
本文经原作者授权转载,版权归原作者所有。原作者:阿西_出海(@axichuhai)。查看原文 →
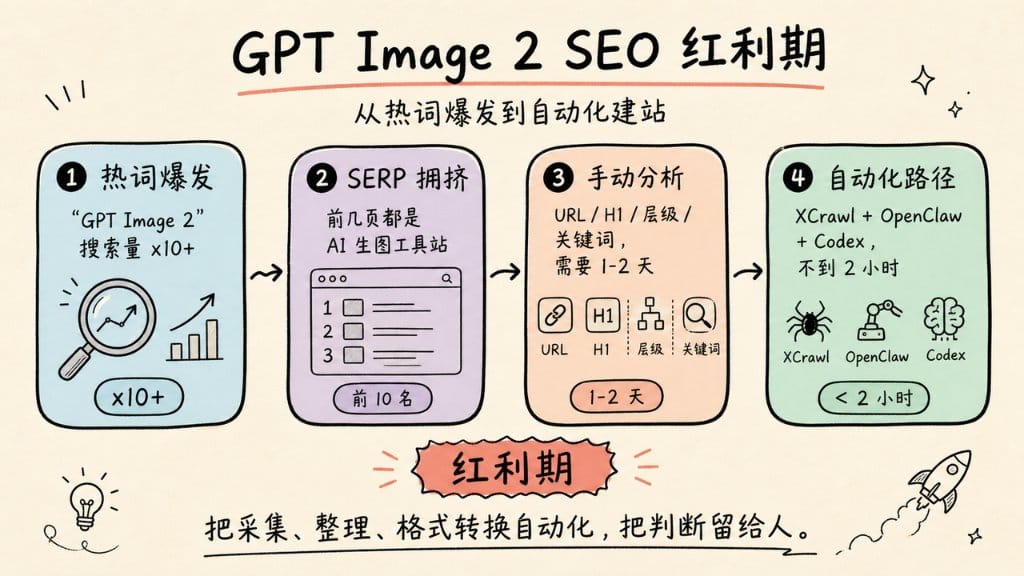
上个月 GPT Image 2 一出来,这个词的搜索量直接炸了。我用 Google Trends 看了一眼,搜索量直接翻了 10 多倍。
然后我去 Google 搜了一下这个词,前几页全是各种 AI 生图工具站,有大厂的,有独立开发者做的,也有明显是用模板两天搭出来的。
我当时第一个念头:这个词现在还在红利期,能不能快速摸清这些站的 SEO 打法,然后搭一个自己的版本出来?
手动分析的话,光打开对标网站一个个看,记录 URL 结构、H1 写法、页面层级、关键词分布……最少也要1-2天。更别说还要整理成可以喂给 AI 的格式。
