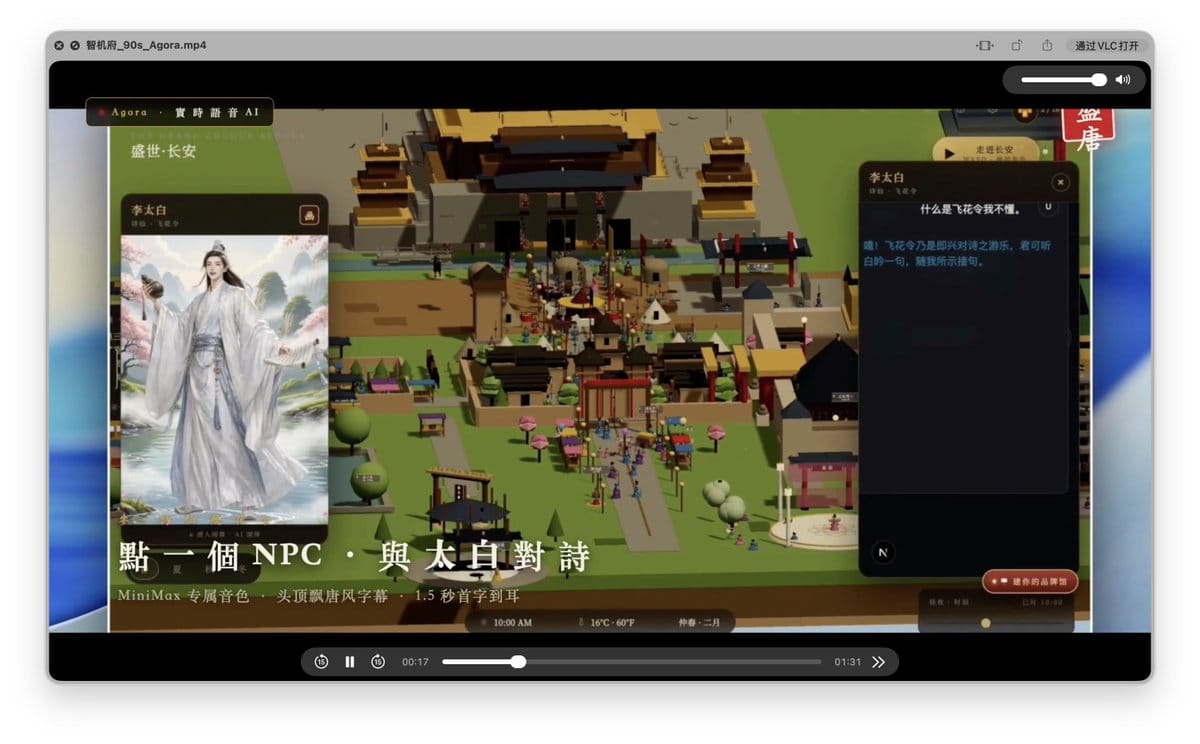
语音功能最终不是孤立存在的,它会和玩家身份、NPC、展馆、字幕、头像面板一起工作。玩家看见的是“角色在长安城里与智机使对话”,背后才是 RTC、ConvoAI 和 Agent 编排。
常见错误与排查
如果看到:
CAN_NOT_GET_GATEWAY_SERVER: no active status
401 Invalid token通常不是前端按钮坏了,而是 Agora 项目或凭据不可用。优先检查:
- agora auth status 是否已登录;
- agora project list 是否能正常列出项目;
- 当前账号是否被限制或 blocked;
- agora project doctor --feature convoai 是否通过;
- .env.local 里的 App ID / Certificate 是否来自同一个项目;
- 修改 .env.local 后是否重启了后端。
可以按这个顺序排查:
agora auth status
agora project list
agora project doctor --feature convoai
cd tang-voice-agent/server
sed -E 's/=.*/=***/' .env.local如果 CLI 登录正常,但 project list 返回 ACCOUNT_BLOCKED,说明账号侧被限制,代码无法绕过。需要换可用账号或解除 Agora 控制台限制。
7.1 基本架构
项目被拆成两部分:
- han-diorama 浏览器 3D 主场景 负责 Three.js、WASD、NPC、展馆、小游戏
- tang-voice-agent
- 语音智能体子项目
- 前端是 Next.js iframe
- 后端是 FastAPI / Python
- 负责 Agora ConvoAI、Persona、语音对话
主场景里点击 NPC 后,会打开右侧语音面板。这个面板本质上是一个嵌入的 iframe,它和主游戏通过 postMessage 通信。
7.2 一次语音对话发生了什么
当玩家按住麦克风说话时,大致流程是:
玩家麦克风 ↓ 浏览器 RTC 上行 ↓ Agora 实时音频链路 ↓ ConvoAI:语音识别 → 大模型思考 → TTS 合成 ↓ AI 声音通过 RTC 回到浏览器 ↓ 游戏里 NPC 头像、字幕、状态同步变化
普通用户看到的是“我和李白说话了”。技术上背后是实时音频、语音识别、大模型、语音合成和游戏状态同步一起工作。
7.3 为什么要做 Persona
如果所有 NPC 都用同一个提示词,它们就会像同一个机器人。
所以我们给不同角色做了不同 Persona:
- 李白:诗酒豪放;
- 杜甫:沉郁关怀;
- 王维:山水空灵;
- 周引之:导游身份,可以带路;
- 苏阮卿:画学博士,负责讲画;
- 智机使 · Agora 馆:讲解实时语音与 ConvoAI。
每个 persona 有自己的:
- 名字;
- 身份;
- 场景位置;