最近我发现了一个网页采集工具叫 XCrawl,具备搜索引擎结果采集和全站 URL 扫描的功能,能把页面内容以 Markdown、JSON 这些格式吐出来。
我用 XCrawl + OpenClaw + Codex 跑通了"搜索竞品 → 分析架构 → 抓取内容 → 生成站点"的完整工作流,总共花了不到 2 个小时。
下面是完整过程:
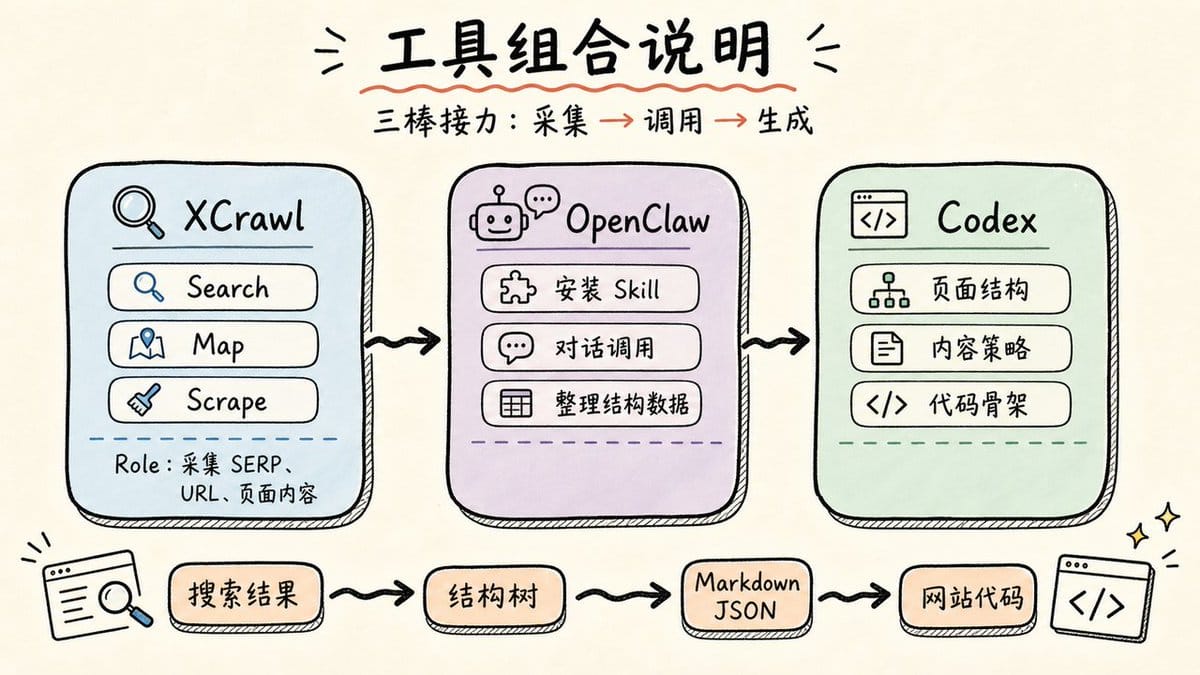
工具组合
先说清楚我用了什么,以及各自的角色:
- XCrawl:数据采集引擎。这次用到了它三个内置skill: Search:输入关键词,返回搜索引擎结果,支持多个主流搜索引擎 Map:输入一个域名,返回该站所有可发现的 URL 列表 Scrape:输入任意 URL,返回页面内容,输出格式可选 Markdown、HTML、截图、摘要、链接列表等
- OpenClaw:通过 Agent 能力安装 XCrawl Skill,在对话里直接调用采集功能,拿到结果后整理分析
- Claude / Codex:最后一棒,把采集到的结构数据转化成可用的代码骨架
前置准备
正式开始之前,先把 XCrawl 接入 OpenClaw,整个过程三步:
1、去 XCrawl 官网找到 OpenClaw 的对接说明文档
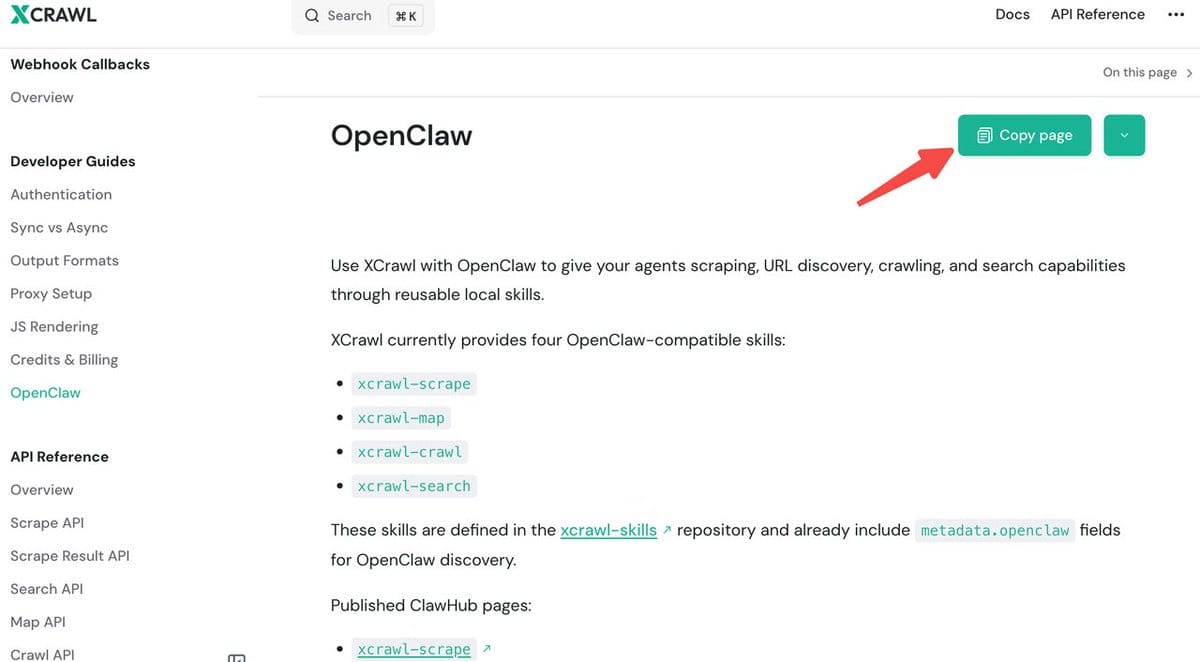
2、把这个文档内容copy提供给 OpenClaw,让它自动完成安装

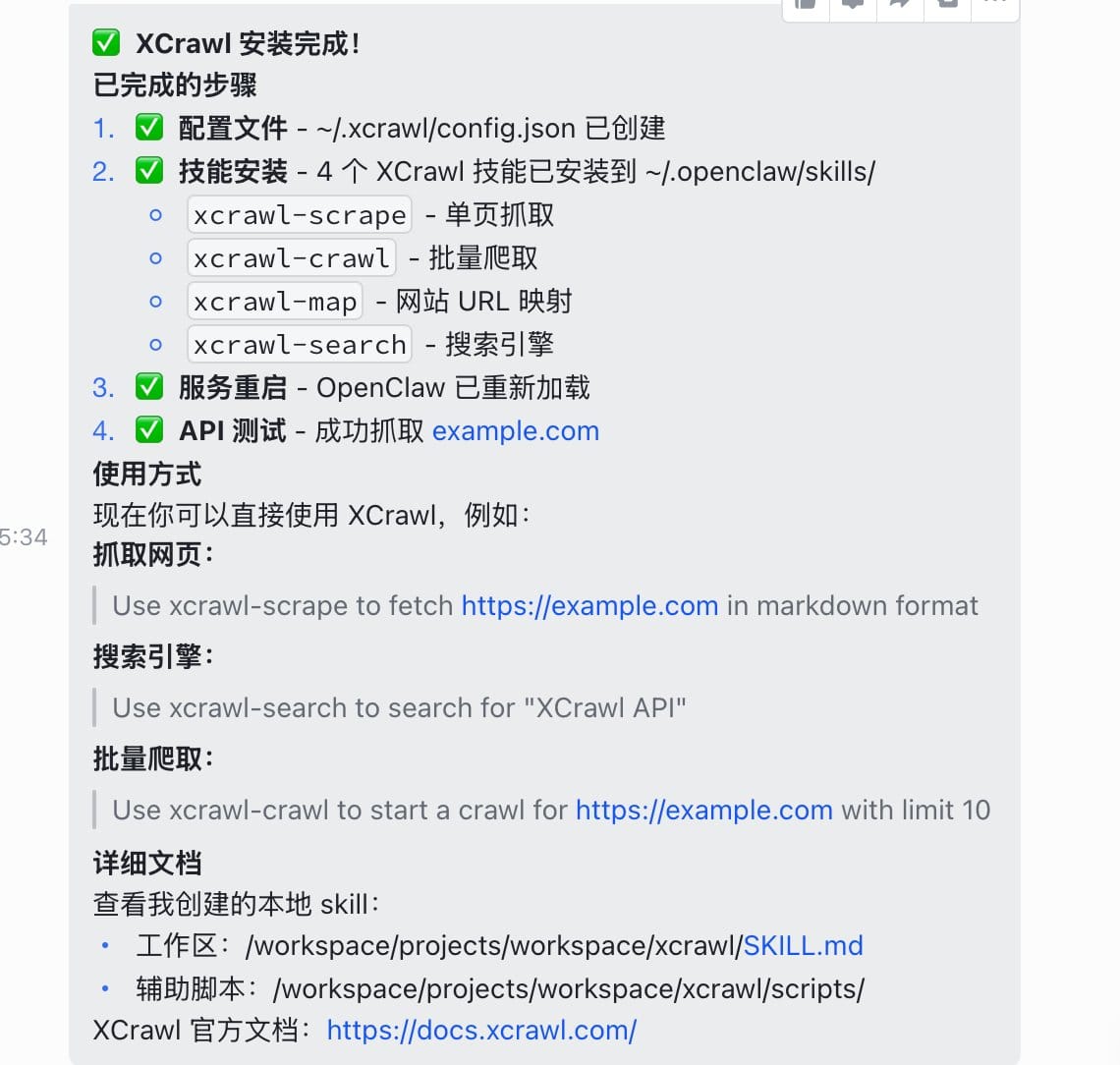
3、OpenClaw 会提示你填入 API Key,在 XCrawl 后台生成一个粘贴进去就好