- 说话风格;
- TTS 音色;
- 可注入的场景上下文。
这让语音功能不只是“能说话”,而是和游戏世界绑定在一起。
8. 第七阶段:做角色头像、视频面板与 BGM
为了让语音互动更有“面对面”的感觉,我们做了左侧角色 portrait 面板。
它支持:
- idle.jpg / idle.png 静态头像;
- idle.mp4 静音循环视频;
- intro.mp4 带原声开场视频;
- AI 说话时切换 talking 状态;
- 没有素材时自动 fallback。
后来又加入了古风 BGM:
- 默认循环播放古琴 / 古筝曲;
- 支持静音、音量、切歌;
- 当玩家打开语音对话时,BGM 自动降低音量,避免盖住人声。
这一步看似是“包装”,但对用户体感影响很大。没有声音和头像时,AI 对话像工具;有了角色视频、字幕和背景音乐后,它更像游戏里的角色。
9. 第八阶段:解决视觉与尺度问题
开发中遇到过一个典型问题:AI 展馆一开始太大,放到城市里会出现“浮在地面上”“镜头一转消失”的情况。
问题根源是单位尺度不一致:
- 主城使用的是游戏世界单位;
- AI 展馆早期按更大的现实尺度设计;
- 结果展馆实际超出了主城地面范围。
解决方式是:
- 把天枢府缩放到适合主城的面积;
- 重新设置展馆中心点;
- 调整 3×3 展馆布局;
- 缩小 logo 立柱、牌坊、院墙和展馆模型;
- 确认所有互动点都落在可见地面内。
这个经验很重要:3D 项目里,美术好看不够,尺度一致才是可玩的前提。
10. 第九阶段:部署到 GitHub
项目完成后,我们把前端开源部署到了 GitHub。
前端 han-diorama 是静态 Web 项目,适合用 GitHub Pages 托管。
部署流程:
git init
git add -A
git commit -m "Initial commit"
git remote add origin https://github.com/andyhuo520/tang-changan.git
git push -u origin main然后使用 GitHub Actions 自动发布 Pages。
线上地址:
https://andyhuo520.github.io/tang-changan/
需要注意的是:
- GitHub Pages 只能托管静态前端;
- 实时语音后端 tang-voice-agent 需要单独部署;
- 本地开发时可以用 http://localhost:3000 作为语音 iframe;
- 线上如果要启用语音,需要给游戏传入可访问的语音前端地址。
11. 普通用户怎么体验
打开:
https://andyhuo520.github.io/tang-changan/
进入页面后可以:
- 在沙盘视角浏览盛唐长安;
- 点击「走进长安」;
- 选择角色:世子 / 商贾 / 侍女 / 游侠;
- 用 WASD 移动角色;
- 靠近 NPC 按 E 对话;
- 靠近展馆或店铺按 F 互动;
- 进入珍宝馆看诗画;
- 进入 AI 展馆体验语音智能体。
常用按键:
按键作用WASD移动鼠标调整视角E与 NPC 对话 / 触发小游戏F进入展馆 / 开店 / 触发场景Esc关闭语音面板
12. 开发者如何理解项目结构
项目可以分成几层:

最核心的思想是:
3D 主项目负责“玩家在哪里、看见什么、能做什么”;语音子项目负责“玩家说什么、AI 怎么回答、声音怎么回来”。
13. 这次开发踩过的坑
13.1 浏览器缓存
浏览器会缓存 JS 和图片。我们在模块路径后面加版本参数:
scene.js?v=20260529-agora-only
这样每次重要更新后,线上用户能加载到新代码。
13.2 视频自动播放限制
浏览器通常不允许带声音的视频自动播放。解决方式:
- 先尝试播放 intro.mp4;
- 如果被浏览器拦截,就退回静音播放;
- 在用户点击页面后再解锁音频。
13.3 语音项目账号状态
实时语音不只是代码问题,还依赖 Agora 账号、项目状态、ConvoAI 开通状态和 token 鉴权。
如果出现:
CAN_NOT_GET_GATEWAY_SERVER: no active status
401 Invalid token通常说明:
- Agora 账号或项目被阻断;
- App ID / Certificate 不匹配;
- 项目没有开通对应能力;
- 本地 .env.local 还是旧凭据。
这是开发 AI 语音项目时最容易误判的地方:页面看起来是“麦克风开了”,但其实浏览器和 Agent 都没有真正加入频道。
13.4 3D 尺度
展馆、城市、NPC、地面如果不在同一尺度体系里,就会出现漂浮、穿模、消失、点不到的问题。
解决办法不是不断调相机,而是回到世界坐标,统一单位、位置和可交互范围。
14. 如果你想复刻一个类似项目
可以按这个顺序做:
- 确定主题 先选一个世界观,例如唐代长安、宋代汴梁、敦煌石窟、未来博物馆。
- 搭建一个能看的 3D 场景 不要一开始就做大地图。先做一个核心区域,保证 30 秒内能看懂。
- 加入一个可控角色 WASD + 简单碰撞 + 一个 NPC,就足够验证“游戏感”。
- 设计 3 个互动点 一个 NPC、一个展馆、一个小游戏。不要一开始做 20 个。
- 接入语音 Agent 先用一个默认 persona 跑通,再扩展多个角色。
- 把内容模块化 品牌数据、NPC 数据、展馆数据都写成配置,不要散落在代码里。
- 部署上线 前端用 GitHub Pages / Vercel,后端用可公网访问的服务器。
- 最后再做包装 BGM、头像、视频、封面图、教程、X 推文、GitHub README 都属于传播层。
15. 我们最终做成了什么
最终,这个项目不只是一个 3D 页面,也不只是一个语音 demo。
它更像一个小型样板:
- 文旅内容如何游戏化;
- 历史知识如何互动化;
- AI 能力如何场景化;
- 语音 Agent 如何融入 3D 世界;
- 开源项目如何从 demo 变成可分享作品。
如果要用一句话总结整个开发过程:
我们不是把 AI 放到一个按钮里,而是把 AI 放进了一座城。
这就是《大唐长安 · 智机府》的核心。