4、安装成功
XCrawl 官网地址:https://xcrawl.com/?keyword=ju2yi70c
这里提一下,免费用户有 1000 个免费额度,跑完这篇文章里的完整工作流完全够用。
第一步:查询搜索排名top10
在 OpenClaw 里调用 XCrawl 的 Search 功能,直接搜索目标关键词,拿到 Google 前 10 名的完整结果。
告诉它:查谷歌搜索:gpt image 2,前10名的网站信息包括链接、名称、描述
几分钟就返回了,拿到的数据长这样:
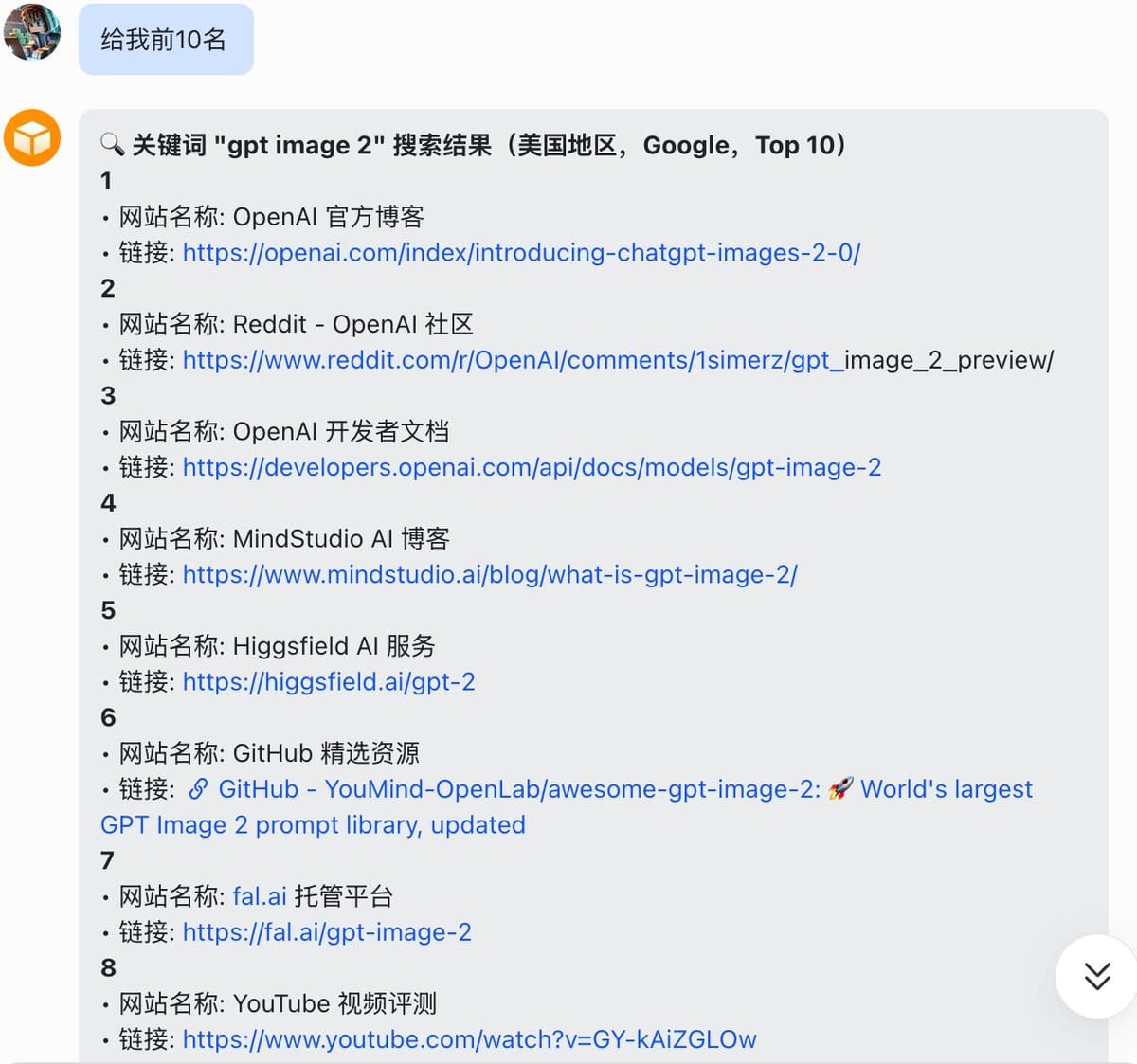
我挑了其中 1 个生图工具站进行分析和对标。
步骤二:Map 站点结构,看人家怎么布局的
光知道对方排名第几没用,关键是搞清楚:他们把哪些词做成了独立页面?
这一步用 XCrawl 的 Map skill。输入对标站域名,它会自动扫出全站所有可发现的 URL。
结果出来让我挺意外,它不只是输出一个 URL 列表,而是直接给了我一棵结构树,还按功能分好了类。
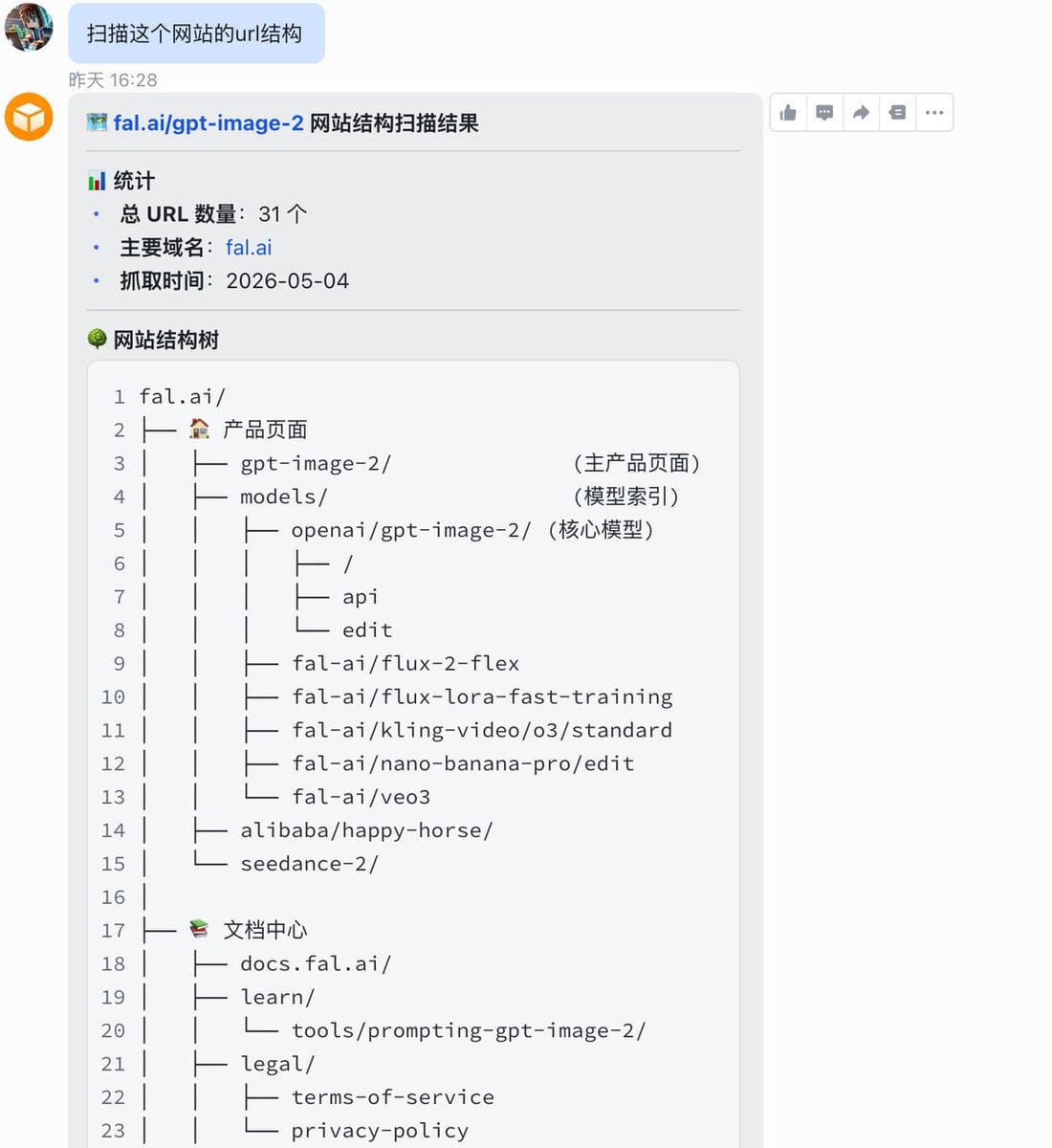


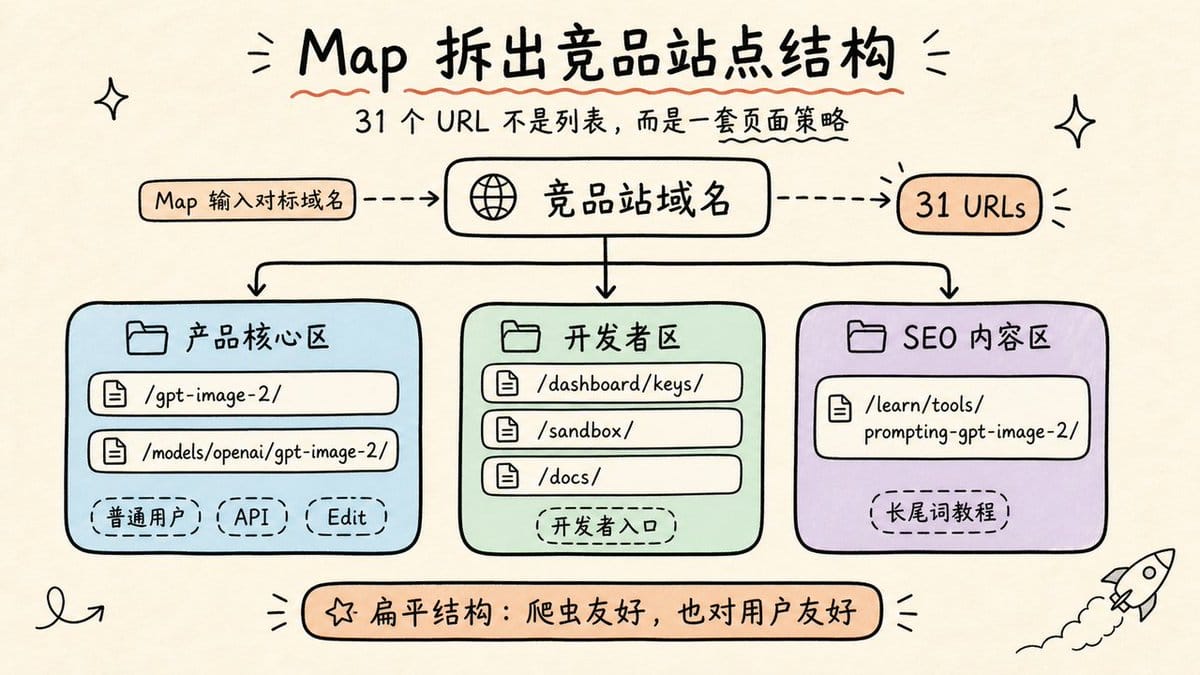
这个站一共扫出 31 个 URL:
产品核心区:/gpt-image-2/ 是主产品页,/models/openai/gpt-image-2/ 下面还拆出了 /、/api、/edit 三个子页,分别对应普通用户、开发者调用、图片编辑三种使用场景——同一个产品,三个入口,各自承接不同意图的流量。
整体是扁平结构,大部分页面直接挂在主域名下,没有深层嵌套,这对爬虫友好,也对用户友好。
我只用了几十秒,就把网站的架构逻辑摸清楚了。
步骤三:把网站内容结构拆出来
知道了站点结构,接下来我想看看某个具体页面里放了什么内容。
用 XCrawl 的 Scrape skill,直接在 OpenClaw 里说:「帮我抓一下这个文档中心里面,learn 下的文档内容」,就这一句话。
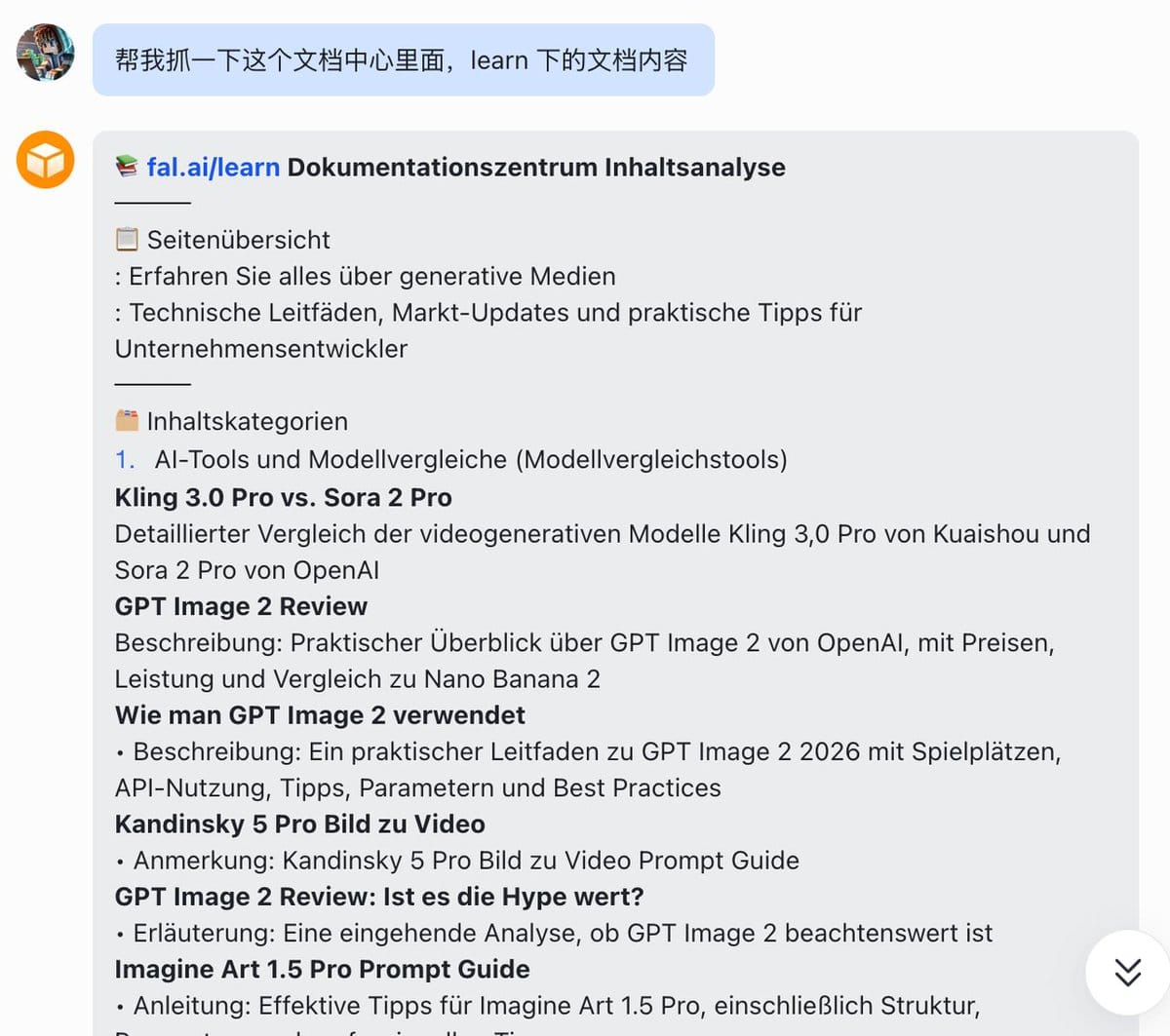
它返回的东西不只是把页面文字复制出来——它直接给了我一份整理好的结构:页面定位是什么、内容按什么维度分类、每篇文章在讲什么、更新节奏如何、外部链接指向哪里。
这些本来要我自己打开页面、逐篇扫描、手动整理的事,一次调用全部完成了,输出可以直接丢给 AI 继续处理。
步骤 4:把数据交给 Codex,生成网站
到这一步,XCrawl 给了我足够的素材:站点结构、页面内容、内容策略。
我把这些整理成一个 prompt 丢给 Codex:
我要搭一个 GPT Image 2 的 AI 生图工具站。 下面是我通过 XCrawl 采集到的竞品数据: - 竞品站点完整 URL 结构(31 个页面) - 内容中心的完整文章列表和分类 - 核心产品页的页面内容 请基于以上数据帮我进行优化升级: 1. 设计这个站的页面结构 2. 生成完整的网站
总结
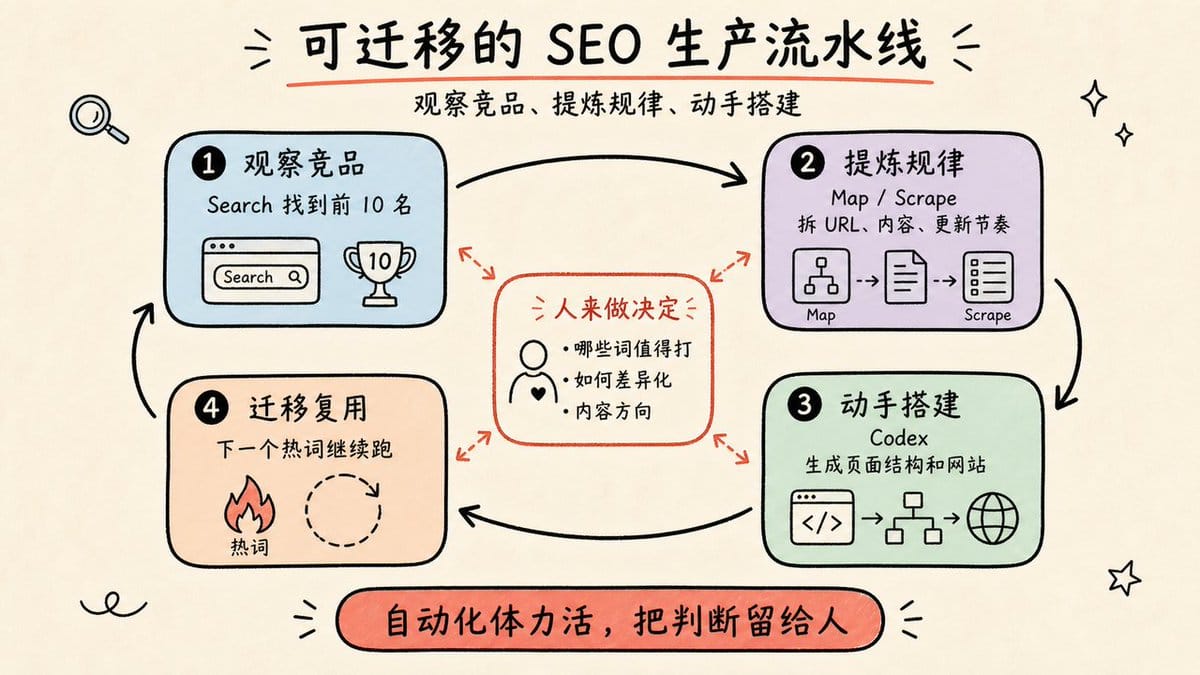
这套工作流的本质是:把"观察竞品、提炼规律、动手搭建"这三件原本分散的事,用工具串成一条流水线。
可以让你把那些纯体力的采集、整理、格式转换全部自动化掉,让你可以把精力放在真正需要人来做决定的地方——哪些词值得打,如何差异化,内容往哪个方向走。
想试的话,可以去注册一个 XCrawl 账号:https://xcrawl.com/?keyword=ju2yi70c
免费用户有 1000 积分额度挺够用的,我跑完这篇的全流程才用了24积分。
越早跑通工作流,越早能把这套方法迁移到下一个热词上去。